 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Cross Batch Normalization for Metric Learning
Paper and Code
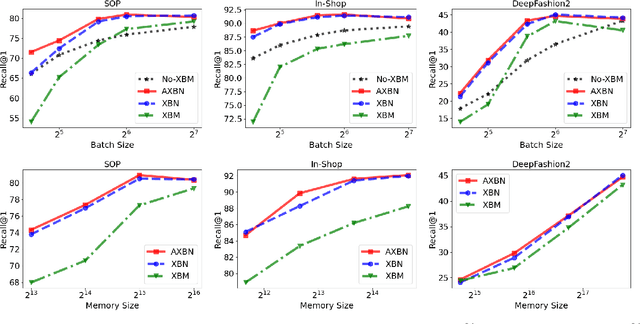
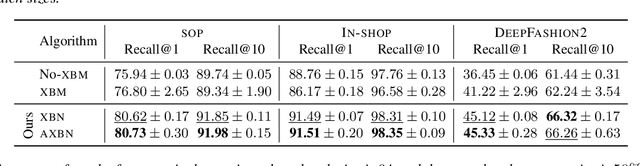


Metric learning is a fundamental problem in computer vision whereby a model is trained to learn a semantically useful embedding space via ranking losses. Traditionally, the effectiveness of a ranking loss depends on the minibatch size, and is, therefore, inherently limited by the memory constraints of the underlying hardware. While simply accumulating the embeddings across minibatches has proved useful (Wang et al. [2020]), we show that it is equally important to ensure that the accumulated embeddings are up to date. In particular, it is necessary to circumvent the representational drift between the accumulated embeddings and the feature embeddings at the current training iteration as the learnable parameters are being updated. In this paper, we model representational drift as distribution misalignment and tackle it using moment matching. The result is a simple method for updating the stored embeddings to match the first and second moments of the current embeddings at each training iteration. Experiments on three popular image retrieval datasets, namely, SOP, In-Shop, and DeepFashion2, demonstrate that our approach significantly improves the performance in all scenarios.