 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction Position Matters in Sequence Generation with Large Language Models
Aug 23, 2023
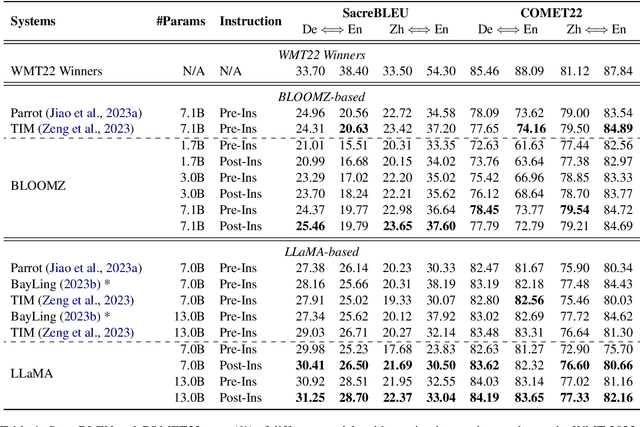

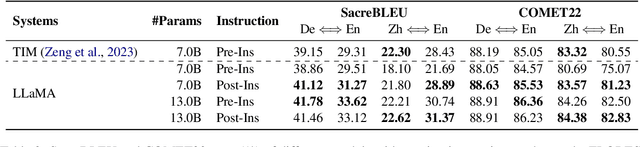
Large language models (LLMs) are capable of performing conditional sequence generation tasks, such as translation or summarization, through instruction fine-tuning. The fine-tuning data is generally sequentially concatenated from a specific task instruction, an input sentence, and the corresponding response. Considering the locality modeled by the self-attention mechanism of LLMs, these models face the risk of instruction forgetting when generating responses for long input sentences. To mitigate this issue, we propose enhancing the instruction-following capability of LLMs by shifting the position of task instructions after the input sentences. Theoretical analysis suggests that our straightforward method can alter the model's learning focus, thereby emphasizing the training of instruction-following capabilities. Concurrently, experimental results demonstrate that our approach consistently outperforms traditional settings across various model scales (1B / 7B / 13B) and different sequence generation tasks (translation and summarization), without any additional data or annotation costs. Notably, our method significantly improves the zero-shot performance on conditional sequence generation, e.g., up to 9.7 BLEU points on WMT zero-shot translation tasks.
Towards Multiple References Era -- Addressing Data Leakage and Limited Reference Diversity in NLG Evaluation
Aug 10, 2023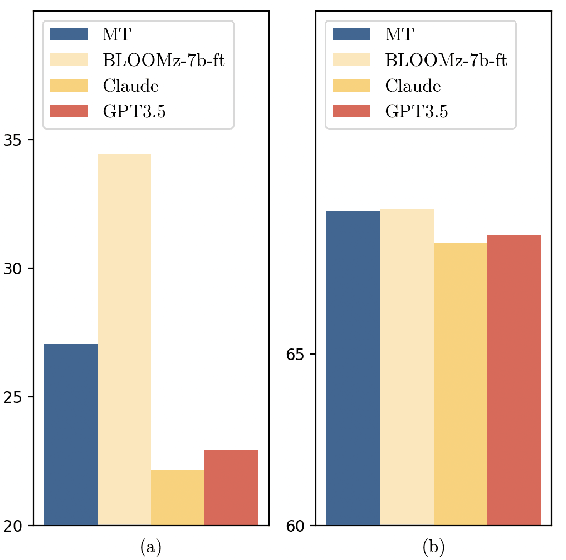
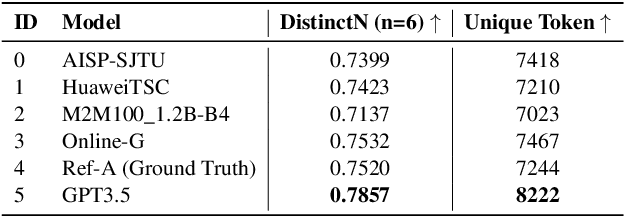
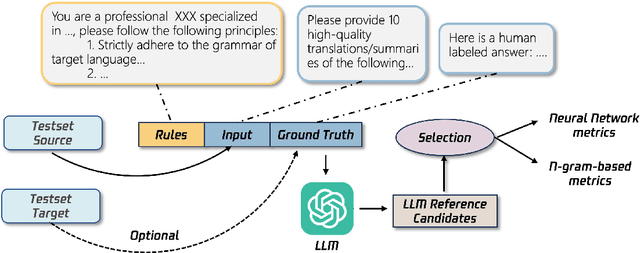
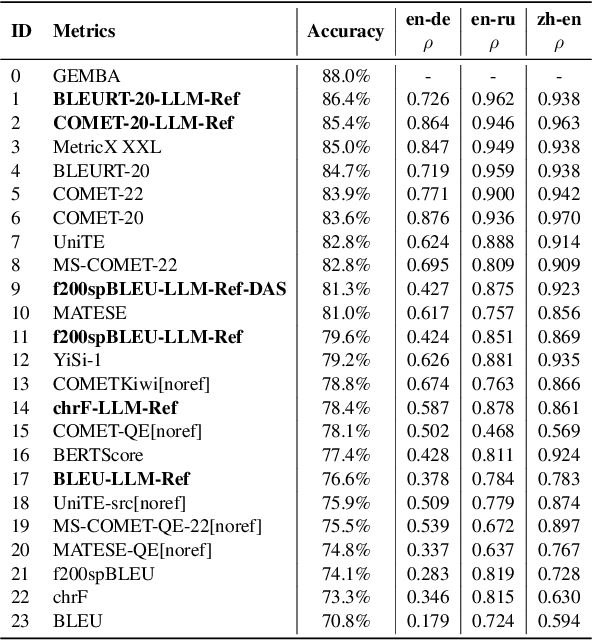
N-gram matching-based evaluation metrics, such as BLEU and chrF, are widely utilized across a range of natural language generation (NLG) tasks. However, recent studies have revealed a weak correlation between these matching-based metrics and human evaluations, especially when compared with neural-based metrics like BLEURT. In this paper, we conjecture that the performance bottleneck in matching-based metrics may be caused by the limited diversity of references. To address this issue, we propose to utilize \textit{multiple references} to enhance the consistency between these metrics and human evaluations. Within the WMT Metrics benchmarks, we observe that the multi-references F200spBLEU surpasses the conventional single-reference one by an accuracy improvement of 7.2\%. Remarkably, it also exceeds the neural-based BERTscore by an accuracy enhancement of 3.9\%. Moreover, we observe that the data leakage issue in large language models (LLMs) can be mitigated to a large extent by our multi-reference metric. We release the code and data at \url{https://github.com/SefaZeng/LLM-Ref}
BranchNorm: Robustly Scaling Extremely Deep Transformers
May 04, 2023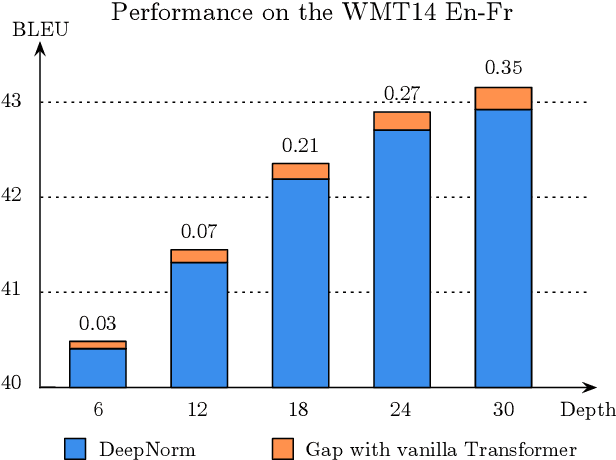
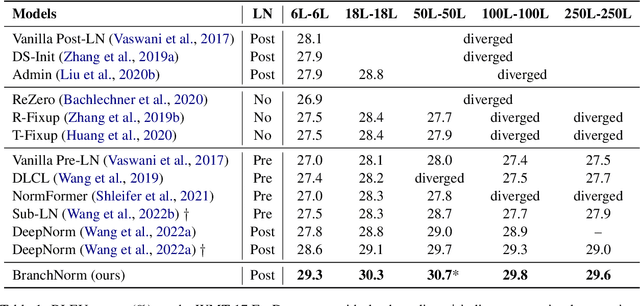
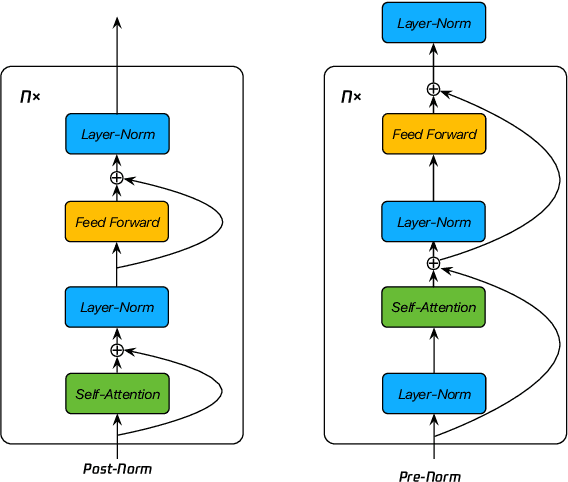
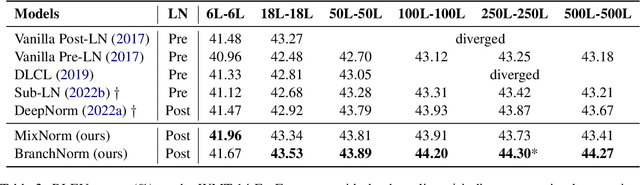
Recently, DeepNorm scales Transformers into extremely deep (i.e., 1000 layers) and reveals the promising potential of deep scaling. To stabilize the training of deep models, DeepNorm (Wang et al., 2022) attempts to constrain the model update to a constant value. Although applying such a constraint can benefit the early stage of model training, it may lead to undertrained models during the whole training procedure. In this paper, we propose BranchNorm, which dynamically rescales the non-residual branch of Transformer in accordance with the training period. BranchNorm not only theoretically stabilizes the training with smooth gradient norms at the early stage, but also encourages better convergence in the subsequent training stage. Experiment results on multiple translation tasks demonstrate that BranchNorm achieves a better trade-off between training stability and converge performance.
WeChat Neural Machine Translation Systems for WMT21
Aug 05, 2021
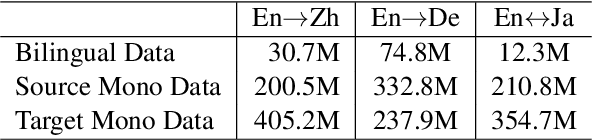
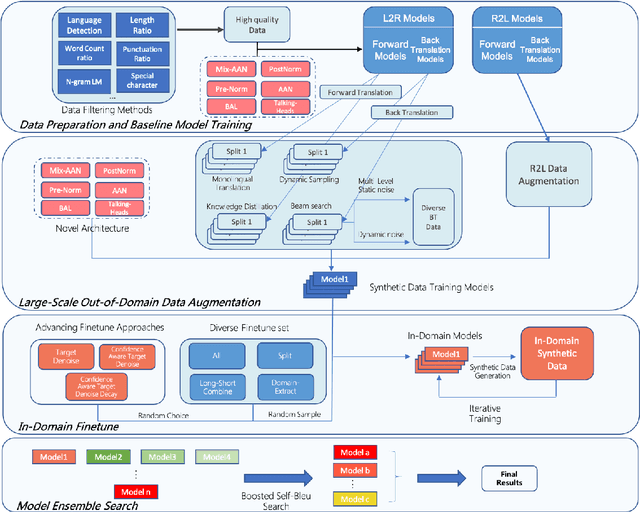
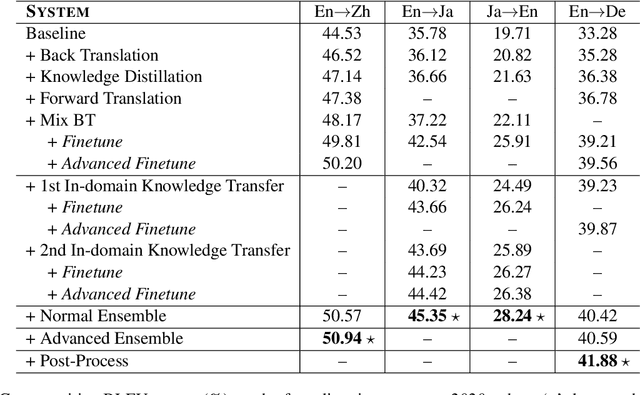
This paper introduces WeChat AI's participation in WMT 2021 shared news translation task on English->Chinese, English->Japanese, Japanese->English and English->German. Our systems are based on the Transformer (Vaswani et al., 2017) with several novel and effective variants. In our experiments, we employ data filtering, large-scale synthetic data generation (i.e., back-translation, knowledge distillation, forward-translation, iterative in-domain knowledge transfer), advanced finetuning approaches, and boosted Self-BLEU based model ensemble. Our constrained systems achieve 36.9, 46.9, 27.8 and 31.3 case-sensitive BLEU scores on English->Chinese, English->Japanese, Japanese->English and English->German, respectively. The BLEU scores of English->Chinese, English->Japanese and Japanese->English are the highest among all submissions, and that of English->German is the highest among all constrained submissions.
WeChat Neural Machine Translation Systems for WMT20
Oct 05, 2020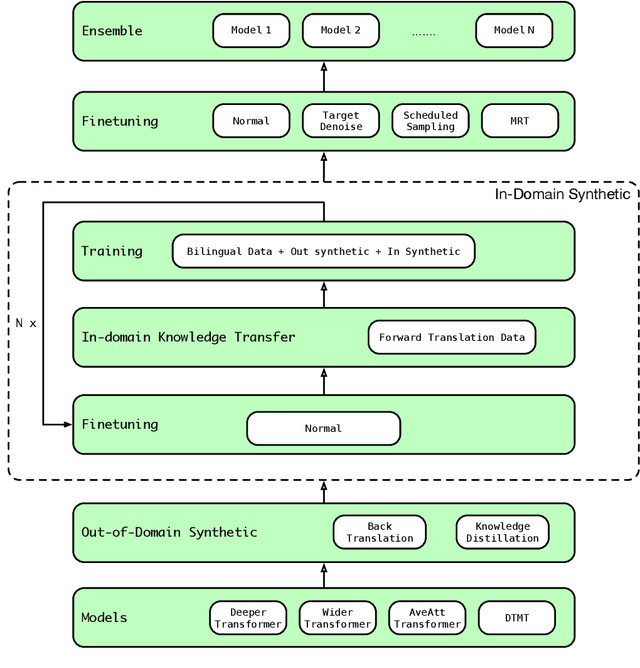

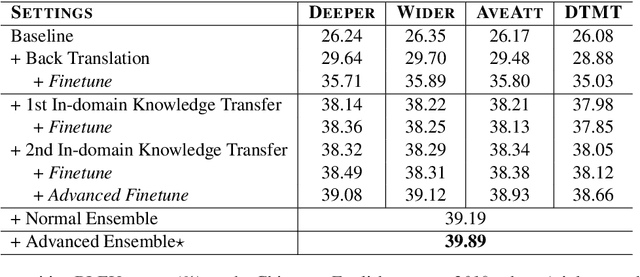
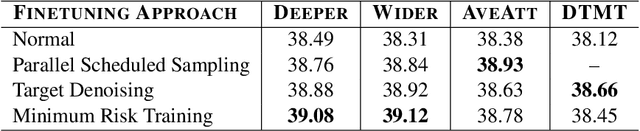
We participate in the WMT 2020 shared news translation task on Chinese to English. Our system is based on the Transformer (Vaswani et al., 2017a) with effective variants and the DTMT (Meng and Zhang, 2019) architecture. In our experiments, we employ data selection, several synthetic data generation approaches (i.e., back-translation, knowledge distillation, and iterative in-domain knowledge transfer), advanced finetuning approaches and self-bleu based model ensemble. Our constrained Chinese to English system achieves 36.9 case-sensitive BLEU score, which is the highest among all submissions.