 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Deep Learning Inference via Learned Caches
Jan 18, 2021
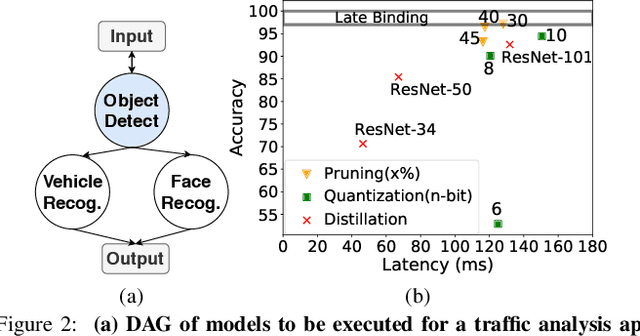
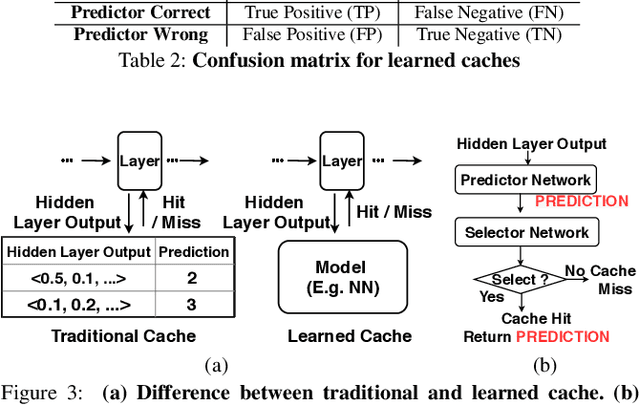
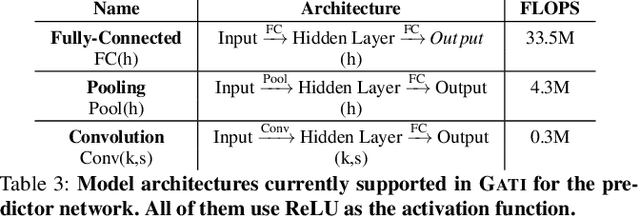
Deep Neural Networks (DNNs) are witnessing increased adoption in multiple domains owing to their high accuracy in solving real-world problems. However, this high accuracy has been achieved by building deeper networks, posing a fundamental challenge to the low latency inference desired by user-facing applications. Current low latency solutions trade-off on accuracy or fail to exploit the inherent temporal locality in prediction serving workloads. We observe that caching hidden layer outputs of the DNN can introduce a form of late-binding where inference requests only consume the amount of computation needed. This enables a mechanism for achieving low latencies, coupled with an ability to exploit temporal locality. However, traditional caching approaches incur high memory overheads and lookup latencies, leading us to design learned caches - caches that consist of simple ML models that are continuously updated. We present the design of GATI, an end-to-end prediction serving system that incorporates learned caches for low-latency DNN inference. Results show that GATI can reduce inference latency by up to 7.69X on realistic workloads.
Accelerating Deep Learning Inference via Freezing
Feb 07, 2020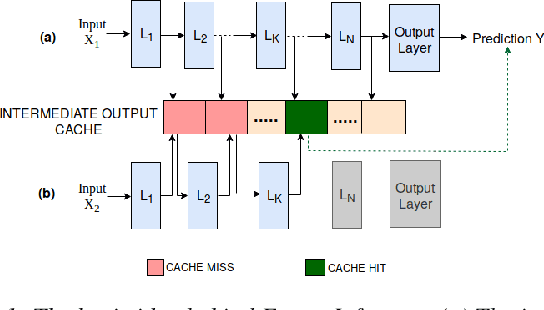

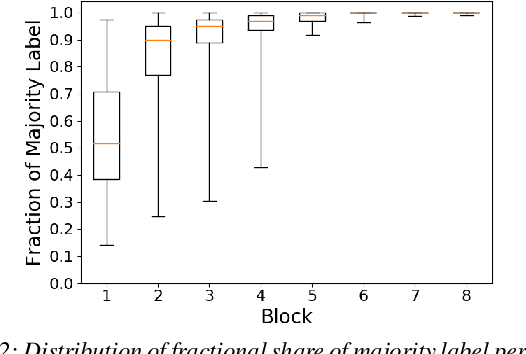
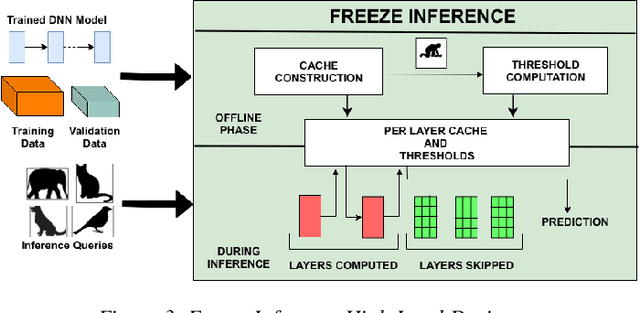
Over the last few years, Deep Neural Networks (DNNs) have become ubiquitous owing to their high accuracy on real-world tasks. However, this increase in accuracy comes at the cost of computationally expensive models leading to higher prediction latencies. Prior efforts to reduce this latency such as quantization, model distillation, and any-time prediction models typically trade-off accuracy for performance. In this work, we observe that caching intermediate layer outputs can help us avoid running all the layers of a DNN for a sizeable fraction of inference requests. We find that this can potentially reduce the number of effective layers by half for 91.58% of CIFAR-10 requests run on ResNet-18. We present Freeze Inference, a system that introduces approximate caching at each intermediate layer and we discuss techniques to reduce the cache size and improve the cache hit rate. Finally, we discuss some of the open research challenges in realizing such a design.