 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2V-Turbo: Breaking the Quality Bottleneck of Video Consistency Model with Mixed Reward Feedback
Paper and Code
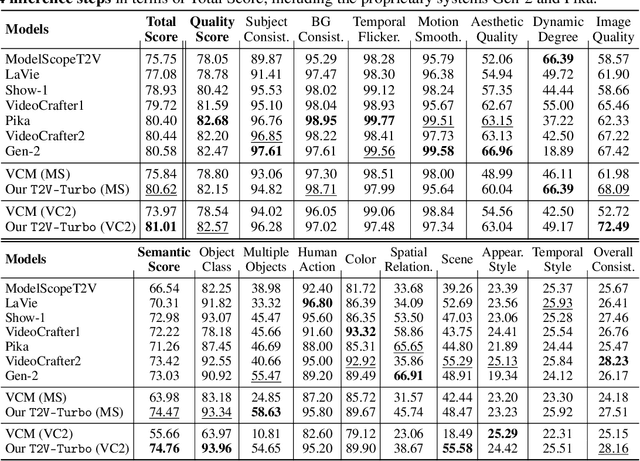
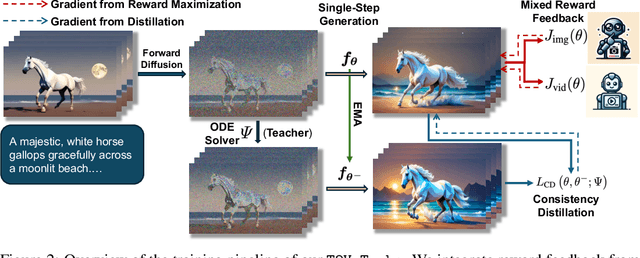
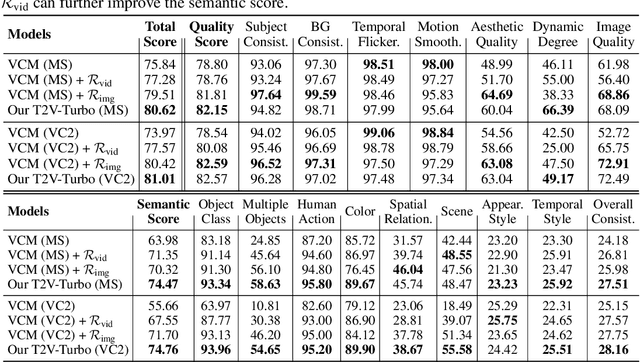
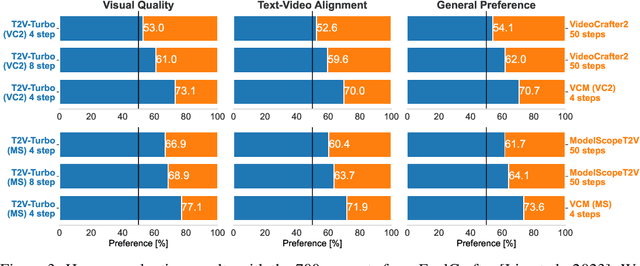
Diffusion-based text-to-video (T2V) models have achieved significant success but continue to be hampered by the slow sampling speed of their iterative sampling processes. To address the challenge, consistency models have been proposed to facilitate fast inference, albeit at the cost of sample quality. In this work, we aim to break the quality bottleneck of a video consistency model (VCM) to achieve $\textbf{both fast and high-quality video generation}$. We introduce T2V-Turbo, which integrates feedback from a mixture of differentiable reward models into the consistency distillation (CD) process of a pre-trained T2V model. Notably, we directly optimize rewards associated with single-step generations that arise naturally from computing the CD loss, effectively bypassing the memory constraints imposed by backpropagating gradients through an iterative sampling process. Remarkably, the 4-step generations from our T2V-Turbo achieve the highest total score on VBench, even surpassing Gen-2 and Pika. We further conduct human evaluations to corroborate the results, validating that the 4-step generations from our T2V-Turbo are preferred over the 50-step DDIM samples from their teacher models, representing more than a tenfold acceleration while improving video generation quality.