 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Synthetic Control Method
Feb 04, 2026The synthetic control method (SCM) estimates causal effects in panel data with a single-treated unit by constructing a counterfactual outcome as a weighted combination of untreated control units that matches the pre-treatment trajectory. In this paper, we introduce the targeted synthetic control (TSC) method, a new two-stage estimator that directly estimates the counterfactual outcome. Specifically, our TSC method (1) yields a targeted debiasing estimator, in the sense that the targeted updating refines the initial weights to produce more stable weights; and (2) ensures that the final counterfactual estimation is a convex combination of observed control outcomes to enable direct interpretation of the synthetic control weights. TSC is flexible and can be instantiated with arbitrary machine learning models. Methodologically, TSC starts from an initial set of synthetic-control weights via a one-dimensional targeted update through the weight-tilting submodel, which calibrates the weights to reduce bias of weights estimation arising from pre-treatment fit. Furthermore, TSC avoids key shortcomings of existing methods (e.g., the augmented SCM), which can produce unbounded counterfactual estimates. Across extensive synthetic and real-world experiments, TSC consistently improves estimation accuracy over state-of-the-art SCM baselines.
UniCorn: Towards Self-Improving Unified Multimodal Models through Self-Generated Supervision
Jan 08, 2026While Unified Multimodal Models (UMMs) have achieved remarkable success in cross-modal comprehension, a significant gap persists in their ability to leverage such internal knowledge for high-quality generation. We formalize this discrepancy as Conduction Aphasia, a phenomenon where models accurately interpret multimodal inputs but struggle to translate that understanding into faithful and controllable synthesis. To address this, we propose UniCorn, a simple yet elegant self-improvement framework that eliminates the need for external data or teacher supervision. By partitioning a single UMM into three collaborative roles: Proposer, Solver, and Judge, UniCorn generates high-quality interactions via self-play and employs cognitive pattern reconstruction to distill latent understanding into explicit generative signals. To validate the restoration of multimodal coherence, we introduce UniCycle, a cycle-consistency benchmark based on a Text to Image to Text reconstruction loop. Extensive experiments demonstrate that UniCorn achieves comprehensive and substantial improvements over the base model across six general image generation benchmarks. Notably, it achieves SOTA performance on TIIF(73.8), DPG(86.8), CompBench(88.5), and UniCycle while further delivering substantial gains of +5.0 on WISE and +6.5 on OneIG. These results highlight that our method significantly enhances T2I generation while maintaining robust comprehension, demonstrating the scalability of fully self-supervised refinement for unified multimodal intelligence.
LLM-Driven Treatment Effect Estimation Under Inference Time Text Confounding
Jul 03, 2025Estimating treatment effects is crucial for personalized decision-making in medicine, but this task faces unique challenges in clinical practice. At training time, models for estimating treatment effects are typically trained on well-structured medical datasets that contain detailed patient information. However, at inference time, predictions are often made using textual descriptions (e.g., descriptions with self-reported symptoms), which are incomplete representations of the original patient information. In this work, we make three contributions. (1) We show that the discrepancy between the data available during training time and inference time can lead to biased estimates of treatment effects. We formalize this issue as an inference time text confounding problem, where confounders are fully observed during training time but only partially available through text at inference time. (2) To address this problem, we propose a novel framework for estimating treatment effects that explicitly accounts for inference time text confounding. Our framework leverages large language models together with a custom doubly robust learner to mitigate biases caused by the inference time text confounding. (3) Through a series of experiments, we demonstrate the effectiveness of our framework in real-world applications.
Foundation Models for Causal Inference via Prior-Data Fitted Networks
Jun 12, 2025Prior-data fitted networks (PFNs) have recently been proposed as a promising way to train tabular foundation models. PFNs are transformers that are pre-trained on synthetic data generated from a prespecified prior distribution and that enable Bayesian inference through in-context learning. In this paper, we introduce CausalFM, a comprehensive framework for training PFN-based foundation models in various causal inference settings. First, we formalize the construction of Bayesian priors for causal inference based on structural causal models (SCMs) in a principled way and derive necessary criteria for the validity of such priors. Building on this, we propose a novel family of prior distributions using causality-inspired Bayesian neural networks that enable CausalFM to perform Bayesian causal inference in various settings, including back-door, front-door, and instrumental variable adjustment. Finally, we instantiate CausalFM and explicitly train a foundation model for estimating conditional average treatment effects (CATEs) using back-door adjustment. We show that CausalFM performs competitively for CATE estimation using various synthetic and semi-synthetic benchmarks. In sum, our framework can be used as a general recipe to train foundation models for various causal inference settings. In contrast to the current state-of-the-art in causal inference, CausalFM offers a novel paradigm with the potential to fundamentally change how practitioners perform causal inference in medicine, economics, and other disciplines.
DiffPO: A causal diffusion model for learning distributions of potential outcomes
Oct 11, 2024


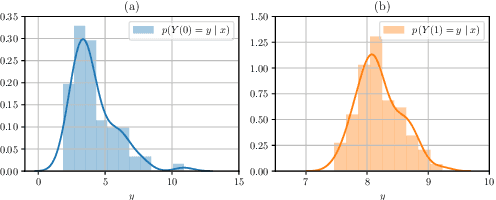
Predicting potential outcomes of interventions from observational data is crucial for decision-making in medicine, but the task is challenging due to the fundamental problem of causal inference. Existing methods are largely limited to point estimates of potential outcomes with no uncertain quantification; thus, the full information about the distributions of potential outcomes is typically ignored. In this paper, we propose a novel causal diffusion model called DiffPO, which is carefully designed for reliable inferences in medicine by learning the distribution of potential outcomes. In our DiffPO, we leverage a tailored conditional denoising diffusion model to learn complex distributions, where we address the selection bias through a novel orthogonal diffusion loss. Another strength of our DiffPO method is that it is highly flexible (e.g., it can also be used to estimate different causal quantities such as CATE). Across a wide range of experiments, we show that our method achieves state-of-the-art performance.
Neural Randomized Planning for Whole Body Robot Motion
May 18, 2024Robot motion planning has made vast advances over the past decades, but the challenge remains: robot mobile manipulators struggle to plan long-range whole-body motion in common household environments in real time, because of high-dimensional robot configuration space and complex environment geometry. To tackle the challenge, this paper proposes Neural Randomized Planner (NRP), which combines a global sampling-based motion planning (SBMP) algorithm and a local neural sampler. Intuitively, NRP uses the search structure inside the global planner to stitch together learned local sampling distributions to form a global sampling distribution adaptively. It benefits from both learning and planning. Locally, it tackles high dimensionality by learning to sample in promising regions from data, with a rich neural network representation. Globally, it composes the local sampling distributions through planning and exploits local geometric similarity to scale up to complex environments. Experiments both in simulation and on a real robot show \NRP yields superior performance compared to some of the best classical and learning-enhanced SBMP algorithms. Further, despite being trained in simulation, NRP demonstrates zero-shot transfer to a real robot operating in novel household environments, without any fine-tuning or manual adaptation.
Counterfactual Fairness for Predictions using Generative Adversarial Networks
Oct 26, 2023



Fairness in predictions is of direct importance in practice due to legal, ethical, and societal reasons. It is often achieved through counterfactual fairness, which ensures that the prediction for an individual is the same as that in a counterfactual world under a different sensitive attribute. However, achieving counterfactual fairness is challenging as counterfactuals are unobservable. In this paper, we develop a novel deep neural network called Generative Counterfactual Fairness Network (GCFN) for making predictions under counterfactual fairness. Specifically, we leverage a tailored generative adversarial network to directly learn the counterfactual distribution of the descendants of the sensitive attribute, which we then use to enforce fair predictions through a novel counterfactual mediator regularization. If the counterfactual distribution is learned sufficiently well, our method is mathematically guaranteed to ensure the notion of counterfactual fairness. Thereby, our GCFN addresses key shortcomings of existing baselines that are based on inferring latent variables, yet which (a) are potentially correlated with the sensitive attributes and thus lead to bias, and (b) have weak capability in constructing latent representations and thus low prediction performance. Across various experiments, our method achieves state-of-the-art performance. Using a real-world case study from recidivism prediction, we further demonstrate that our method makes meaningful predictions in practice.
DiT: Efficient Vision Transformers with Dynamic Token Routing
Aug 11, 2023



Recently, the tokens of images share the same static data flow in many dense networks. However, challenges arise from the variance among the objects in images, such as large variations in the spatial scale and difficulties of recognition for visual entities. In this paper, we propose a data-dependent token routing strategy to elaborate the routing paths of image tokens for Dynamic Vision Transformer, dubbed DiT. The proposed framework generates a data-dependent path per token, adapting to the object scales and visual discrimination of tokens. In feed-forward, the differentiable routing gates are designed to select the scaling paths and feature transformation paths for image tokens, leading to multi-path feature propagation. In this way, the impact of object scales and visual discrimination of image representation can be carefully tuned. Moreover, the computational cost can be further reduced by giving budget constraints to the routing gate and early-stopping of feature extraction. In experiments, our DiT achieves superior performance and favorable complexity/accuracy trade-offs than many SoTA methods on ImageNet classification, object detection, instance segmentation, and semantic segmentation. Particularly, the DiT-B5 obtains 84.8\% top-1 Acc on ImageNet with 10.3 GFLOPs, which is 1.0\% higher than that of the SoTA method with similar computational complexity. These extensive results demonstrate that DiT can serve as versatile backbones for various vision tasks.
Distilling Knowledge from Self-Supervised Teacher by Embedding Graph Alignment
Nov 23, 2022



Recent advances have indicated the strengths of self-supervised pre-training for improving representation learning on downstream tasks. Existing works often utilize self-supervised pre-trained models by fine-tuning on downstream tasks. However, fine-tuning does not generalize to the case when one needs to build a customized model architecture different from the self-supervised model. In this work, we formulate a new knowledge distillation framework to transfer the knowledge from self-supervised pre-trained models to any other student network by a novel approach named Embedding Graph Alignment. Specifically, inspired by the spirit of instance discrimination in self-supervised learning, we model the instance-instance relations by a graph formulation in the feature embedding space and distill the self-supervised teacher knowledge to a student network by aligning the teacher graph and the student graph. Our distillation scheme can be flexibly applied to transfer the self-supervised knowledge to enhance representation learning on various student networks. We demonstrate that our model outperforms multiple representative knowledge distillation methods on three benchmark datasets, including CIFAR100, STL10, and TinyImageNet. Code is here: https://github.com/yccm/EGA.
Generalized Few-Shot Object Detection without Forgetting
May 20, 2021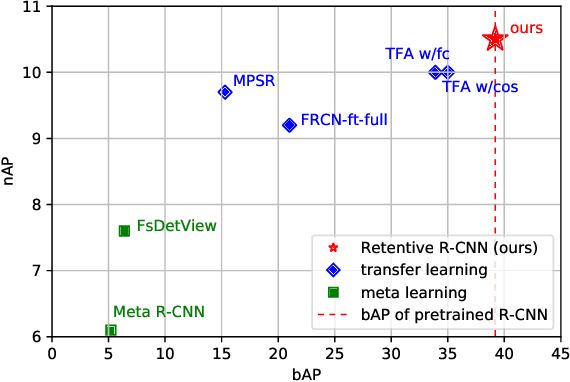
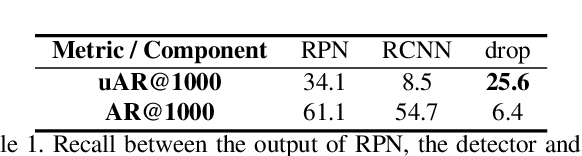
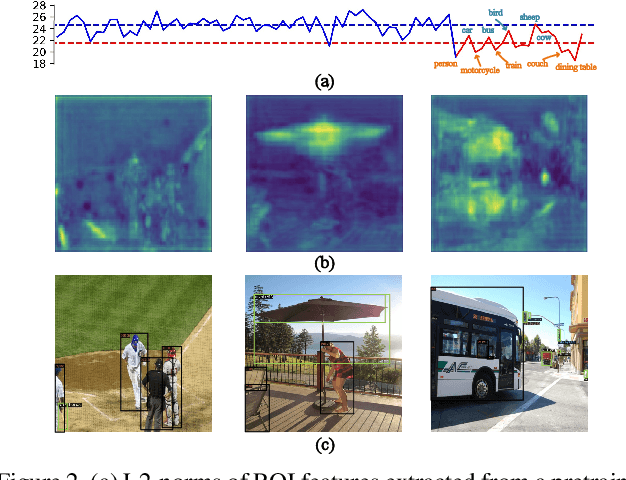

Recently few-shot object detection is widely adopted to deal with data-limited situations. While most previous works merely focus on the performance on few-shot categories, we claim that detecting all classes is crucial as test samples may contain any instances in realistic applications, which requires the few-shot detector to learn new concepts without forgetting. Through analysis on transfer learning based methods, some neglected but beneficial properties are utilized to design a simple yet effective few-shot detector, Retentive R-CNN. It consists of Bias-Balanced RPN to debias the pretrained RPN and Re-detector to find few-shot class objects without forgetting previous knowledge. Extensive experiments on few-shot detection benchmarks show that Retentive R-CNN significantly outperforms state-of-the-art methods on overall performance among all settings as it can achieve competitive results on few-shot classes and does not degrade the base class performance at all. Our approach has demonstrated that the long desired never-forgetting learner is available in object detection.