 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Learning from Demonstrations, Corrections, and Preferences during Physical Human-Robot Interaction
Paper and Code
Jul 07, 2022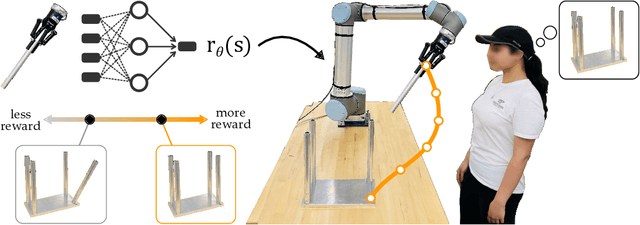


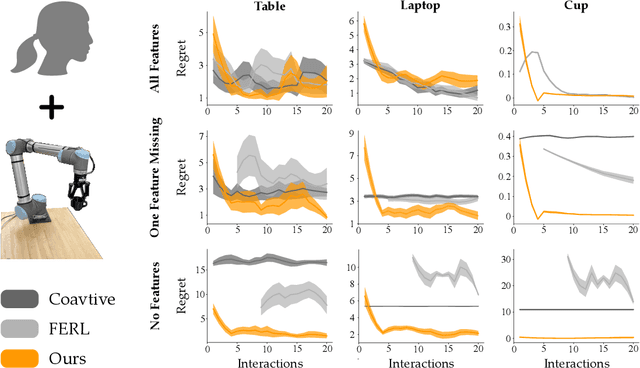
Humans can leverage physical interaction to teach robot arms. This physical interaction takes multiple forms depending on the task, the user, and what the robot has learned so far. State-of-the-art approaches focus on learning from a single modality, or combine multiple interaction types by assuming that the robot has prior information about the human's intended task. By contrast, in this paper we introduce an algorithmic formalism that unites learning from demonstrations, corrections, and preferences. Our approach makes no assumptions about the tasks the human wants to teach the robot; instead, we learn a reward model from scratch by comparing the human's inputs to nearby alternatives. We first derive a loss function that trains an ensemble of reward models to match the human's demonstrations, corrections, and preferences. The type and order of feedback is up to the human teacher: we enable the robot to collect this feedback passively or actively. We then apply constrained optimization to convert our learned reward into a desired robot trajectory. Through simulations and a user study we demonstrate that our proposed approach more accurately learns manipulation tasks from physical human interaction than existing baselines, particularly when the robot is faced with new or unexpected objectives. Videos of our user study are available at: https://youtu.be/FSUJsTYvEKU