 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Consistency on Visual Corruptions for Single-Source Domain Generalization
Apr 27, 2022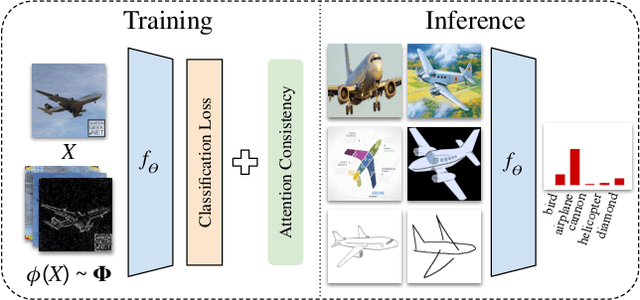
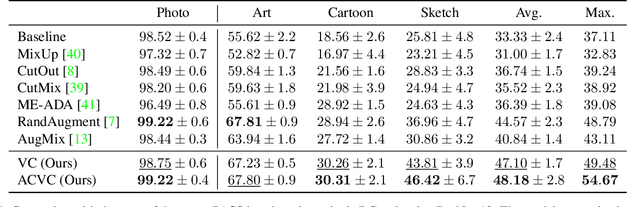


Generalizing visual recognition models trained on a single distribution to unseen input distributions (i.e. domains) requires making them robust to superfluous correlations in the training set. In this work, we achieve this goal by altering the training images to simulate new domains and imposing consistent visual attention across the different views of the same sample. We discover that the first objective can be simply and effectively met through visual corruptions. Specifically, we alter the content of the training images using the nineteen corruptions of the ImageNet-C benchmark and three additional transformations based on Fourier transform. Since these corruptions preserve object locations, we propose an attention consistency loss to ensure that class activation maps across original and corrupted versions of the same training sample are aligned. We name our model Attention Consistency on Visual Corruptions (ACVC). We show that ACVC consistently achieves the state of the art on three single-source domain generalization benchmarks, PACS, COCO, and the large-scale DomainNet.
A Deeper Look into Convolutions via Pruning
Feb 04, 2021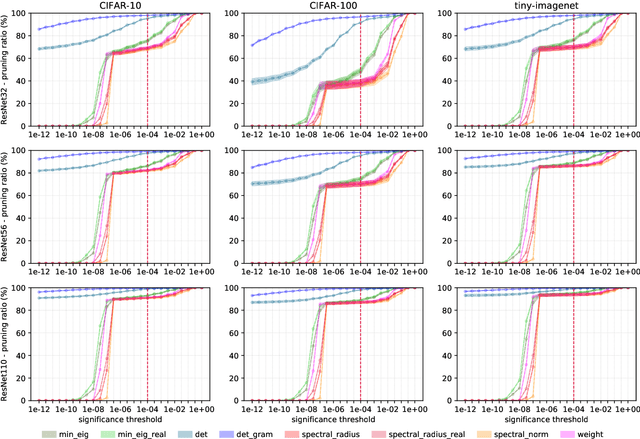



Convolutional neural networks (CNNs) are able to attain better visual recognition performance than fully connected neural networks despite having much less parameters due to their parameter sharing principle. Hence, modern architectures are designed to contain a very small number of fully-connected layers, often at the end, after multiple layers of convolutions. It is interesting to observe that we can replace large fully-connected layers with relatively small groups of tiny matrices applied on the entire image. Moreover, although this strategy already reduces the number of parameters, most of the convolutions can be eliminated as well, without suffering any loss in recognition performance. However, there is no solid recipe to detect this hidden subset of convolutional neurons that is responsible for the majority of the recognition work. Hence, in this work, we use the matrix characteristics based on eigenvalues in addition to the classical weight-based importance assignment approach for pruning to shed light on the internal mechanisms of a widely used family of CNNs, namely residual neural networks (ResNets), for the image classification problem using CIFAR-10, CIFAR-100 and Tiny ImageNet datasets.