 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeTS: A Benchmark for Translation Suggestion
Paper and Code

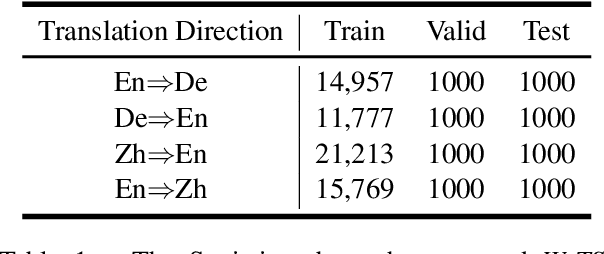
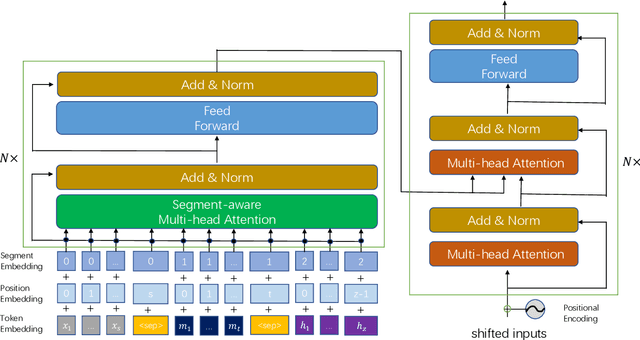

Translation Suggestion (TS), which provides alternatives for specific words or phrases given the entire documents translated by machine translation (MT) \cite{lee2021intellicat}, has been proven to play a significant role in post editing (PE). However, there is still no publicly available data set to support in-depth research for this problem, and no reproducible experimental results can be followed by researchers in this community. To break this limitation, we create a benchmark data set for TS, called \emph{WeTS}, which contains golden corpus annotated by expert translators on four translation directions. Apart from the human-annotated golden corpus, we also propose several novel methods to generate synthetic corpus which can substantially improve the performance of TS. With the corpus we construct, we introduce the Transformer-based model for TS, and experimental results show that our model achieves State-Of-The-Art (SOTA) results on all four translation directions, including English-to-German, German-to-English, Chinese-to-English and English-to-Chinese. Codes and corpus can be found at \url{https://github.com/ZhenYangIACAS/WeTS.git}.