 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Generative Style Transfer for One-Shot Medical Image Segmentation
Oct 05, 2021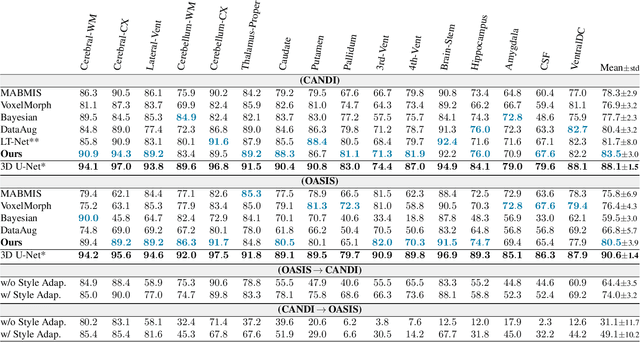
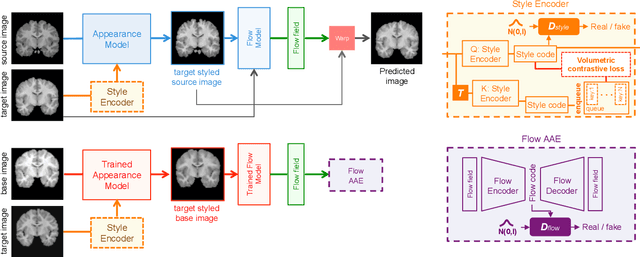
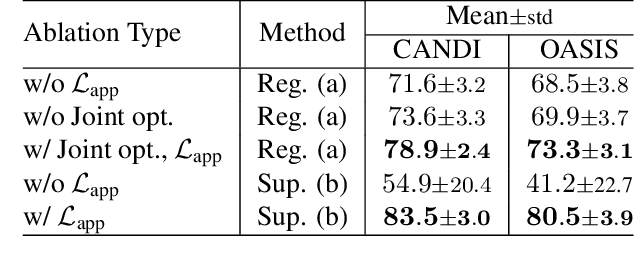
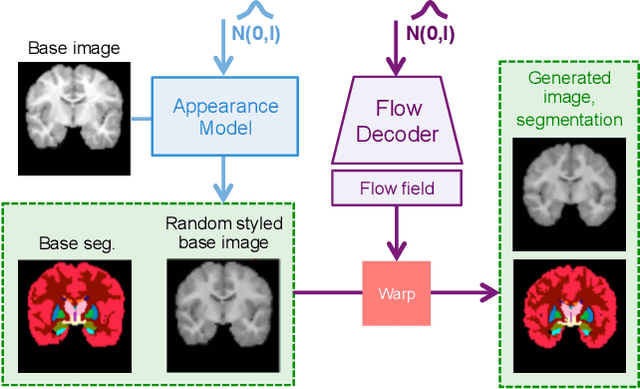
In medical image segmentation, supervised deep networks' success comes at the cost of requiring abundant labeled data. While asking domain experts to annotate only one or a few of the cohort's images is feasible, annotating all available images is impractical. This issue is further exacerbated when pre-trained deep networks are exposed to a new image dataset from an unfamiliar distribution. Using available open-source data for ad-hoc transfer learning or hand-tuned techniques for data augmentation only provides suboptimal solutions. Motivated by atlas-based segmentation, we propose a novel volumetric self-supervised learning for data augmentation capable of synthesizing volumetric image-segmentation pairs via learning transformations from a single labeled atlas to the unlabeled data. Our work's central tenet benefits from a combined view of one-shot generative learning and the proposed self-supervised training strategy that cluster unlabeled volumetric images with similar styles together. Unlike previous methods, our method does not require input volumes at inference time to synthesize new images. Instead, it can generate diversified volumetric image-segmentation pairs from a prior distribution given a single or multi-site dataset. Augmented data generated by our method used to train the segmentation network provide significant improvements over state-of-the-art deep one-shot learning methods on the task of brain MRI segmentation. Ablation studies further exemplified that the proposed appearance model and joint training are crucial to synthesize realistic examples compared to existing medical registration methods. The code, data, and models are available at https://github.com/devavratTomar/SST.
Self-Attentive Spatial Adaptive Normalization for Cross-Modality Domain Adaptation
Mar 05, 2021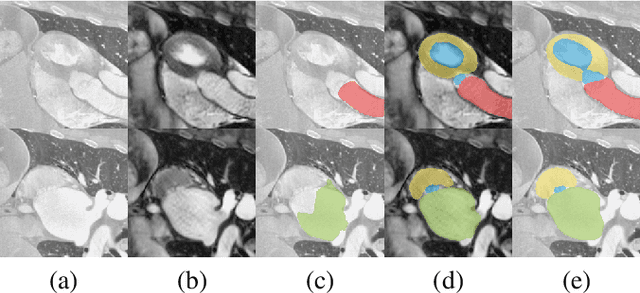
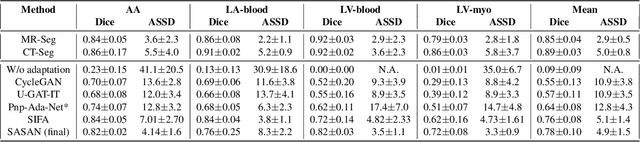
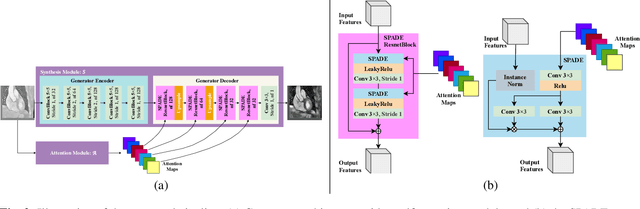
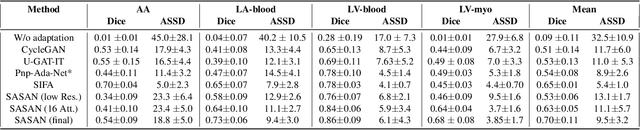
Despite the successes of deep neural networks on many challenging vision tasks, they often fail to generalize to new test domains that are not distributed identically to the training data. The domain adaptation becomes more challenging for cross-modality medical data with a notable domain shift. Given that specific annotated imaging modalities may not be accessible nor complete. Our proposed solution is based on the cross-modality synthesis of medical images to reduce the costly annotation burden by radiologists and bridge the domain gap in radiological images. We present a novel approach for image-to-image translation in medical images, capable of supervised or unsupervised (unpaired image data) setups. Built upon adversarial training, we propose a learnable self-attentive spatial normalization of the deep convolutional generator network's intermediate activations. Unlike previous attention-based image-to-image translation approaches, which are either domain-specific or require distortion of the source domain's structures, we unearth the importance of the auxiliary semantic information to handle the geometric changes and preserve anatomical structures during image translation. We achieve superior results for cross-modality segmentation between unpaired MRI and CT data for multi-modality whole heart and multi-modal brain tumor MRI (T1/T2) datasets compared to the state-of-the-art methods. We also observe encouraging results in cross-modality conversion for paired MRI and CT images on a brain dataset. Furthermore, a detailed analysis of the cross-modality image translation, thorough ablation studies confirm our proposed method's efficacy.
The Impact of Virtual Reality and Viewpoints in Body Motion Based Drone Teleoperation
Jan 30, 2021
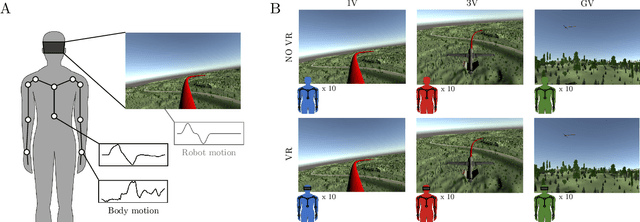

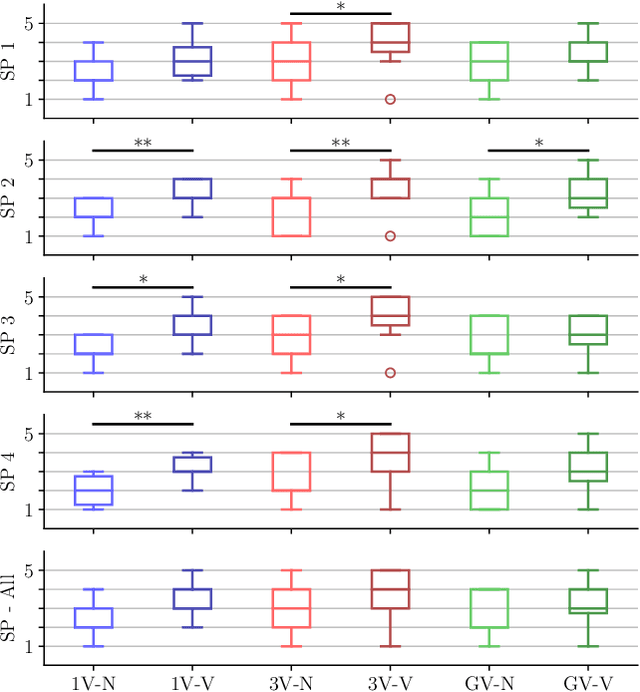
The operation of telerobotic systems can be a challenging task, requiring intuitive and efficient interfaces to enable inexperienced users to attain a high level of proficiency. Body-Machine Interfaces (BoMI) represent a promising alternative to standard control devices, such as joysticks, because they leverage intuitive body motion and gestures. It has been shown that the use of Virtual Reality (VR) and first-person view perspectives can increase the user's sense of presence in avatars. However, it is unclear if these beneficial effects occur also in the teleoperation of non-anthropomorphic robots that display motion patterns different from those of humans. Here we describe experimental results on teleoperation of a non-anthropomorphic drone showing that VR correlates with a higher sense of spatial presence, whereas viewpoints moving coherently with the robot are associated with a higher sense of embodiment. Furthermore, the experimental results show that spontaneous body motion patterns are affected by VR and viewpoint conditions in terms of variability, amplitude, and robot correlates, suggesting that the design of BoMIs for drone teleoperation must take into account the use of Virtual Reality and the choice of the viewpoint.