 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinate-wise Control Variates for Deep Policy Gradients
Paper and Code
Aug 11, 2021

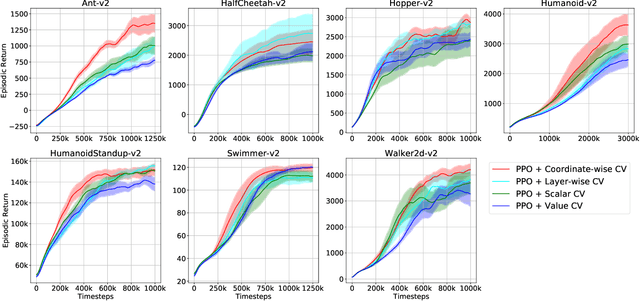

The control variates (CV) method is widely used in policy gradient estimation to reduce the variance of the gradient estimators in practice. A control variate is applied by subtracting a baseline function from the state-action value estimates. Then the variance-reduced policy gradient presumably leads to higher learning efficiency. Recent research on control variates with deep neural net policies mainly focuses on scalar-valued baseline functions. The effect of vector-valued baselines is under-explored. This paper investigates variance reduction with coordinate-wise and layer-wise control variates constructed from vector-valued baselines for neural net policies. We present experimental evidence suggesting that lower variance can be obtained with such baselines than with the conventional scalar-valued baseline. We demonstrate how to equip the popular Proximal Policy Optimization (PPO) algorithm with these new control variates. We show that the resulting algorithm with proper regularization can achieve higher sample efficiency than scalar control variates in continuous control benchmarks.