 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the WMT 2022 Shared Task on Translation Suggestion
Nov 30, 2022We report the result of the first edition of the WMT shared task on Translation Suggestion (TS). The task aims to provide alternatives for specific words or phrases given the entire documents generated by machine translation (MT). It consists two sub-tasks, namely, the naive translation suggestion and translation suggestion with hints. The main difference is that some hints are provided in sub-task two, therefore, it is easier for the model to generate more accurate suggestions. For sub-task one, we provide the corpus for the language pairs English-German and English-Chinese. And only English-Chinese corpus is provided for the sub-task two. We received 92 submissions from 5 participating teams in sub-task one and 6 submissions for the sub-task 2, most of them covering all of the translation directions. We used the automatic metric BLEU for evaluating the performance of each submission.
Summer: WeChat Neural Machine Translation Systems for the WMT22 Biomedical Translation Task
Nov 28, 2022

This paper introduces WeChat's participation in WMT 2022 shared biomedical translation task on Chinese to English. Our systems are based on the Transformer, and use several different Transformer structures to improve the quality of translation. In our experiments, we employ data filtering, data generation, several variants of Transformer, fine-tuning and model ensemble. Our Chinese$\to$English system, named Summer, achieves the highest BLEU score among all submissions.
WeTS: A Benchmark for Translation Suggestion
Oct 11, 2021
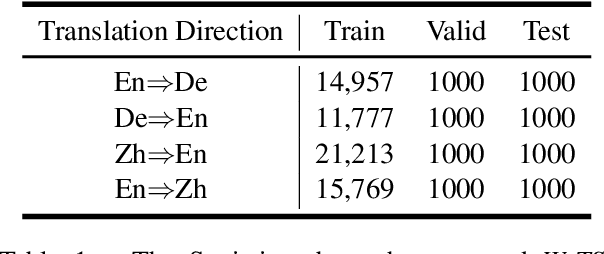
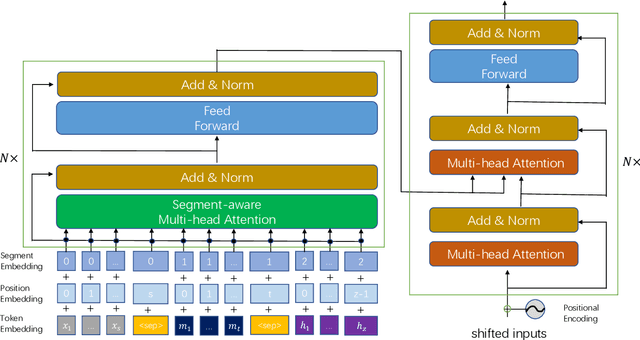

Translation Suggestion (TS), which provides alternatives for specific words or phrases given the entire documents translated by machine translation (MT) \cite{lee2021intellicat}, has been proven to play a significant role in post editing (PE). However, there is still no publicly available data set to support in-depth research for this problem, and no reproducible experimental results can be followed by researchers in this community. To break this limitation, we create a benchmark data set for TS, called \emph{WeTS}, which contains golden corpus annotated by expert translators on four translation directions. Apart from the human-annotated golden corpus, we also propose several novel methods to generate synthetic corpus which can substantially improve the performance of TS. With the corpus we construct, we introduce the Transformer-based model for TS, and experimental results show that our model achieves State-Of-The-Art (SOTA) results on all four translation directions, including English-to-German, German-to-English, Chinese-to-English and English-to-Chinese. Codes and corpus can be found at \url{https://github.com/ZhenYangIACAS/WeTS.git}.
WeChat Neural Machine Translation Systems for WMT21
Aug 05, 2021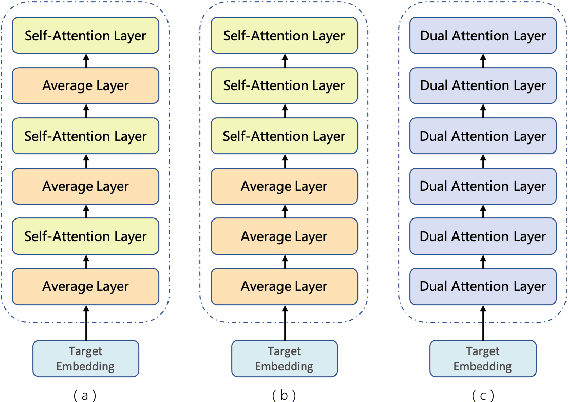
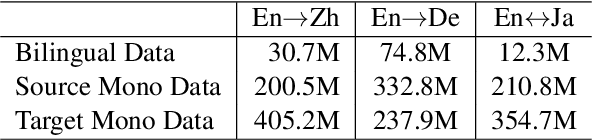
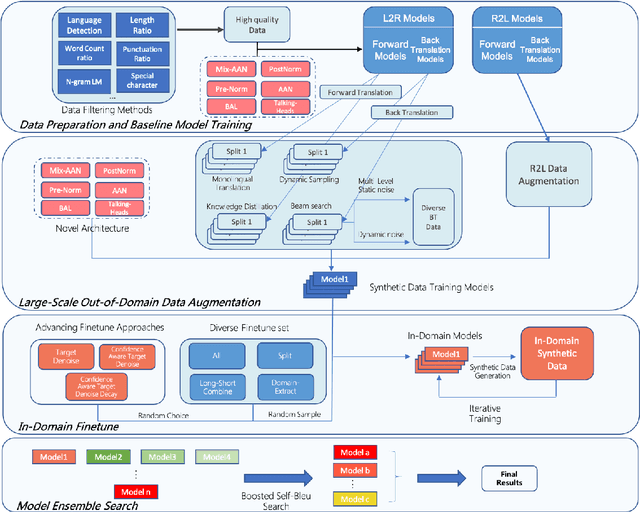
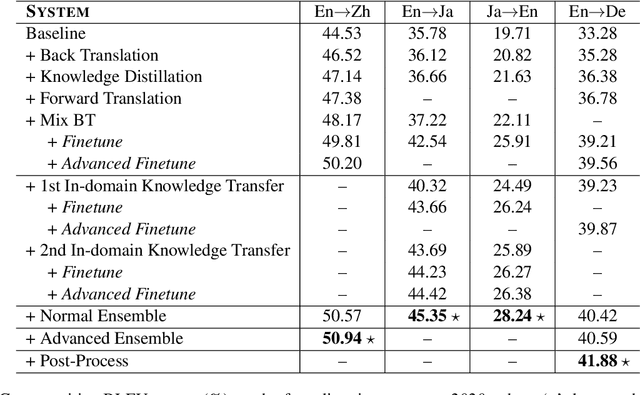
This paper introduces WeChat AI's participation in WMT 2021 shared news translation task on English->Chinese, English->Japanese, Japanese->English and English->German. Our systems are based on the Transformer (Vaswani et al., 2017) with several novel and effective variants. In our experiments, we employ data filtering, large-scale synthetic data generation (i.e., back-translation, knowledge distillation, forward-translation, iterative in-domain knowledge transfer), advanced finetuning approaches, and boosted Self-BLEU based model ensemble. Our constrained systems achieve 36.9, 46.9, 27.8 and 31.3 case-sensitive BLEU scores on English->Chinese, English->Japanese, Japanese->English and English->German, respectively. The BLEU scores of English->Chinese, English->Japanese and Japanese->English are the highest among all submissions, and that of English->German is the highest among all constrained submissions.