 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLV-XAttn: Distributed Cross-Attention for Long Visual Inputs in Multimodal Large Language Models
Paper and Code
Feb 04, 2025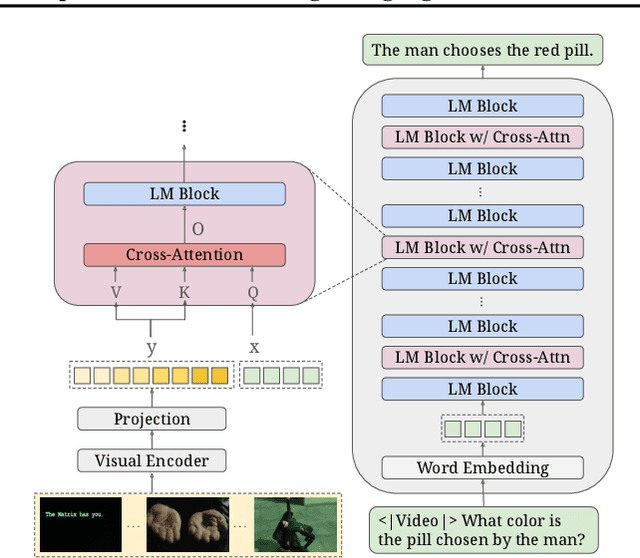


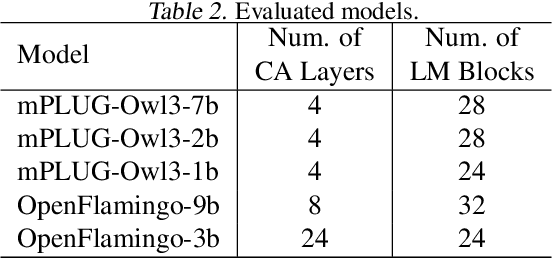
Cross-attention is commonly adopted in multimodal large language models (MLLMs) for integrating visual information into the language backbone. However, in applications with large visual inputs, such as video understanding, processing a large number of visual tokens in cross-attention layers leads to high memory demands and often necessitates distributed computation across multiple GPUs. Existing distributed attention mechanisms face significant communication overheads, making cross-attention layers a critical bottleneck for efficient training and inference of MLLMs. To address this, we propose LV-XAttn, a distributed, exact cross-attention mechanism with minimal communication overhead. We observe that in applications involving large visual inputs the size of the query block is typically much smaller than that of the key-value blocks. Thus, in LV-XAttn we keep the large key-value blocks locally on each GPU and exchange smaller query blocks across GPUs. We also introduce an efficient activation recomputation technique enabling support for longer visual context. We theoretically analyze the communication benefits of LV-XAttn and show that it can achieve speedups for a wide range of models. Our evaluations with mPLUG-Owl3 and OpenFlamingo models find that LV-XAttn achieves up to 5.58$\times$ end-to-end speedup compared to existing approaches.