 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositionality in Time Series: A Proof of Concept using Symbolic Dynamics and Compositional Data Augmentation
Aug 28, 2025This work investigates whether time series of natural phenomena can be understood as being generated by sequences of latent states which are ordered in systematic and regular ways. We focus on clinical time series and ask whether clinical measurements can be interpreted as being generated by meaningful physiological states whose succession follows systematic principles. Uncovering the underlying compositional structure will allow us to create synthetic data to alleviate the notorious problem of sparse and low-resource data settings in clinical time series forecasting, and deepen our understanding of clinical data. We start by conceptualizing compositionality for time series as a property of the data generation process, and then study data-driven procedures that can reconstruct the elementary states and composition rules of this process. We evaluate the success of this methods using two empirical tests originating from a domain adaptation perspective. Both tests infer the similarity of the original time series distribution and the synthetic time series distribution from the similarity of expected risk of time series forecasting models trained and tested on original and synthesized data in specific ways. Our experimental results show that the test set performance achieved by training on compositionally synthesized data is comparable to training on original clinical time series data, and that evaluation of models on compositionally synthesized test data shows similar results to evaluating on original test data, outperforming randomization-based data augmentation. An additional downstream evaluation of the prediction task of sequential organ failure assessment (SOFA) scores shows significant performance gains when model training is entirely based on compositionally synthesized data compared to training on original data.
Early Prediction of Causes (not Effects) in Healthcare by Long-Term Clinical Time Series Forecasting
Aug 07, 2024Machine learning for early syndrome diagnosis aims to solve the intricate task of predicting a ground truth label that most often is the outcome (effect) of a medical consensus definition applied to observed clinical measurements (causes), given clinical measurements observed several hours before. Instead of focusing on the prediction of the future effect, we propose to directly predict the causes via time series forecasting (TSF) of clinical variables and determine the effect by applying the gold standard consensus definition to the forecasted values. This method has the invaluable advantage of being straightforwardly interpretable to clinical practitioners, and because model training does not rely on a particular label anymore, the forecasted data can be used to predict any consensus-based label. We exemplify our method by means of long-term TSF with Transformer models, with a focus on accurate prediction of sparse clinical variables involved in the SOFA-based Sepsis-3 definition and the new Simplified Acute Physiology Score (SAPS-II) definition. Our experiments are conducted on two datasets and show that contrary to recent proposals which advocate set function encoders for time series and direct multi-step decoders, best results are achieved by a combination of standard dense encoders with iterative multi-step decoders. The key for success of iterative multi-step decoding can be attributed to its ability to capture cross-variate dependencies and to a student forcing training strategy that teaches the model to rely on its own previous time step predictions for the next time step prediction.
Validity problems in clinical machine learning by indirect data labeling using consensus definitions
Nov 06, 2023
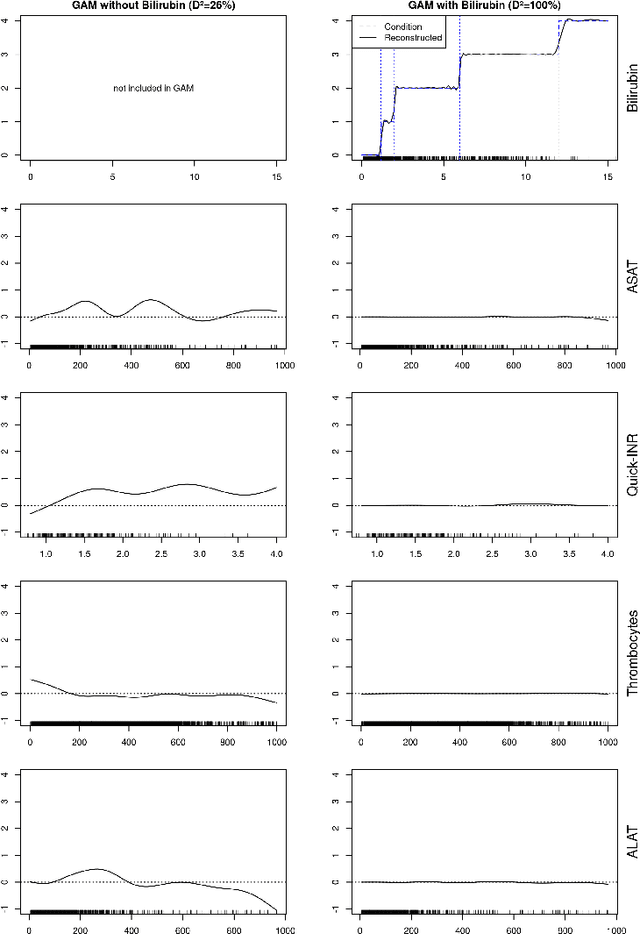

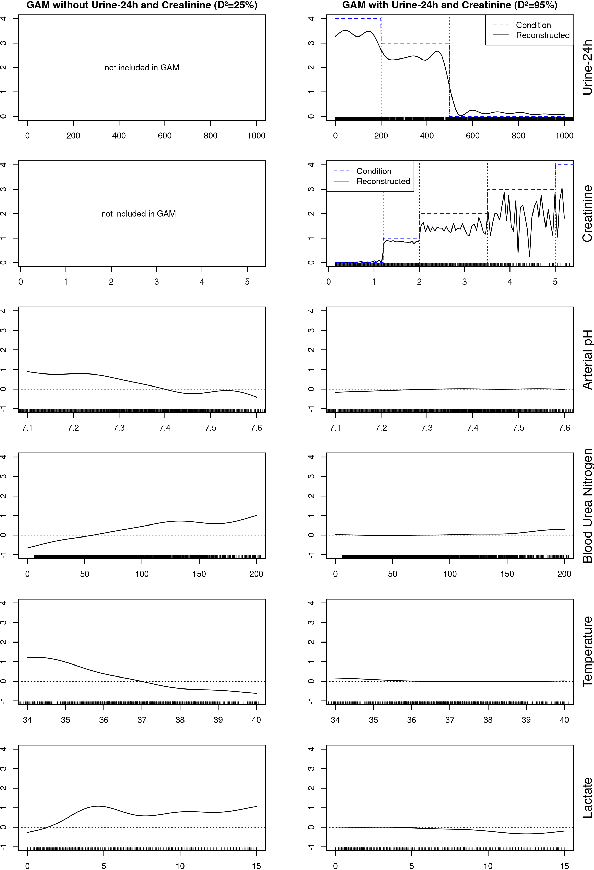
We demonstrate a validity problem of machine learning in the vital application area of disease diagnosis in medicine. It arises when target labels in training data are determined by an indirect measurement, and the fundamental measurements needed to determine this indirect measurement are included in the input data representation. Machine learning models trained on this data will learn nothing else but to exactly reconstruct the known target definition. Such models show perfect performance on similarly constructed test data but will fail catastrophically on real-world examples where the defining fundamental measurements are not or only incompletely available. We present a general procedure allowing identification of problematic datasets and black-box machine learning models trained on them, and exemplify our detection procedure on the task of early prediction of sepsis.
Towards Inferential Reproducibility of Machine Learning Research
Feb 16, 2023



Reliability of machine learning evaluation -- the consistency of observed evaluation scores across replicated model training runs -- is affected by several sources of nondeterminism which can be regarded as measurement noise. Current tendencies to remove noise in order to enforce reproducibility of research results neglect inherent nondeterminism at the implementation level and disregard crucial interaction effects between algorithmic noise factors and data properties. This limits the scope of conclusions that can be drawn from such experiments. Instead of removing noise, we propose to incorporate several sources of variance, including their interaction with data properties, into an analysis of significance and reliability of machine learning evaluation, with the aim to draw inferences beyond particular instances of trained models. We show how to use linear mixed effects models (LMEMs) to analyze performance evaluation scores, and to conduct statistical inference with a generalized likelihood ratio test (GLRT). This allows us to incorporate arbitrary sources of noise like meta-parameter variations into statistical significance testing, and to assess performance differences conditional on data properties. Furthermore, a variance component analysis (VCA) enables the analysis of the contribution of noise sources to overall variance and the computation of a reliability coefficient by the ratio of substantial to total variance.
False perfection in machine prediction: Detecting and assessing circularity problems in machine learning
Jun 23, 2021



Machine learning algorithms train models from patterns of input data and target outputs, with the goal of predicting correct outputs for unseen test inputs. Here we demonstrate a problem of machine learning in vital application areas such as medical informatics or patent law that consists of the inclusion of measurements on which target outputs are deterministically defined in the representations of input data. This leads to perfect, but circular predictions based on a machine reconstruction of the known target definition, but fails on real-world data where the defining measurements may not or only incompletely be available. We present a circularity test that shows, for given datasets and black-box machine learning models, whether the target functional definition can be reconstructed and has been used in training. We argue that a transfer of research results to real-world applications requires to avoid circularity by separating measurements that define target outcomes from data representations in machine learning.