 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Large Scale Real-World Multi-Person Tracking
Nov 03, 2022This paper presents a new large scale multi-person tracking dataset -- \texttt{PersonPath22}, which is over an order of magnitude larger than currently available high quality multi-object tracking datasets such as MOT17, HiEve, and MOT20 datasets. The lack of large scale training and test data for this task has limited the community's ability to understand the performance of their tracking systems on a wide range of scenarios and conditions such as variations in person density, actions being performed, weather, and time of day. \texttt{PersonPath22} dataset was specifically sourced to provide a wide variety of these conditions and our annotations include rich meta-data such that the performance of a tracker can be evaluated along these different dimensions. The lack of training data has also limited the ability to perform end-to-end training of tracking systems. As such, the highest performing tracking systems all rely on strong detectors trained on external image datasets. We hope that the release of this dataset will enable new lines of research that take advantage of large scale video based training data.
Multi-Object Tracking with Hallucinated and Unlabeled Videos
Aug 19, 2021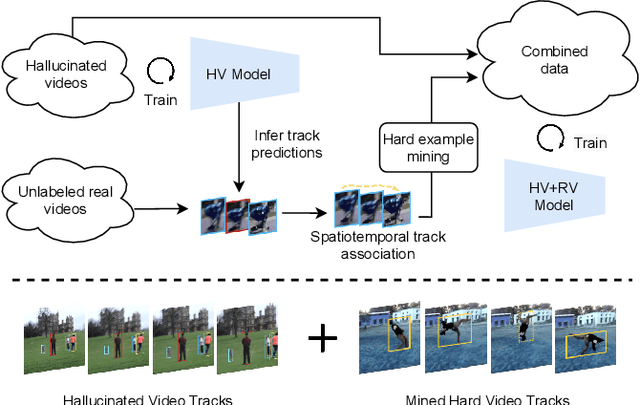
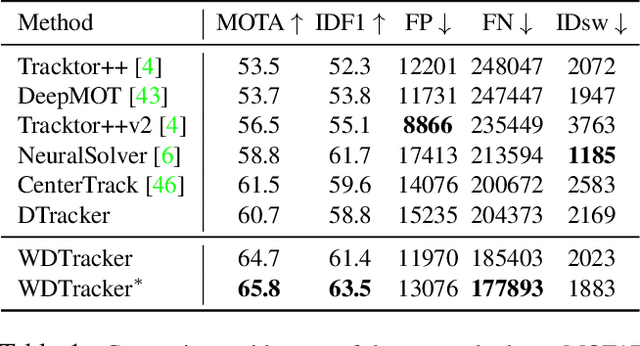


In this paper, we explore learning end-to-end deep neural trackers without tracking annotations. This is important as large-scale training data is essential for training deep neural trackers while tracking annotations are expensive to acquire. In place of tracking annotations, we first hallucinate videos from images with bounding box annotations using zoom-in/out motion transformations to obtain free tracking labels. We add video simulation augmentations to create a diverse tracking dataset, albeit with simple motion. Next, to tackle harder tracking cases, we mine hard examples across an unlabeled pool of real videos with a tracker trained on our hallucinated video data. For hard example mining, we propose an optimization-based connecting process to first identify and then rectify hard examples from the pool of unlabeled videos. Finally, we train our tracker jointly on hallucinated data and mined hard video examples. Our weakly supervised tracker achieves state-of-the-art performance on the MOT17 and TAO-person datasets. On MOT17, we further demonstrate that the combination of our self-generated data and the existing manually-annotated data leads to additional improvements.
SiamMOT: Siamese Multi-Object Tracking
May 25, 2021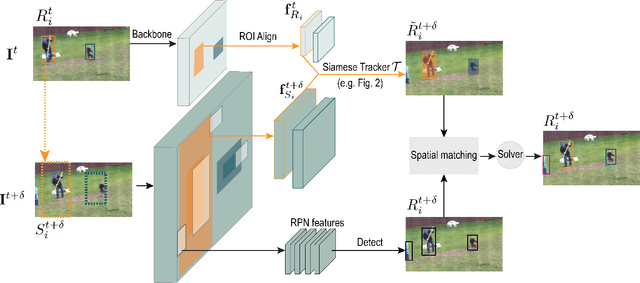

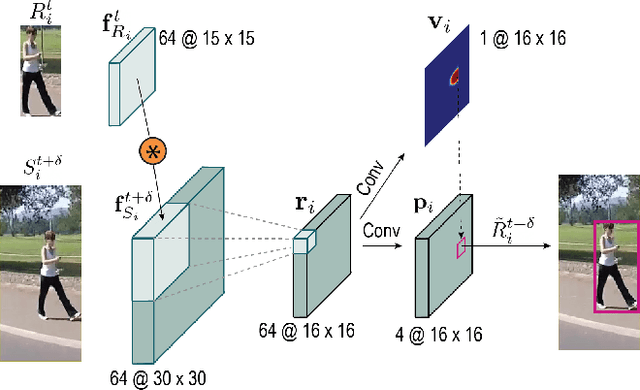
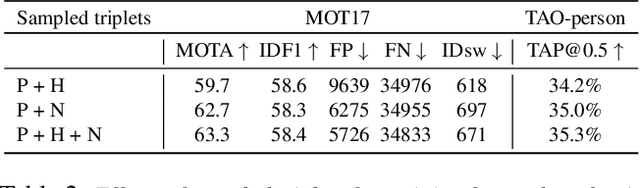
In this paper, we focus on improving online multi-object tracking (MOT). In particular, we introduce a region-based Siamese Multi-Object Tracking network, which we name SiamMOT. SiamMOT includes a motion model that estimates the instance's movement between two frames such that detected instances are associated. To explore how the motion modelling affects its tracking capability, we present two variants of Siamese tracker, one that implicitly models motion and one that models it explicitly. We carry out extensive quantitative experiments on three different MOT datasets: MOT17, TAO-person and Caltech Roadside Pedestrians, showing the importance of motion modelling for MOT and the ability of SiamMOT to substantially outperform the state-of-the-art. Finally, SiamMOT also outperforms the winners of ACM MM'20 HiEve Grand Challenge on HiEve dataset. Moreover, SiamMOT is efficient, and it runs at 17 FPS for 720P videos on a single modern GPU. Codes are available in \url{https://github.com/amazon-research/siam-mot}.