 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse and Controllable Image Captioning with Part-of-Speech Guidance
Paper and Code
May 31, 2018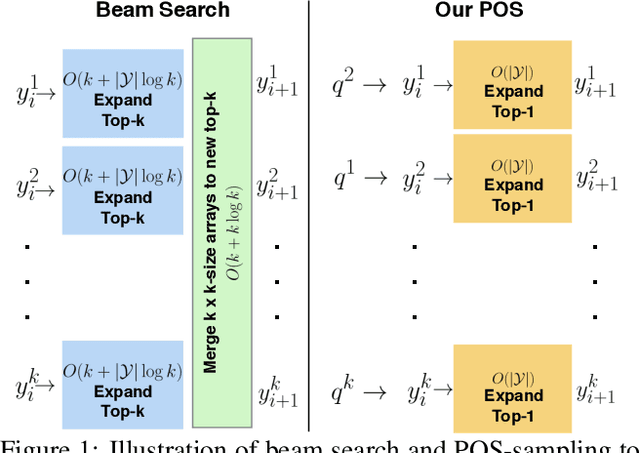
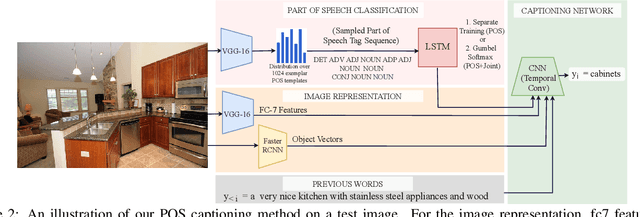
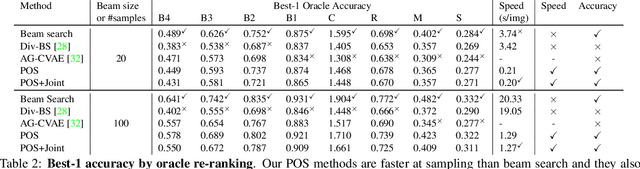
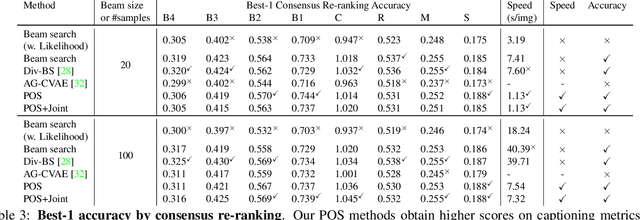
Automatically describing an image is an important capability for virtual assistants. Significant progress has been achieved in recent years on this task of image captioning. However, classical prediction techniques based on maximum likelihood trained LSTM nets don't embrace the inherent ambiguity of image captioning. To address this concern, recent variational auto-encoder and generative adversarial network based methods produce a set of captions by sampling from an abstract latent space. But, this latent space has limited interpretability and therefore, a control mechanism for captioning remains an open problem. This paper proposes a captioning technique conditioned on part-of-speech. Our method provides human interpretable control in form of part-of-speech. Importantly, part-of-speech is a language prior, and conditioning on it provides: (i) more diversity as evaluated by counting n-grams and the novel sentences generated, (ii) achieves high accuracy for the diverse captions on standard captioning metrics.