 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeChat Neural Machine Translation Systems for WMT21
Aug 05, 2021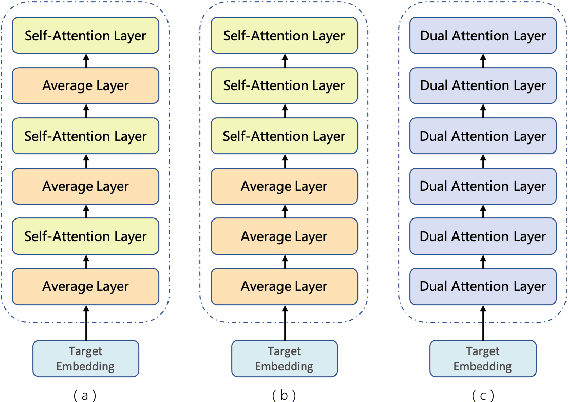
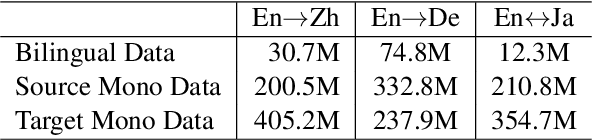
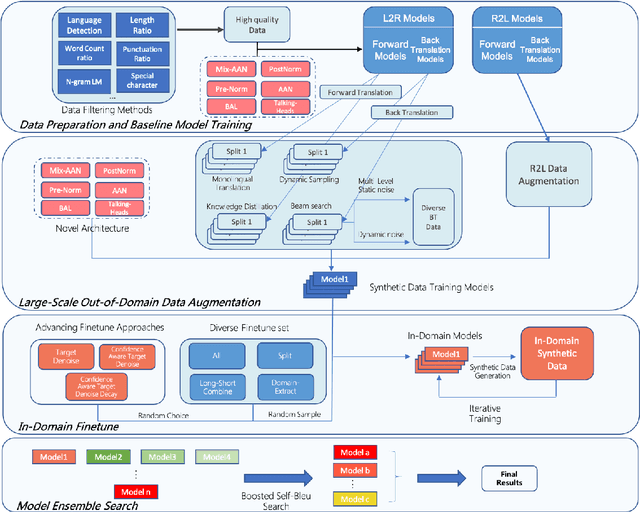
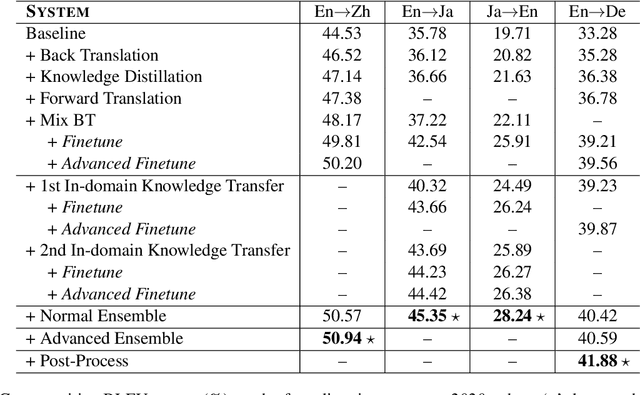
This paper introduces WeChat AI's participation in WMT 2021 shared news translation task on English->Chinese, English->Japanese, Japanese->English and English->German. Our systems are based on the Transformer (Vaswani et al., 2017) with several novel and effective variants. In our experiments, we employ data filtering, large-scale synthetic data generation (i.e., back-translation, knowledge distillation, forward-translation, iterative in-domain knowledge transfer), advanced finetuning approaches, and boosted Self-BLEU based model ensemble. Our constrained systems achieve 36.9, 46.9, 27.8 and 31.3 case-sensitive BLEU scores on English->Chinese, English->Japanese, Japanese->English and English->German, respectively. The BLEU scores of English->Chinese, English->Japanese and Japanese->English are the highest among all submissions, and that of English->German is the highest among all constrained submissions.
Learning to Recover from Multi-Modality Errors for Non-Autoregressive Neural Machine Translation
Jun 09, 2020
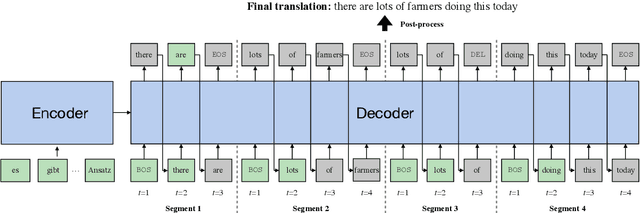
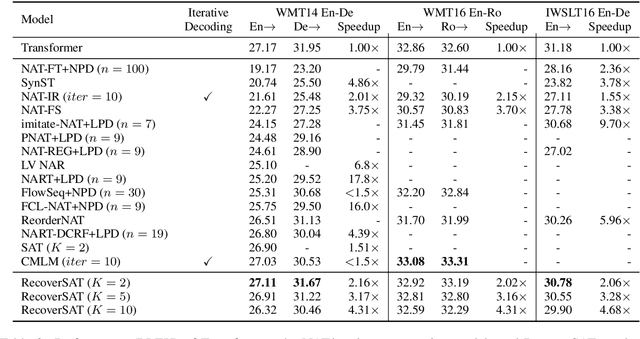

Non-autoregressive neural machine translation (NAT) predicts the entire target sequence simultaneously and significantly accelerates inference process. However, NAT discards the dependency information in a sentence, and thus inevitably suffers from the multi-modality problem: the target tokens may be provided by different possible translations, often causing token repetitions or missing. To alleviate this problem, we propose a novel semi-autoregressive model RecoverSAT in this work, which generates a translation as a sequence of segments. The segments are generated simultaneously while each segment is predicted token-by-token. By dynamically determining segment length and deleting repetitive segments, RecoverSAT is capable of recovering from repetitive and missing token errors. Experimental results on three widely-used benchmark datasets show that our proposed model achieves more than 4$\times$ speedup while maintaining comparable performance compared with the corresponding autoregressive model.
Guiding Non-Autoregressive Neural Machine Translation Decoding with Reordering Information
Nov 06, 2019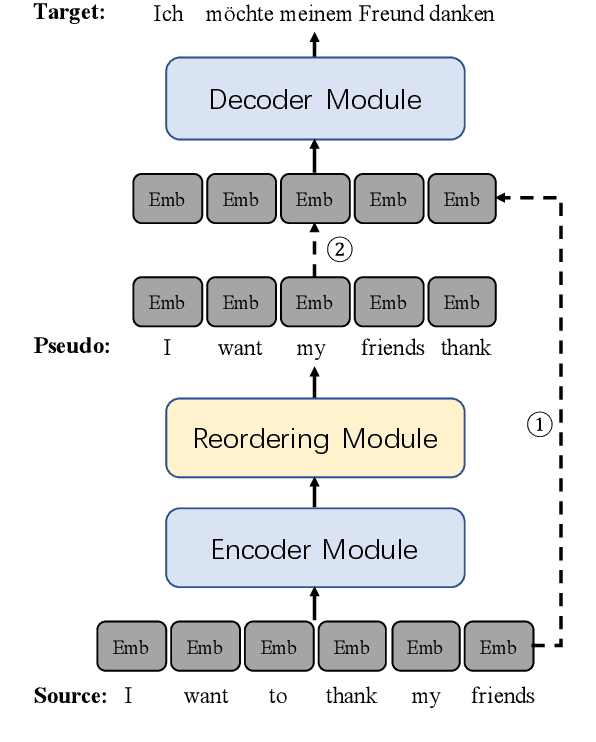
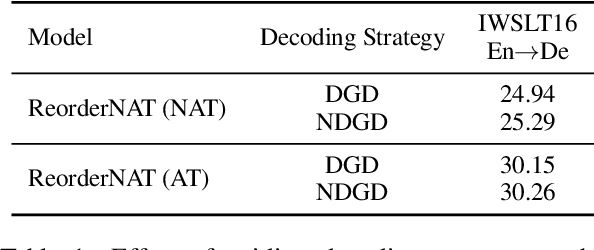

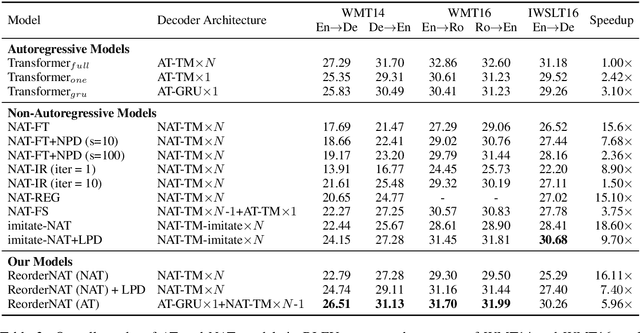
Non-autoregressive neural machine translation (NAT) generates each target word in parallel and has achieved promising inference acceleration. However, existing NAT models still have a big gap in translation quality compared to autoregressive neural machine translation models due to the enormous decoding space. To address this problem, we propose a novel NAT framework named ReorderNAT which explicitly models the reordering information in the decoding procedure. We further introduce deterministic and non-deterministic decoding strategies that utilize reordering information to narrow the decoding search space in our proposed ReorderNAT. Experimental results on various widely-used datasets show that our proposed model achieves better performance compared to existing NAT models, and even achieves comparable translation quality as autoregressive translation models with a significant speedup.
NumNet: Machine Reading Comprehension with Numerical Reasoning
Oct 15, 2019
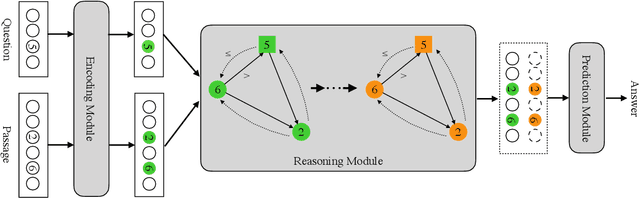
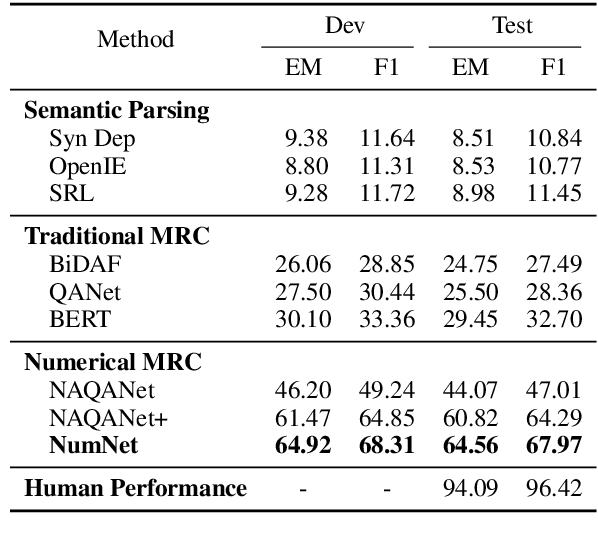
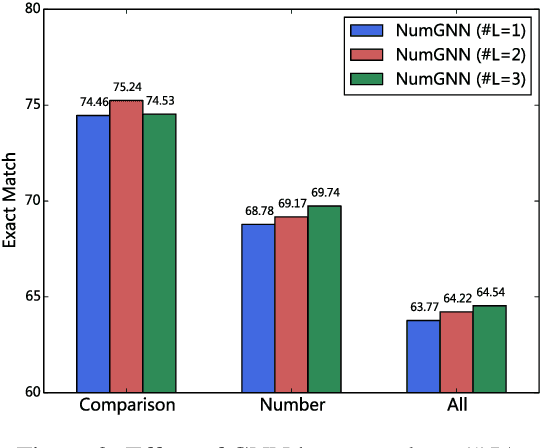
Numerical reasoning, such as addition, subtraction, sorting and counting is a critical skill in human's reading comprehension, which has not been well considered in existing machine reading comprehension (MRC) systems. To address this issue, we propose a numerical MRC model named as NumNet, which utilizes a numerically-aware graph neural network to consider the comparing information and performs numerical reasoning over numbers in the question and passage. Our system achieves an EM-score of 64.56% on the DROP dataset, outperforming all existing machine reading comprehension models by considering the numerical relations among numbers.
Option Comparison Network for Multiple-choice Reading Comprehension
Mar 07, 2019
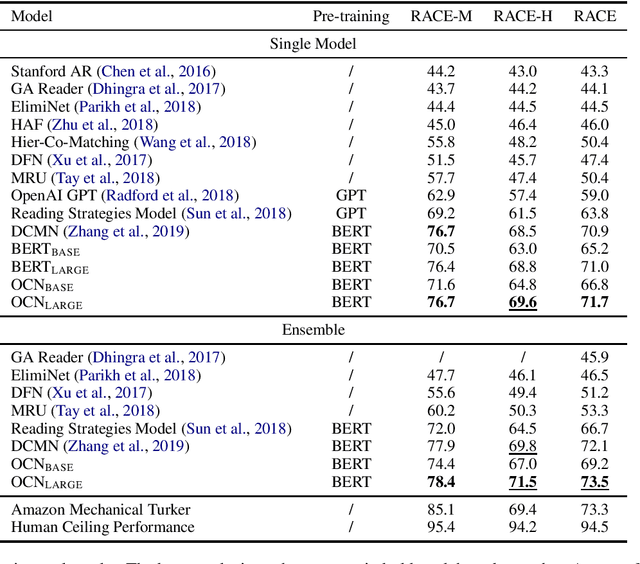

Multiple-choice reading comprehension (MCRC) is the task of selecting the correct answer from multiple options given a question and an article. Existing MCRC models typically either read each option independently or compute a fixed-length representation for each option before comparing them. However, humans typically compare the options at multiple-granularity level before reading the article in detail to make reasoning more efficient. Mimicking humans, we propose an option comparison network (OCN) for MCRC which compares options at word-level to better identify their correlations to help reasoning. Specially, each option is encoded into a vector sequence using a skimmer to retain fine-grained information as much as possible. An attention mechanism is leveraged to compare these sequences vector-by-vector to identify more subtle correlations between options, which is potentially valuable for reasoning. Experimental results on the human English exam MCRC dataset RACE show that our model outperforms existing methods significantly. Moreover, it is also the first model that surpasses Amazon Mechanical Turker performance on the whole dataset.