 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecreasing scaling transition from adaptive gradient descent to stochastic gradient descent
Paper and Code
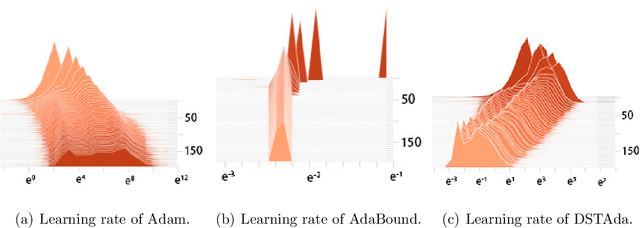

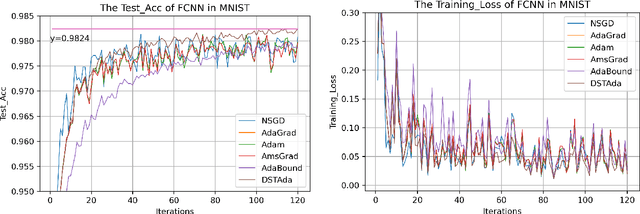

Currently, researchers have proposed the adaptive gradient descent algorithm and its variants, such as AdaGrad, RMSProp, Adam, AmsGrad, etc. Although these algorithms have a faster speed in the early stage, the generalization ability in the later stage of training is often not as good as the stochastic gradient descent. Recently, some researchers have combined the adaptive gradient descent and stochastic gradient descent to obtain the advantages of both and achieved good results. Based on this research, we propose a decreasing scaling transition from adaptive gradient descent to stochastic gradient descent method(DSTAda). For the training stage of the stochastic gradient descent, we use a learning rate that decreases linearly with the number of iterations instead of a constant learning rate. We achieve a smooth and stable transition from adaptive gradient descent to stochastic gradient descent through scaling. At the same time, we give a theoretical proof of the convergence of DSTAda under the framework of online learning. Our experimental results show that the DSTAda algorithm has a faster convergence speed, higher accuracy, and better stability and robustness. Our implementation is available at: https://github.com/kunzeng/DSTAdam.