 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetached and Interactive Multimodal Learning
Paper and Code
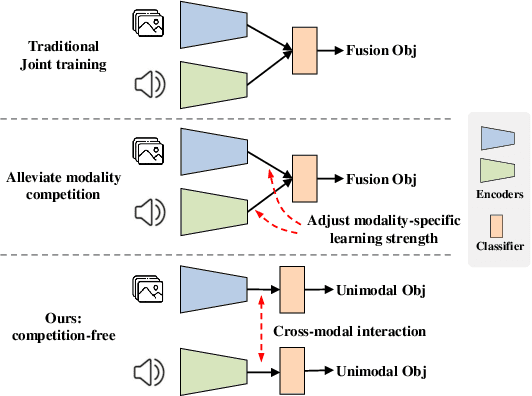

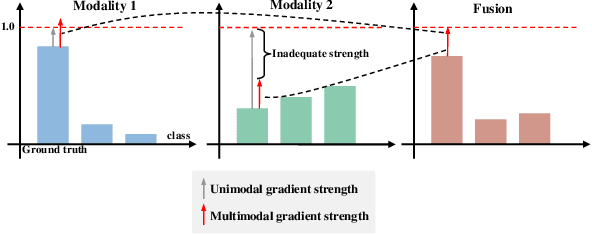
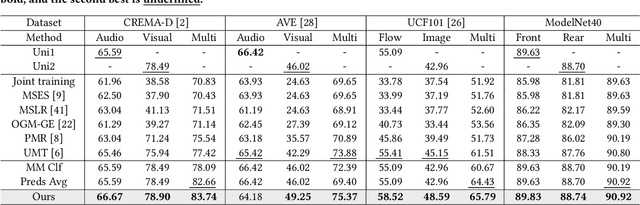
Recently, Multimodal Learning (MML) has gained significant interest as it compensates for single-modality limitations through comprehensive complementary information within multimodal data. However, traditional MML methods generally use the joint learning framework with a uniform learning objective that can lead to the modality competition issue, where feedback predominantly comes from certain modalities, limiting the full potential of others. In response to this challenge, this paper introduces DI-MML, a novel detached MML framework designed to learn complementary information across modalities under the premise of avoiding modality competition. Specifically, DI-MML addresses competition by separately training each modality encoder with isolated learning objectives. It further encourages cross-modal interaction via a shared classifier that defines a common feature space and employing a dimension-decoupled unidirectional contrastive (DUC) loss to facilitate modality-level knowledge transfer. Additionally, to account for varying reliability in sample pairs, we devise a certainty-aware logit weighting strategy to effectively leverage complementary information at the instance level during inference. Extensive experiments conducted on audio-visual, flow-image, and front-rear view datasets show the superior performance of our proposed method. The code is released at https://github.com/fanyunfeng-bit/DI-MML.