 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSROBB: Targeted Perceptual Loss for Single Image Super-Resolution
Aug 20, 2019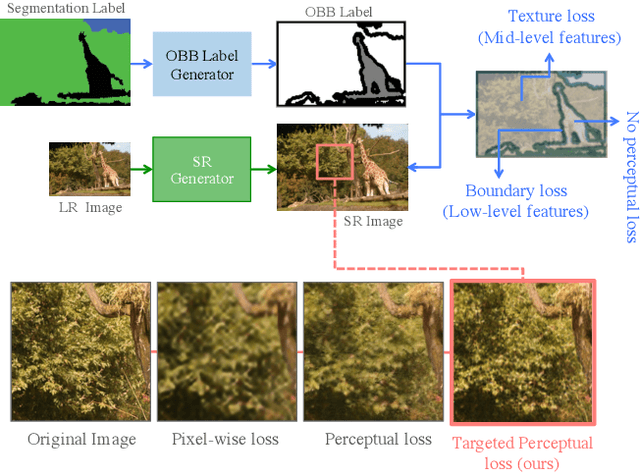
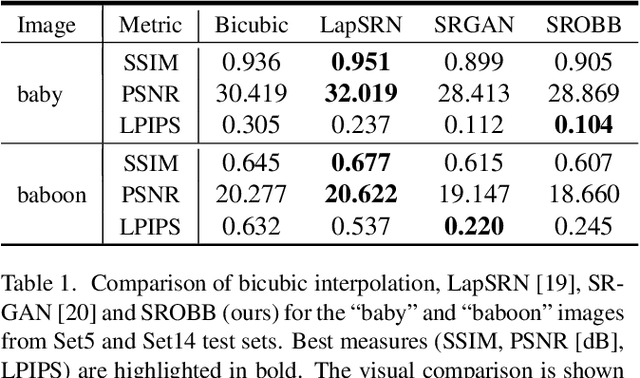

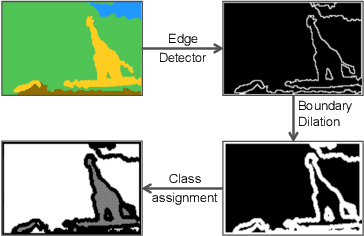
By benefiting from perceptual losses, recent studies have improved significantly the performance of the super-resolution task, where a high-resolution image is resolved from its low-resolution counterpart. Although such objective functions generate near-photorealistic results, their capability is limited, since they estimate the reconstruction error for an entire image in the same way, without considering any semantic information. In this paper, we propose a novel method to benefit from perceptual loss in a more objective way. We optimize a deep network-based decoder with a targeted objective function that penalizes images at different semantic levels using the corresponding terms. In particular, the proposed method leverages our proposed OBB (Object, Background and Boundary) labels, generated from segmentation labels, to estimate a suitable perceptual loss for boundaries, while considering texture similarity for backgrounds. We show that our proposed approach results in more realistic textures and sharper edges, and outperforms other state-of-the-art algorithms in terms of both qualitative results on standard benchmarks and results of extensive user studies.
Benefiting from Multitask Learning to Improve Single Image Super-Resolution
Jul 29, 2019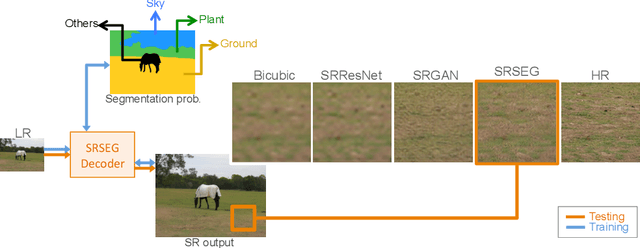
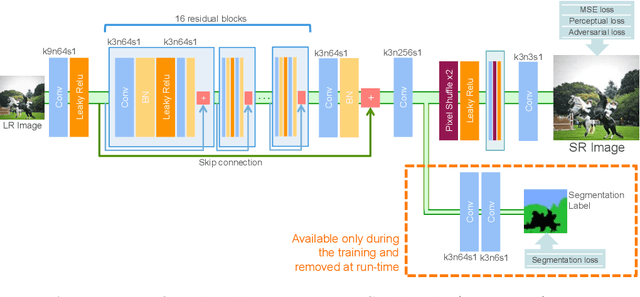
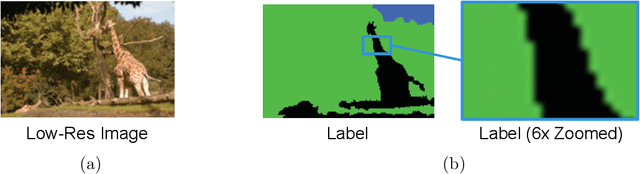
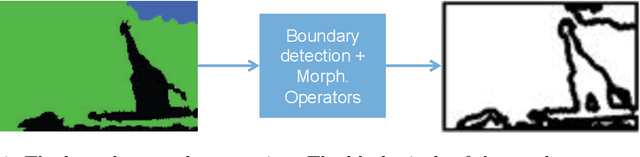
Despite significant progress toward super resolving more realistic images by deeper convolutional neural networks (CNNs), reconstructing fine and natural textures still remains a challenging problem. Recent works on single image super resolution (SISR) are mostly based on optimizing pixel and content wise similarity between recovered and high-resolution (HR) images and do not benefit from recognizability of semantic classes. In this paper, we introduce a novel approach using categorical information to tackle the SISR problem; we present a decoder architecture able to extract and use semantic information to super-resolve a given image by using multitask learning, simultaneously for image super-resolution and semantic segmentation. To explore categorical information during training, the proposed decoder only employs one shared deep network for two task-specific output layers. At run-time only layers resulting HR image are used and no segmentation label is required. Extensive perceptual experiments and a user study on images randomly selected from COCO-Stuff dataset demonstrate the effectiveness of our proposed method and it outperforms the state-of-the-art methods.