 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFILP-3D: Enhancing 3D Few-shot Class-incremental Learning with Pre-trained Vision-Language Models
Dec 28, 2023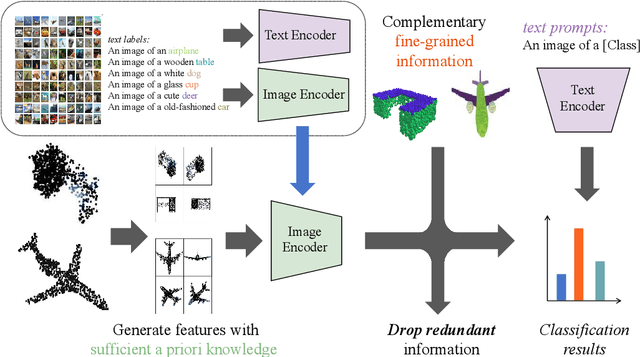

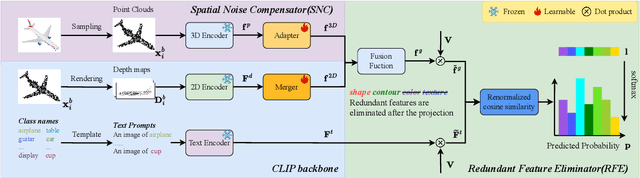
Few-shot class-incremental learning (FSCIL) aims to mitigate the catastrophic forgetting issue when a model is incrementally trained on limited data. While the Contrastive Vision-Language Pre-Training (CLIP) model has been effective in addressing 2D few/zero-shot learning tasks, its direct application to 3D FSCIL faces limitations. These limitations arise from feature space misalignment and significant noise in real-world scanned 3D data. To address these challenges, we introduce two novel components: the Redundant Feature Eliminator (RFE) and the Spatial Noise Compensator (SNC). RFE aligns the feature spaces of input point clouds and their embeddings by performing a unique dimensionality reduction on the feature space of pre-trained models (PTMs), effectively eliminating redundant information without compromising semantic integrity. On the other hand, SNC is a graph-based 3D model designed to capture robust geometric information within point clouds, thereby augmenting the knowledge lost due to projection, particularly when processing real-world scanned data. Considering the imbalance in existing 3D datasets, we also propose new evaluation metrics that offer a more nuanced assessment of a 3D FSCIL model. Traditional accuracy metrics are proved to be biased; thus, our metrics focus on the model's proficiency in learning new classes while maintaining the balance between old and new classes. Experimental results on both established 3D FSCIL benchmarks and our dataset demonstrate that our approach significantly outperforms existing state-of-the-art methods.
DreamControl: Control-Based Text-to-3D Generation with 3D Self-Prior
Dec 11, 20233D generation has raised great attention in recent years. With the success of text-to-image diffusion models, the 2D-lifting technique becomes a promising route to controllable 3D generation. However, these methods tend to present inconsistent geometry, which is also known as the Janus problem. We observe that the problem is caused mainly by two aspects, i.e., viewpoint bias in 2D diffusion models and overfitting of the optimization objective. To address it, we propose a two-stage 2D-lifting framework, namely DreamControl, which optimizes coarse NeRF scenes as 3D self-prior and then generates fine-grained objects with control-based score distillation. Specifically, adaptive viewpoint sampling and boundary integrity metric are proposed to ensure the consistency of generated priors. The priors are then regarded as input conditions to maintain reasonable geometries, in which conditional LoRA and weighted score are further proposed to optimize detailed textures. DreamControl can generate high-quality 3D content in terms of both geometry consistency and texture fidelity. Moreover, our control-based optimization guidance is applicable to more downstream tasks, including user-guided generation and 3D animation. The project page is available at https://github.com/tyhuang0428/DreamControl.