 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Region-Shrinking-Based Acceleration for Classification-Based Derivative-Free Optimization
Sep 20, 2023



Derivative-free optimization algorithms play an important role in scientific and engineering design optimization problems, especially when derivative information is not accessible. In this paper, we study the framework of classification-based derivative-free optimization algorithms. By introducing a concept called hypothesis-target shattering rate, we revisit the computational complexity upper bound of this type of algorithms. Inspired by the revisited upper bound, we propose an algorithm named "RACE-CARS", which adds a random region-shrinking step compared with "SRACOS" (Hu et al., 2017).. We further establish a theorem showing the acceleration of region-shrinking. Experiments on the synthetic functions as well as black-box tuning for language-model-as-a-service demonstrate empirically the efficiency of "RACE-CARS". An ablation experiment on the introduced hyperparameters is also conducted, revealing the mechanism of "RACE-CARS" and putting forward an empirical hyperparameter-tuning guidance.
CAIL2019-SCM: A Dataset of Similar Case Matching in Legal Domain
Nov 25, 2019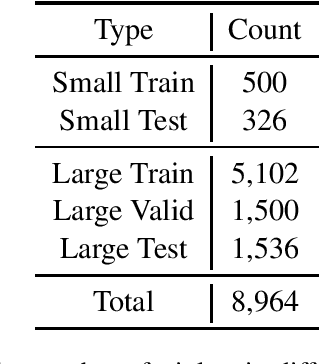
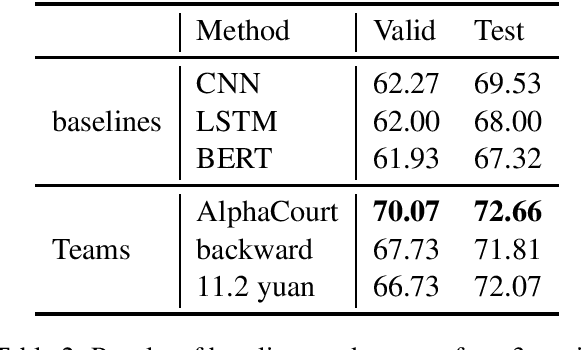
In this paper, we introduce CAIL2019-SCM, Chinese AI and Law 2019 Similar Case Matching dataset. CAIL2019-SCM contains 8,964 triplets of cases published by the Supreme People's Court of China. CAIL2019-SCM focuses on detecting similar cases, and the participants are required to check which two cases are more similar in the triplets. There are 711 teams who participated in this year's competition, and the best team has reached a score of 71.88. We have also implemented several baselines to help researchers better understand this task. The dataset and more details can be found from https://github.com/china-ai-law-challenge/CAIL2019/tree/master/scm.
Overview of CAIL2018: Legal Judgment Prediction Competition
Oct 13, 2018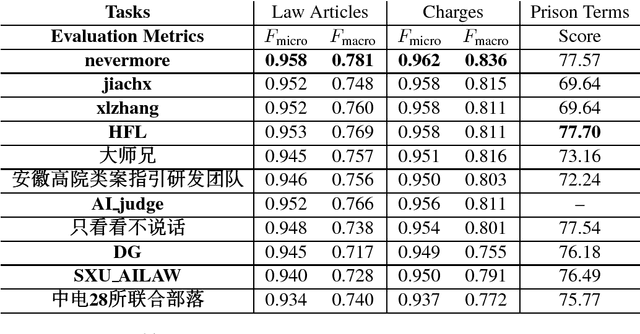
In this paper, we give an overview of the Legal Judgment Prediction (LJP) competition at Chinese AI and Law challenge (CAIL2018). This competition focuses on LJP which aims to predict the judgment results according to the given facts. Specifically, in CAIL2018 , we proposed three subtasks of LJP for the contestants, i.e., predicting relevant law articles, charges and prison terms given the fact descriptions. CAIL2018 has attracted several hundreds participants (601 teams, 1, 144 contestants from 269 organizations). In this paper, we provide a detailed overview of the task definition, related works, outstanding methods and competition results in CAIL2018.
CAIL2018: A Large-Scale Legal Dataset for Judgment Prediction
Jul 04, 2018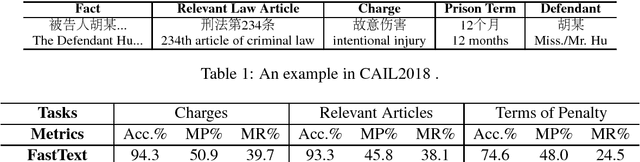
In this paper, we introduce the \textbf{C}hinese \textbf{AI} and \textbf{L}aw challenge dataset (CAIL2018), the first large-scale Chinese legal dataset for judgment prediction. \dataset contains more than $2.6$ million criminal cases published by the Supreme People's Court of China, which are several times larger than other datasets in existing works on judgment prediction. Moreover, the annotations of judgment results are more detailed and rich. It consists of applicable law articles, charges, and prison terms, which are expected to be inferred according to the fact descriptions of cases. For comparison, we implement several conventional text classification baselines for judgment prediction and experimental results show that it is still a challenge for current models to predict the judgment results of legal cases, especially on prison terms. To help the researchers make improvements on legal judgment prediction, both \dataset and baselines will be released after the CAIL competition\footnote{http://cail.cipsc.org.cn/}.