 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruncated Back-propagation for Bilevel Optimization
Paper and Code

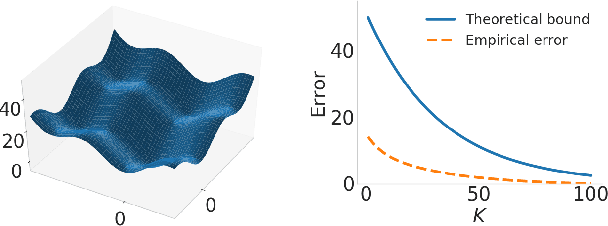
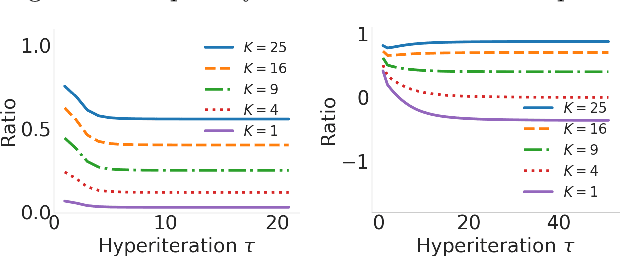

Bilevel optimization has been recently revisited for designing and analyzing algorithms in hyperparameter tuning and meta learning tasks. However, due to its nested structure, evaluating exact gradients for high-dimensional problems is computationally challenging. One heuristic to circumvent this difficulty is to use the approximate gradient given by performing truncated back-propagation through the iterative optimization procedure that solves the lower-level problem. Although promising empirical performance has been reported, its theoretical properties are still unclear. In this paper, we analyze the properties of this family of approximate gradients and establish sufficient conditions for convergence. We validate this on several hyperparameter tuning and meta learning tasks. We find that optimization with the approximate gradient computed using few-step back-propagation often performs comparably to optimization with the exact gradient, while requiring far less memory and half the computation time.