 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large Language Model-Driven Reward Design Framework via Dynamic Feedback for Reinforcement Learning
Oct 18, 2024



Large Language Models (LLMs) have shown significant potential in designing reward functions for Reinforcement Learning (RL) tasks. However, obtaining high-quality reward code often involves human intervention, numerous LLM queries, or repetitive RL training. To address these issues, we propose CARD, a LLM-driven Reward Design framework that iteratively generates and improves reward function code. Specifically, CARD includes a Coder that generates and verifies the code, while a Evaluator provides dynamic feedback to guide the Coder in improving the code, eliminating the need for human feedback. In addition to process feedback and trajectory feedback, we introduce Trajectory Preference Evaluation (TPE), which evaluates the current reward function based on trajectory preferences. If the code fails the TPE, the Evaluator provides preference feedback, avoiding RL training at every iteration and making the reward function better aligned with the task objective. Empirical results on Meta-World and ManiSkill2 demonstrate that our method achieves an effective balance between task performance and token efficiency, outperforming or matching the baselines across all tasks. On 10 out of 12 tasks, CARD shows better or comparable performance to policies trained with expert-designed rewards, and our method even surpasses the oracle on 3 tasks.
Relief R-CNN : Utilizing Convolutional Features for Fast Object Detection
Apr 26, 2017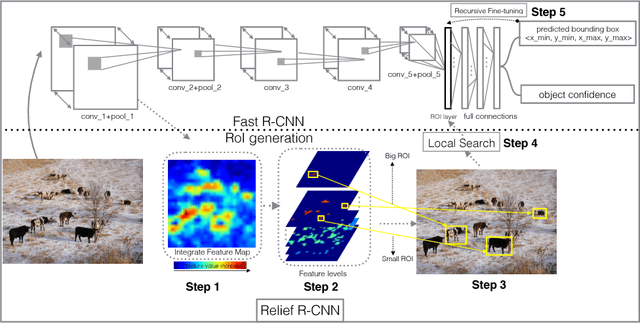
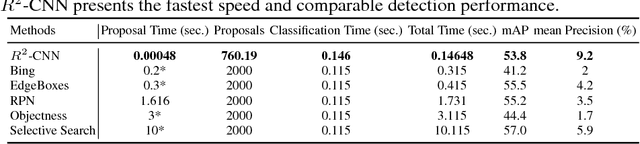
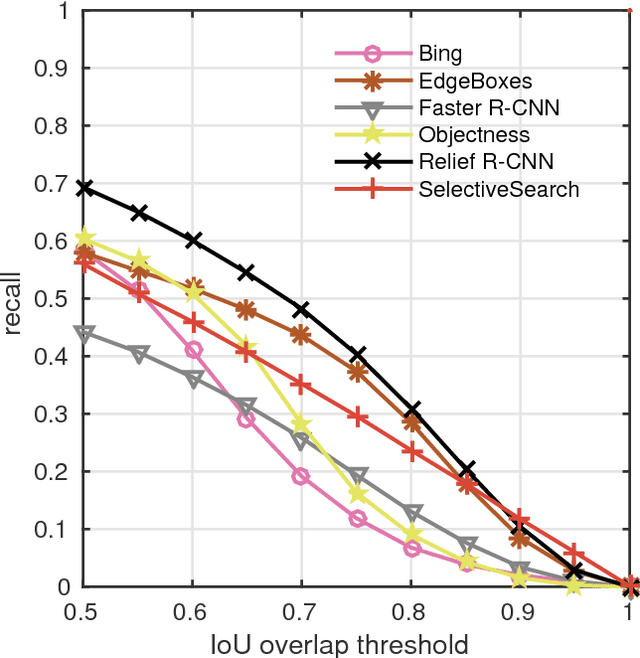
R-CNN style methods are sorts of the state-of-the-art object detection methods, which consist of region proposal generation and deep CNN classification. However, the proposal generation phase in this paradigm is usually time consuming, which would slow down the whole detection time in testing. This paper suggests that the value discrepancies among features in deep convolutional feature maps contain plenty of useful spatial information, and proposes a simple approach to extract the information for fast region proposal generation in testing. The proposed method, namely Relief R-CNN (R2-CNN), adopts a novel region proposal generator in a trained R-CNN style model. The new generator directly generates proposals from convolutional features by some simple rules, thus resulting in a much faster proposal generation speed and a lower demand of computation resources. Empirical studies show that R2-CNN could achieve the fastest detection speed with comparable accuracy among all the compared algorithms in testing.
Success Probability of Exploration: a Concrete Analysis of Learning Efficiency
Dec 02, 2016

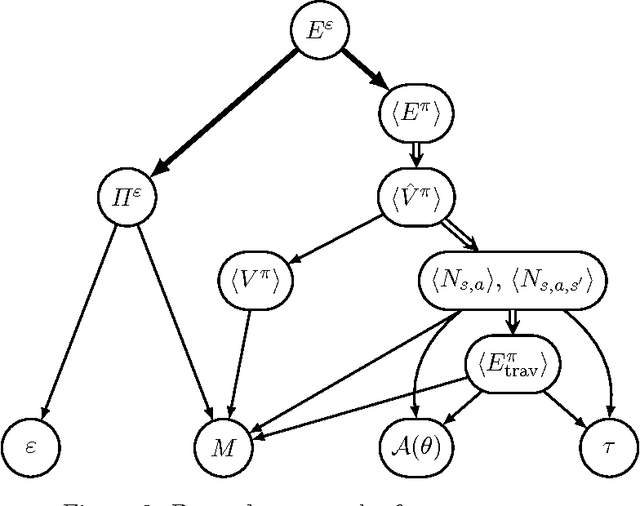
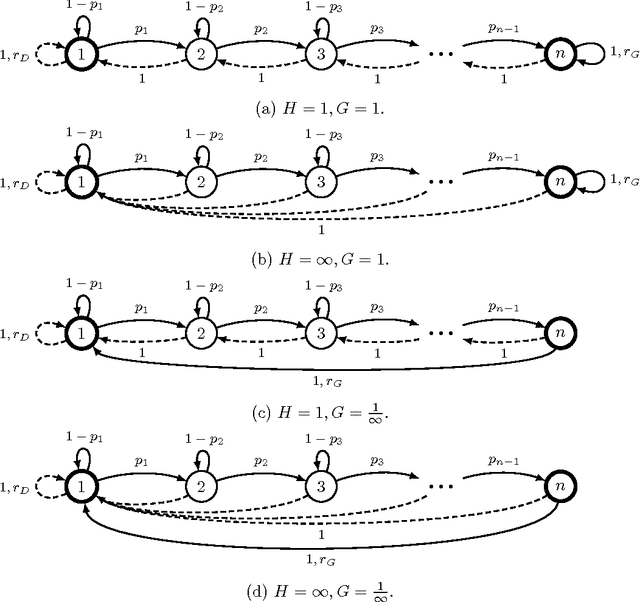
Exploration has been a crucial part of reinforcement learning, yet several important questions concerning exploration efficiency are still not answered satisfactorily by existing analytical frameworks. These questions include exploration parameter setting, situation analysis, and hardness of MDPs, all of which are unavoidable for practitioners. To bridge the gap between the theory and practice, we propose a new analytical framework called the success probability of exploration. We show that those important questions of exploration above can all be answered under our framework, and the answers provided by our framework meet the needs of practitioners better than the existing ones. More importantly, we introduce a concrete and practical approach to evaluating the success probabilities in certain MDPs without the need of actually running the learning algorithm. We then provide empirical results to verify our approach, and demonstrate how the success probability of exploration can be used to analyse and predict the behaviours and possible outcomes of exploration, which are the keys to the answer of the important questions of exploration.