 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Taxonomy of Rater Disagreements: Surveying Challenges & Opportunities from the Perspective of Annotating Online Toxicity
Nov 07, 2023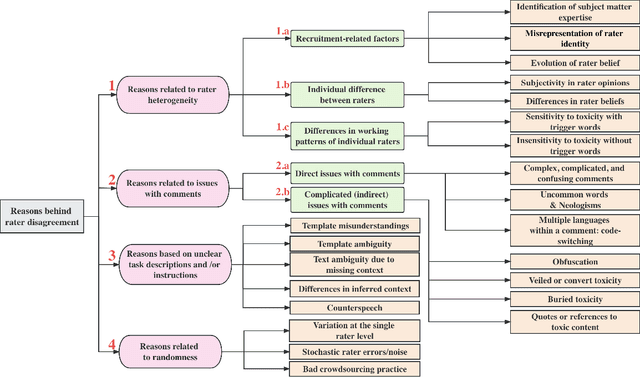
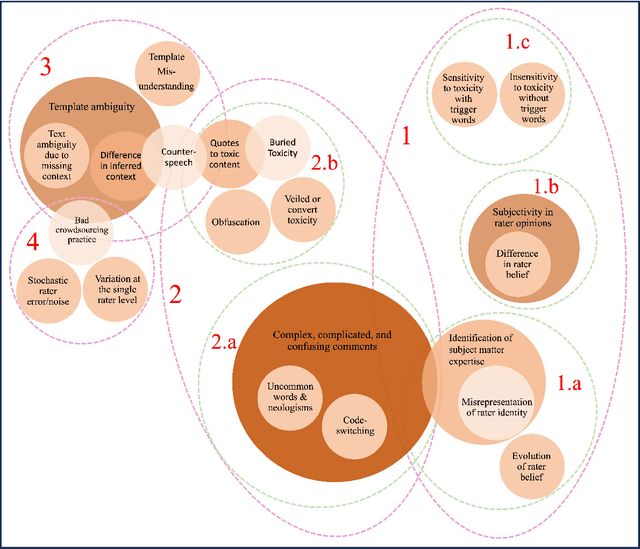
Toxicity is an increasingly common and severe issue in online spaces. Consequently, a rich line of machine learning research over the past decade has focused on computationally detecting and mitigating online toxicity. These efforts crucially rely on human-annotated datasets that identify toxic content of various kinds in social media texts. However, such annotations historically yield low inter-rater agreement, which was often dealt with by taking the majority vote or other such approaches to arrive at a single ground truth label. Recent research has pointed out the importance of accounting for the subjective nature of this task when building and utilizing these datasets, and this has triggered work on analyzing and better understanding rater disagreements, and how they could be effectively incorporated into the machine learning developmental pipeline. While these efforts are filling an important gap, there is a lack of a broader framework about the root causes of rater disagreement, and therefore, we situate this work within that broader landscape. In this survey paper, we analyze a broad set of literature on the reasons behind rater disagreements focusing on online toxicity, and propose a detailed taxonomy for the same. Further, we summarize and discuss the potential solutions targeting each reason for disagreement. We also discuss several open issues, which could promote the future development of online toxicity research.