 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Attentive Spatial Adaptive Normalization for Cross-Modality Domain Adaptation
Paper and Code
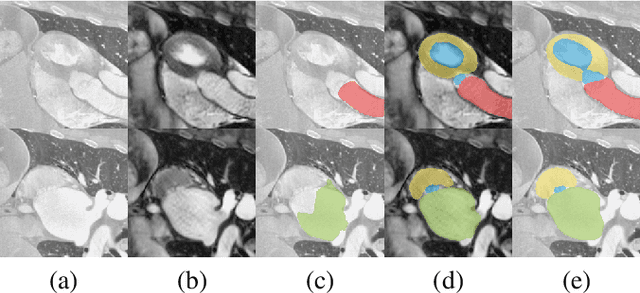
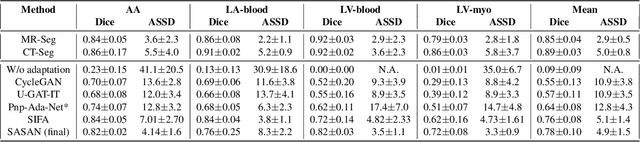
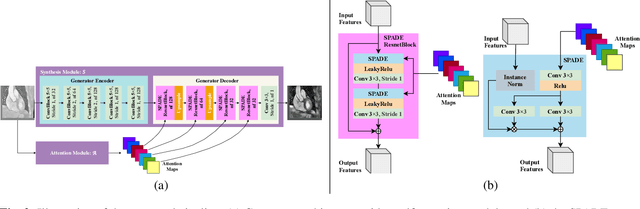
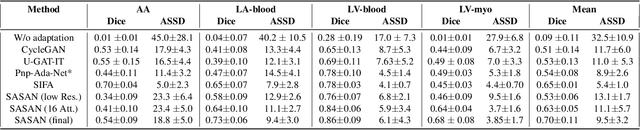
Despite the successes of deep neural networks on many challenging vision tasks, they often fail to generalize to new test domains that are not distributed identically to the training data. The domain adaptation becomes more challenging for cross-modality medical data with a notable domain shift. Given that specific annotated imaging modalities may not be accessible nor complete. Our proposed solution is based on the cross-modality synthesis of medical images to reduce the costly annotation burden by radiologists and bridge the domain gap in radiological images. We present a novel approach for image-to-image translation in medical images, capable of supervised or unsupervised (unpaired image data) setups. Built upon adversarial training, we propose a learnable self-attentive spatial normalization of the deep convolutional generator network's intermediate activations. Unlike previous attention-based image-to-image translation approaches, which are either domain-specific or require distortion of the source domain's structures, we unearth the importance of the auxiliary semantic information to handle the geometric changes and preserve anatomical structures during image translation. We achieve superior results for cross-modality segmentation between unpaired MRI and CT data for multi-modality whole heart and multi-modal brain tumor MRI (T1/T2) datasets compared to the state-of-the-art methods. We also observe encouraging results in cross-modality conversion for paired MRI and CT images on a brain dataset. Furthermore, a detailed analysis of the cross-modality image translation, thorough ablation studies confirm our proposed method's efficacy.