 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlug, Play, and Fuse: Zero-Shot Joint Decoding via Word-Level Re-ranking Across Diverse Vocabularies
Paper and Code
Aug 21, 2024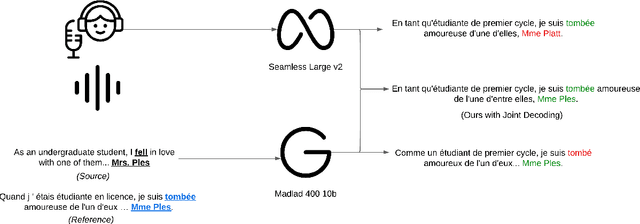
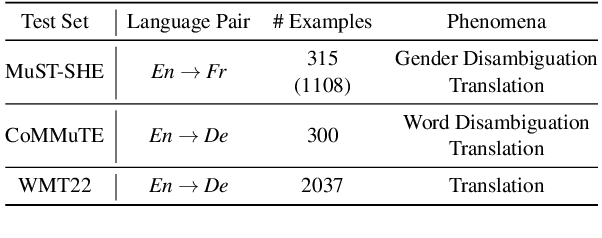
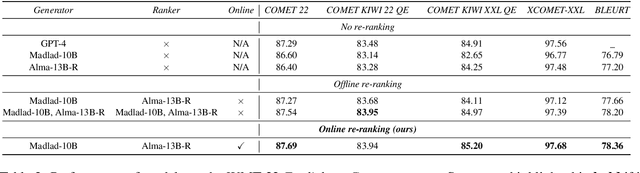
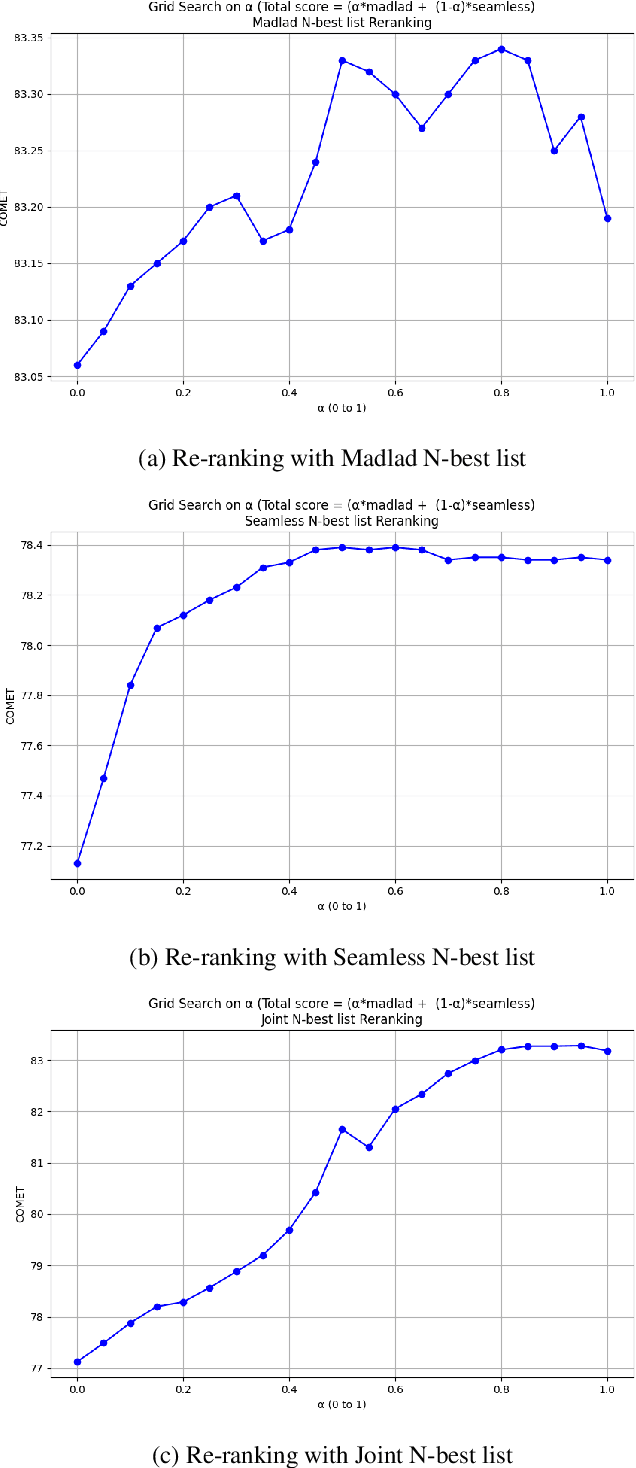
Recent advancements in NLP have resulted in models with specialized strengths, such as processing multimodal inputs or excelling in specific domains. However, real-world tasks, like multimodal translation, often require a combination of these strengths, such as handling both translation and image processing. While individual translation and vision models are powerful, they typically lack the ability to perform both tasks in a single system. Combining these models poses challenges, particularly due to differences in their vocabularies, which limit the effectiveness of traditional ensemble methods to post-generation techniques like N-best list re-ranking. In this work, we propose a novel zero-shot ensembling strategy that allows for the integration of different models during the decoding phase without the need for additional training. Our approach re-ranks beams during decoding by combining scores at the word level, using heuristics to predict when a word is completed. We demonstrate the effectiveness of this method in machine translation scenarios, showing that it enables the generation of translations that are both speech- and image-aware while also improving overall translation quality\footnote{We will release the code upon paper acceptance.}.