 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-mixed LLM: Improve Large Language Models' Capability to Handle Code-Mixing through Reinforcement Learning from AI Feedback
Nov 13, 2024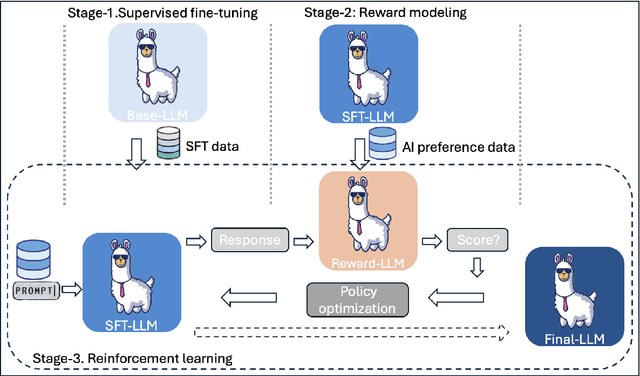

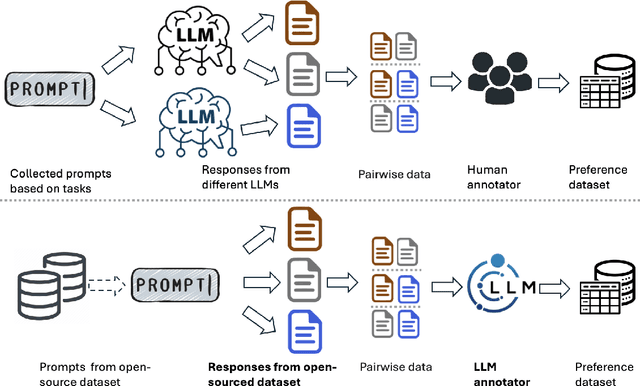
Code-mixing(CM) or code-switching(CSW) refers to the juxtaposition of linguistic units from two or more languages during the conversation or sometimes even a single utterance. Code-mixing introduces unique challenges in daily life, such as syntactic mismatches and semantic blending, that are rarely encountered in monolingual settings. Large language models (LLMs) have revolutionized the field of natural language processing (NLP) by offering unprecedented capabilities in understanding human languages. However, the effectiveness of current state-of-the-art multilingual LLMs has not yet been fully explored in the CM scenario. To fill this gap, we first benchmark the performance of multilingual LLMs on various code-mixing NLP tasks. Then we propose to improve the multilingual LLMs' ability to understand code-mixing through reinforcement learning from human feedback (RLHF) and code-mixed machine translation tasks. Given the high-cost and time-consuming preference labeling procedure, we improve this by utilizing LLMs as annotators to perform the reinforcement learning from AI feedback (RLAIF). The experiments show the effectiveness of the proposed method.