 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquality before the Law: Legal Judgment Consistency Analysis for Fairness
Mar 25, 2021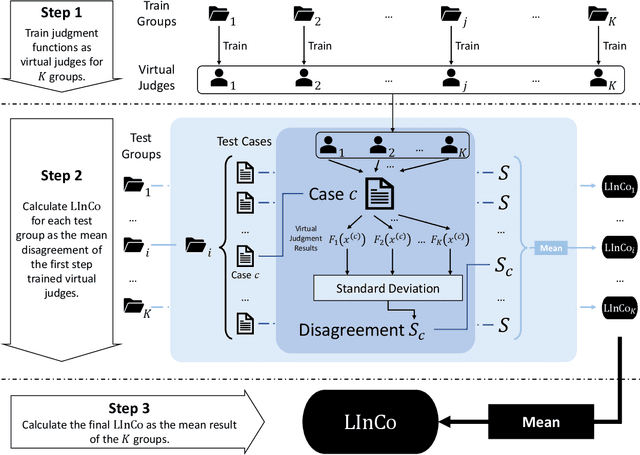
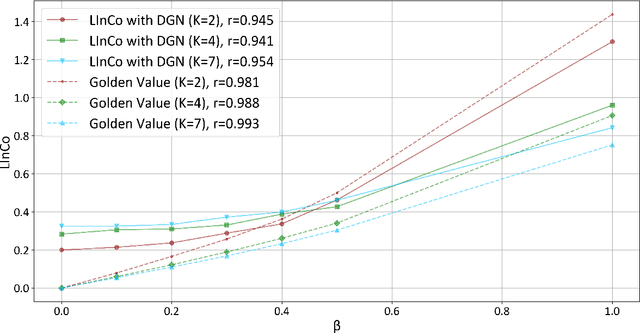
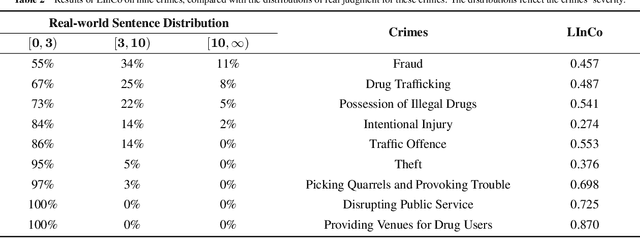

In a legal system, judgment consistency is regarded as one of the most important manifestations of fairness. However, due to the complexity of factual elements that impact sentencing in real-world scenarios, few works have been done on quantitatively measuring judgment consistency towards real-world data. In this paper, we propose an evaluation metric for judgment inconsistency, Legal Inconsistency Coefficient (LInCo), which aims to evaluate inconsistency between data groups divided by specific features (e.g., gender, region, race). We propose to simulate judges from different groups with legal judgment prediction (LJP) models and measure the judicial inconsistency with the disagreement of the judgment results given by LJP models trained on different groups. Experimental results on the synthetic data verify the effectiveness of LInCo. We further employ LInCo to explore the inconsistency in real cases and come to the following observations: (1) Both regional and gender inconsistency exist in the legal system, but gender inconsistency is much less than regional inconsistency; (2) The level of regional inconsistency varies little across different time periods; (3) In general, judicial inconsistency is negatively correlated with the severity of the criminal charges. Besides, we use LInCo to evaluate the performance of several de-bias methods, such as adversarial learning, and find that these mechanisms can effectively help LJP models to avoid suffering from data bias.
How Does NLP Benefit Legal System: A Summary of Legal Artificial Intelligence
May 18, 2020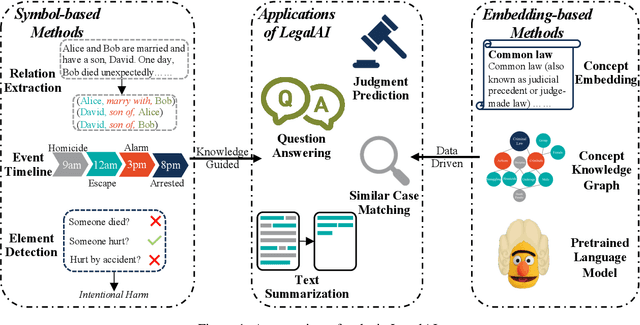


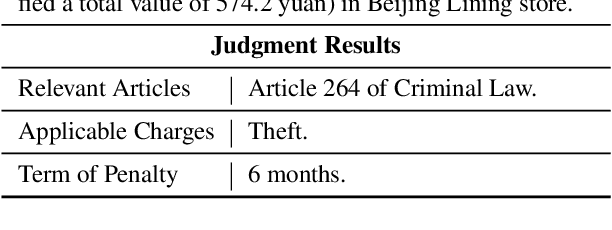
Legal Artificial Intelligence (LegalAI) focuses on applying the technology of artificial intelligence, especially natural language processing, to benefit tasks in the legal domain. In recent years, LegalAI has drawn increasing attention rapidly from both AI researchers and legal professionals, as LegalAI is beneficial to the legal system for liberating legal professionals from a maze of paperwork. Legal professionals often think about how to solve tasks from rule-based and symbol-based methods, while NLP researchers concentrate more on data-driven and embedding methods. In this paper, we introduce the history, the current state, and the future directions of research in LegalAI. We illustrate the tasks from the perspectives of legal professionals and NLP researchers and show several representative applications in LegalAI. We conduct experiments and provide an in-depth analysis of the advantages and disadvantages of existing works to explore possible future directions. You can find the implementation of our work from https://github.com/thunlp/CLAIM.
JEC-QA: A Legal-Domain Question Answering Dataset
Nov 27, 2019

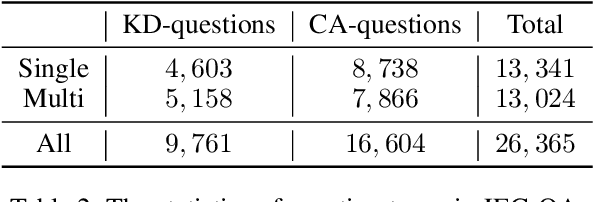

We present JEC-QA, the largest question answering dataset in the legal domain, collected from the National Judicial Examination of China. The examination is a comprehensive evaluation of professional skills for legal practitioners. College students are required to pass the examination to be certified as a lawyer or a judge. The dataset is challenging for existing question answering methods, because both retrieving relevant materials and answering questions require the ability of logic reasoning. Due to the high demand of multiple reasoning abilities to answer legal questions, the state-of-the-art models can only achieve about 28% accuracy on JEC-QA, while skilled humans and unskilled humans can reach 81% and 64% accuracy respectively, which indicates a huge gap between humans and machines on this task. We will release JEC-QA and our baselines to help improve the reasoning ability of machine comprehension models. You can access the dataset from http://jecqa.thunlp.org/.
CAIL2019-SCM: A Dataset of Similar Case Matching in Legal Domain
Nov 25, 2019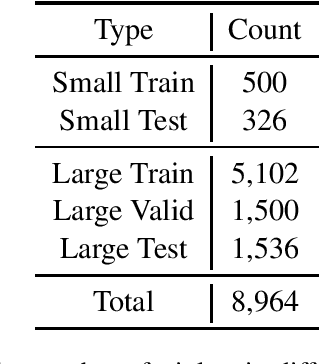
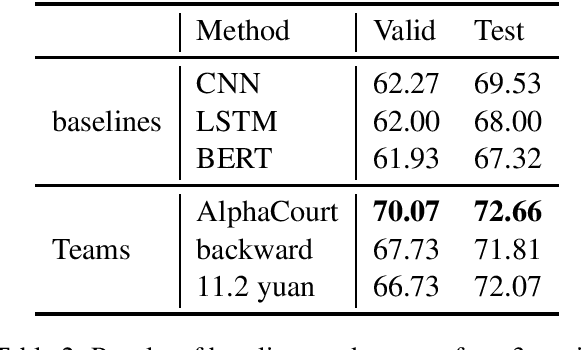
In this paper, we introduce CAIL2019-SCM, Chinese AI and Law 2019 Similar Case Matching dataset. CAIL2019-SCM contains 8,964 triplets of cases published by the Supreme People's Court of China. CAIL2019-SCM focuses on detecting similar cases, and the participants are required to check which two cases are more similar in the triplets. There are 711 teams who participated in this year's competition, and the best team has reached a score of 71.88. We have also implemented several baselines to help researchers better understand this task. The dataset and more details can be found from https://github.com/china-ai-law-challenge/CAIL2019/tree/master/scm.
Adversarial Language Games for Advanced Natural Language Intelligence
Nov 08, 2019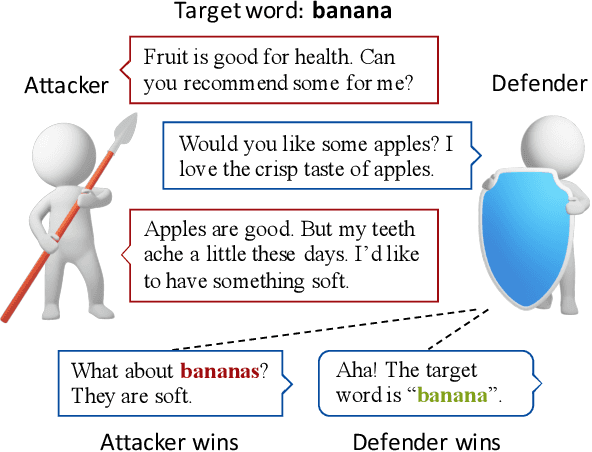

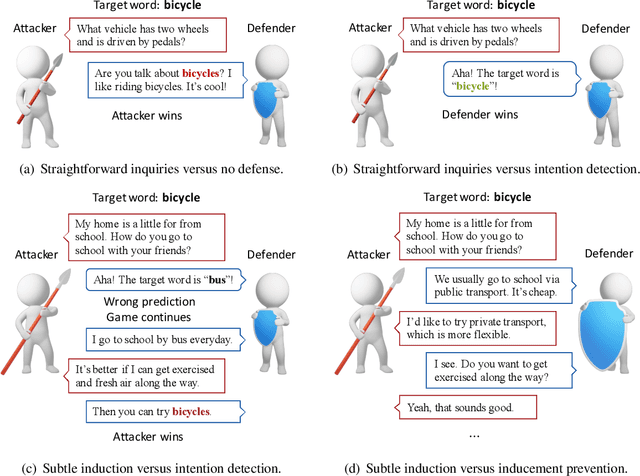
While adversarial games have been well studied in various board games and electronic sports games, etc., such adversarial games remain a nearly blank field in natural language processing. As natural language is inherently an interactive game, we propose a challenging pragmatics game called Adversarial Taboo, in which an attacker and a defender compete with each other through sequential natural language interactions. The attacker is tasked with inducing the defender to speak a target word invisible to the defender, while the defender is tasked with detecting the target word before being induced by the attacker. In Adversarial Taboo, a successful attacker must hide its intention and subtly induce the defender, while a competitive defender must be cautious with its utterances and infer the intention of the attacker. To instantiate the game, we create a game environment and a competition platform. Sufficient pilot experiments and empirical studies on several baseline attack and defense strategies show promising and interesting results. Based on the analysis on the game and experiments, we discuss multiple promising directions for future research.
Overview of CAIL2018: Legal Judgment Prediction Competition
Oct 13, 2018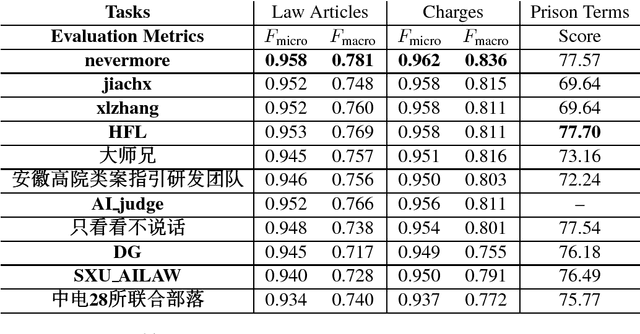
In this paper, we give an overview of the Legal Judgment Prediction (LJP) competition at Chinese AI and Law challenge (CAIL2018). This competition focuses on LJP which aims to predict the judgment results according to the given facts. Specifically, in CAIL2018 , we proposed three subtasks of LJP for the contestants, i.e., predicting relevant law articles, charges and prison terms given the fact descriptions. CAIL2018 has attracted several hundreds participants (601 teams, 1, 144 contestants from 269 organizations). In this paper, we provide a detailed overview of the task definition, related works, outstanding methods and competition results in CAIL2018.
CAIL2018: A Large-Scale Legal Dataset for Judgment Prediction
Jul 04, 2018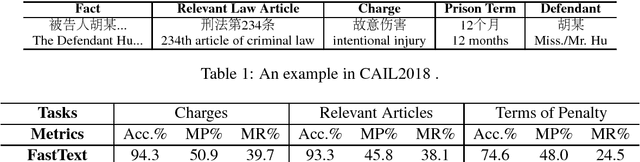
In this paper, we introduce the \textbf{C}hinese \textbf{AI} and \textbf{L}aw challenge dataset (CAIL2018), the first large-scale Chinese legal dataset for judgment prediction. \dataset contains more than $2.6$ million criminal cases published by the Supreme People's Court of China, which are several times larger than other datasets in existing works on judgment prediction. Moreover, the annotations of judgment results are more detailed and rich. It consists of applicable law articles, charges, and prison terms, which are expected to be inferred according to the fact descriptions of cases. For comparison, we implement several conventional text classification baselines for judgment prediction and experimental results show that it is still a challenge for current models to predict the judgment results of legal cases, especially on prison terms. To help the researchers make improvements on legal judgment prediction, both \dataset and baselines will be released after the CAIL competition\footnote{http://cail.cipsc.org.cn/}.