 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePareto-Conditioned Diffusion Models for Offline Multi-Objective Optimization
Jan 31, 2026Multi-objective optimization (MOO) arises in many real-world applications where trade-offs between competing objectives must be carefully balanced. In the offline setting, where only a static dataset is available, the main challenge is generalizing beyond observed data. We introduce Pareto-Conditioned Diffusion (PCD), a novel framework that formulates offline MOO as a conditional sampling problem. By conditioning directly on desired trade-offs, PCD avoids the need for explicit surrogate models. To effectively explore the Pareto front, PCD employs a reweighting strategy that focuses on high-performing samples and a reference-direction mechanism to guide sampling towards novel, promising regions beyond the training data. Experiments on standard offline MOO benchmarks show that PCD achieves highly competitive performance and, importantly, demonstrates greater consistency across diverse tasks than existing offline MOO approaches.
End-to-End Learning of Behavioural Inputs for Autonomous Driving in Dense Traffic
Oct 23, 2023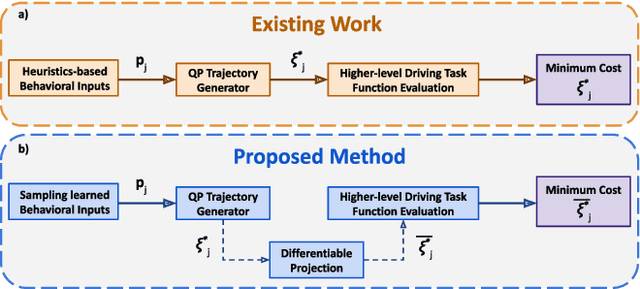
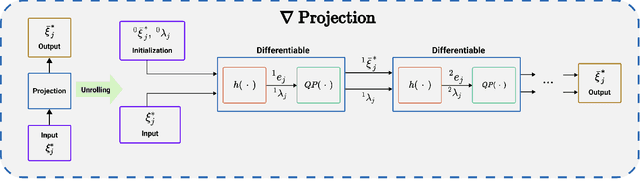
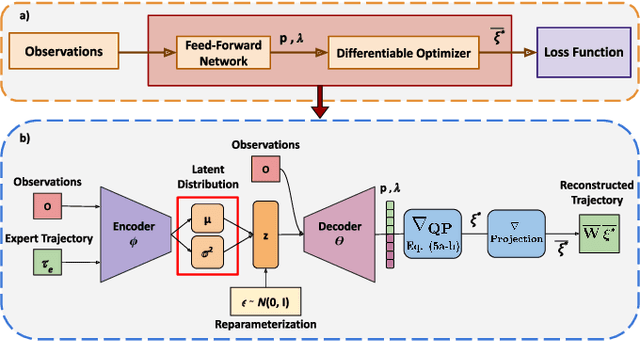
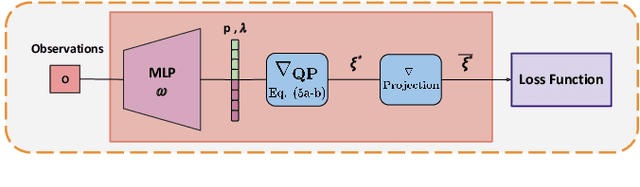
Trajectory sampling in the Frenet(road-aligned) frame, is one of the most popular methods for motion planning of autonomous vehicles. It operates by sampling a set of behavioural inputs, such as lane offset and forward speed, before solving a trajectory optimization problem conditioned on the sampled inputs. The sampling is handcrafted based on simple heuristics, does not adapt to driving scenarios, and is oblivious to the capabilities of downstream trajectory planners. In this paper, we propose an end-to-end learning of behavioural input distribution from expert demonstrations or in a self-supervised manner. Our core novelty lies in embedding a custom differentiable trajectory optimizer as a layer in neural networks, allowing us to update behavioural inputs by considering the optimizer's feedback. Moreover, our end-to-end approach also ensures that the learned behavioural inputs aid the convergence of the optimizer. We improve the state-of-the-art in the following aspects. First, we show that learned behavioural inputs substantially decrease collision rate while improving driving efficiency over handcrafted approaches. Second, our approach outperforms model predictive control methods based on sampling-based optimization.
Bi-Level Optimization Augmented with Conditional Variational Autoencoder for Autonomous Driving in Dense Traffic
Dec 05, 2022Autonomous driving has a natural bi-level structure. The goal of the upper behavioural layer is to provide appropriate lane change, speeding up, and braking decisions to optimize a given driving task. However, this layer can only indirectly influence the driving efficiency through the lower-level trajectory planner, which takes in the behavioural inputs to produce motion commands. Existing sampling-based approaches do not fully exploit the strong coupling between the behavioural and planning layer. On the other hand, end-to-end Reinforcement Learning (RL) can learn a behavioural layer while incorporating feedback from the lower-level planner. However, purely data-driven approaches often fail in safety metrics in unseen environments. This paper presents a novel alternative; a parameterized bi-level optimization that jointly computes the optimal behavioural decisions and the resulting downstream trajectory. Our approach runs in real-time using a custom GPU-accelerated batch optimizer, and a Conditional Variational Autoencoder learnt warm-start strategy. Extensive simulations show that our approach outperforms state-of-the-art model predictive control and RL approaches in terms of collision rate while being competitive in driving efficiency.
GPU Accelerated Convex Approximations for Fast Multi-Agent Trajectory Optimization
Nov 09, 2020

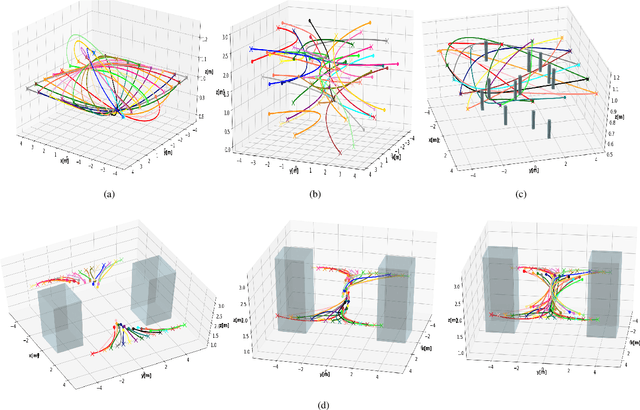
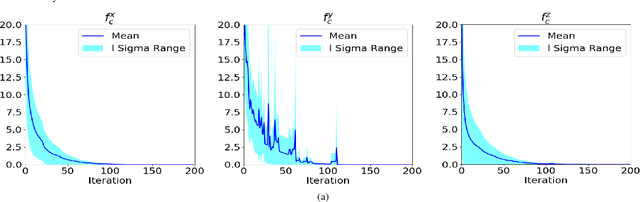
In this paper, we present a computationally efficient trajectory optimizer that can exploit GPUs to jointly compute trajectories of tens of agents in under a second. At the heart of our optimizer is a novel reformulation of the non-convex collision avoidance constraints that reduces the core computation in each iteration to that of solving a large scale, convex, unconstrained Quadratic Program (QP). We also show that the matrix factorization/inverse computation associated with the QP needs to be done only once and can be done offline for a given number of agents. This further simplifies the solution process, effectively reducing it to a problem of evaluating a few matrix-vector products. Moreover, for a large number of agents, this computation can be trivially accelerated on GPUs using existing off-the-shelf libraries. We validate our optimizer's performance on challenging benchmarks and show substantial improvement over state of the art in computation time and trajectory quality.