 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedNet: Residual Encoder-Decoder Network for indoor RGB-D Semantic Segmentation
Aug 06, 2018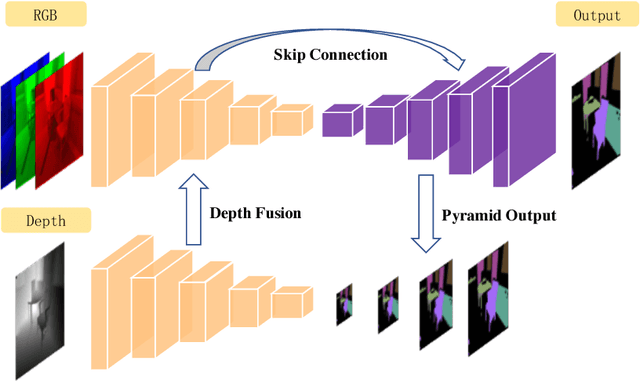
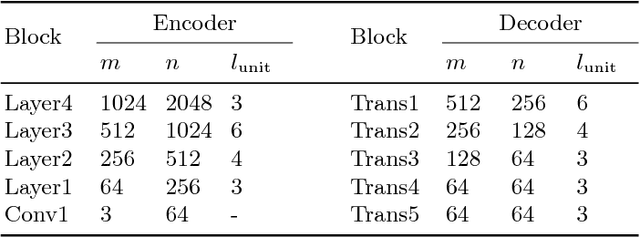
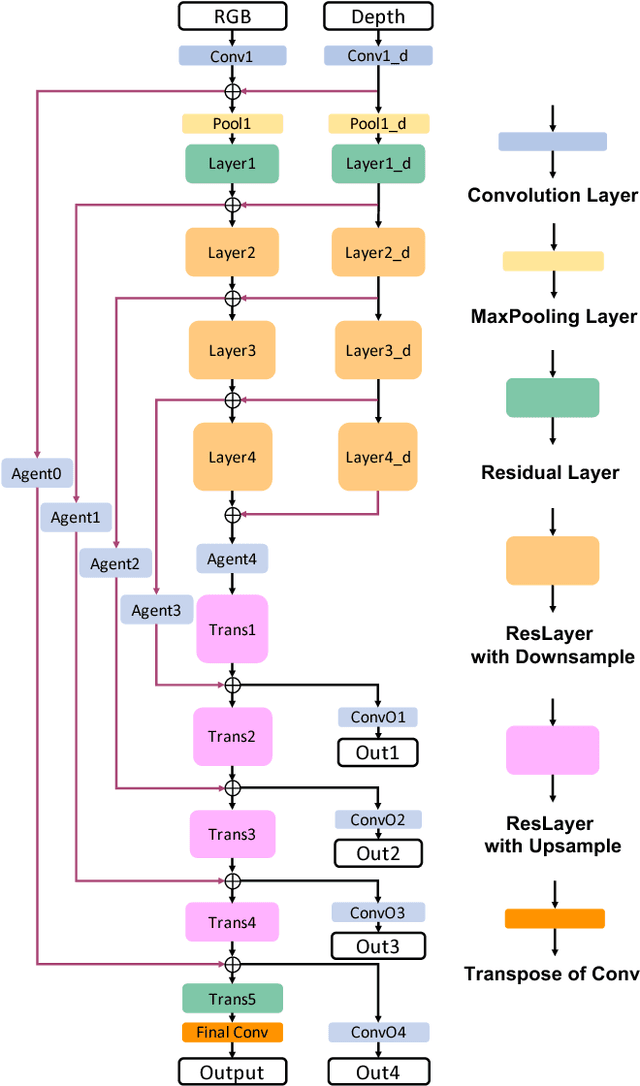
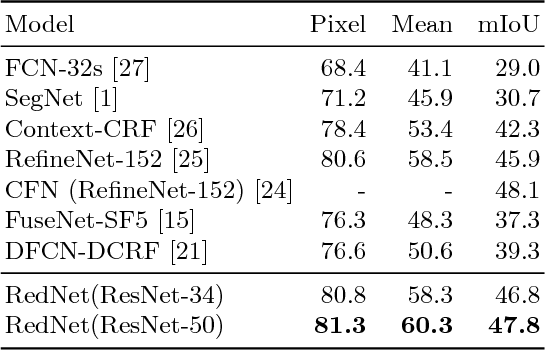
Indoor semantic segmentation has always been a difficult task in computer vision. In this paper, we propose an RGB-D residual encoder-decoder architecture, named RedNet, for indoor RGB-D semantic segmentation. In RedNet, the residual module is applied to both the encoder and decoder as the basic building block, and the skip-connection is used to bypass the spatial feature between the encoder and decoder. In order to incorporate the depth information of the scene, a fusion structure is constructed, which makes inference on RGB image and depth image separately, and fuses their features over several layers. In order to efficiently optimize the network's parameters, we propose a `pyramid supervision' training scheme, which applies supervised learning over different layers in the decoder, to cope with the problem of gradients vanishing. Experiment results show that the proposed RedNet(ResNet-50) achieves a state-of-the-art mIoU accuracy of 47.8% on the SUN RGB-D benchmark dataset.
Incorporating Depth into both CNN and CRF for Indoor Semantic Segmentation
Jul 27, 2018

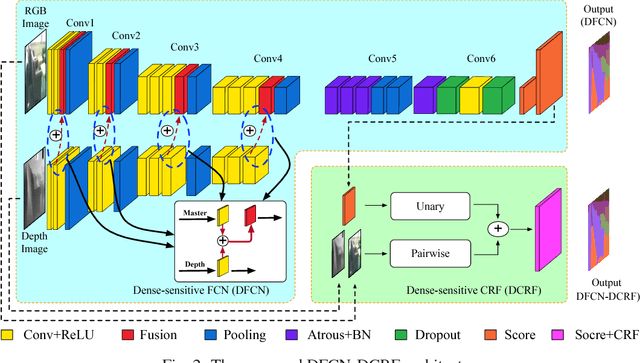
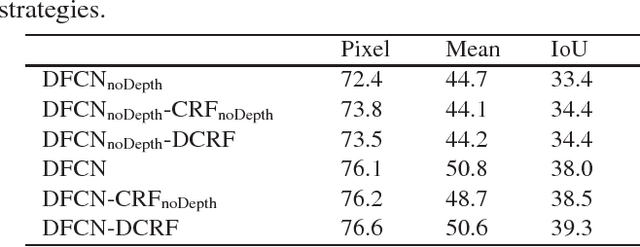
To improve segmentation performance, a novel neural network architecture (termed DFCN-DCRF) is proposed, which combines an RGB-D fully convolutional neural network (DFCN) with a depth-sensitive fully-connected conditional random field (DCRF). First, a DFCN architecture which fuses depth information into the early layers and applies dilated convolution for later contextual reasoning is designed. Then, a depth-sensitive fully-connected conditional random field (DCRF) is proposed and combined with the previous DFCN to refine the preliminary result. Comparative experiments show that the proposed DFCN-DCRF has the best performance compared with most state-of-the-art methods.