 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpertNet: A Symbiosis of Classification and Clustering
Jan 17, 2022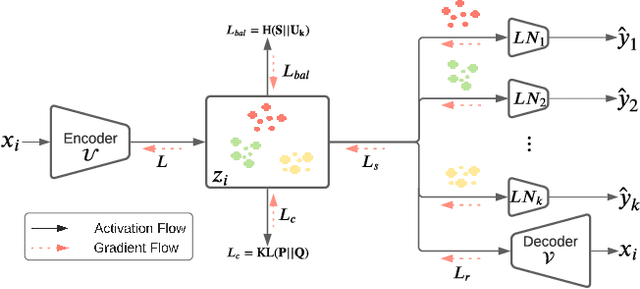
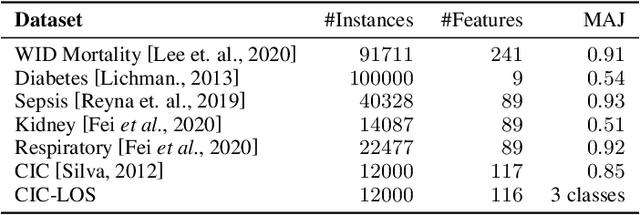

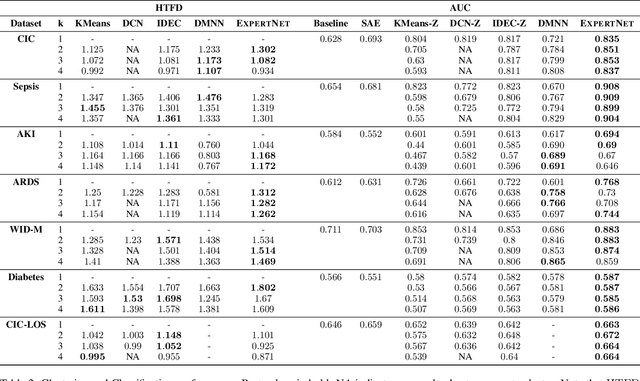
A widely used paradigm to improve the generalization performance of high-capacity neural models is through the addition of auxiliary unsupervised tasks during supervised training. Tasks such as similarity matching and input reconstruction have been shown to provide a beneficial regularizing effect by guiding representation learning. Real data often has complex underlying structures and may be composed of heterogeneous subpopulations that are not learned well with current approaches. In this work, we design ExpertNet, which uses novel training strategies to learn clustered latent representations and leverage them by effectively combining cluster-specific classifiers. We theoretically analyze the effect of clustering on its generalization gap, and empirically show that clustered latent representations from ExpertNet lead to disentangling the intrinsic structure and improvement in classification performance. ExpertNet also meets an important real-world need where classifiers need to be tailored for distinct subpopulations, such as in clinical risk models. We demonstrate the superiority of ExpertNet over state-of-the-art methods on 6 large clinical datasets, where our approach leads to valuable insights on group-specific risks.
MemStream: Memory-Based Anomaly Detection in Multi-Aspect Streams with Concept Drift
Jun 07, 2021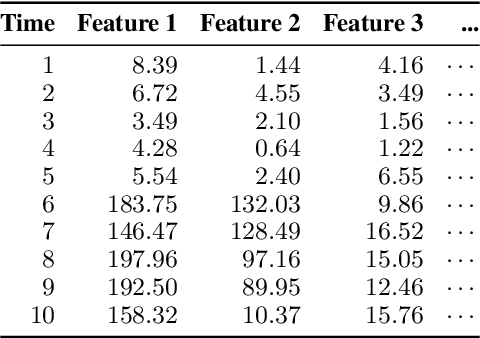
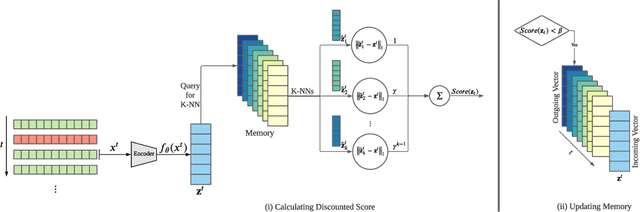
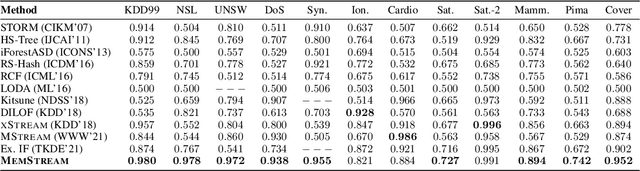
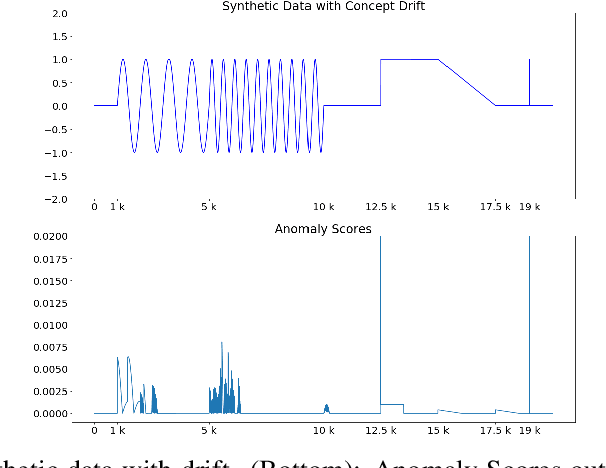
Given a stream of entries over time in a multi-aspect data setting where concept drift is present, how can we detect anomalous activities? Most of the existing unsupervised anomaly detection approaches seek to detect anomalous events in an offline fashion and require a large amount of data for training. This is not practical in real-life scenarios where we receive the data in a streaming manner and do not know the size of the stream beforehand. Thus, we need a data-efficient method that can detect and adapt to changing data trends, or concept drift, in an online manner. In this work, we propose MemStream, a streaming multi-aspect anomaly detection framework, allowing us to detect unusual events as they occur while being resilient to concept drift. We leverage the power of a denoising autoencoder to learn representations and a memory module to learn the dynamically changing trend in data without the need for labels. We prove the optimum memory size required for effective drift handling. Furthermore, MemStream makes use of two architecture design choices to be robust to memory poisoning. Experimental results show the effectiveness of our approach compared to state-of-the-art streaming baselines using 2 synthetic datasets and 11 real-world datasets.
CAC: A Clustering Based Framework for Classification
Feb 23, 2021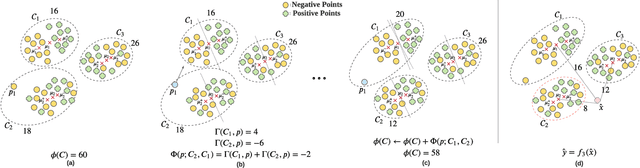
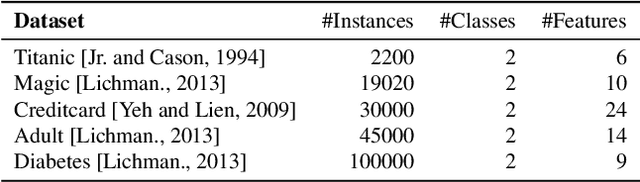
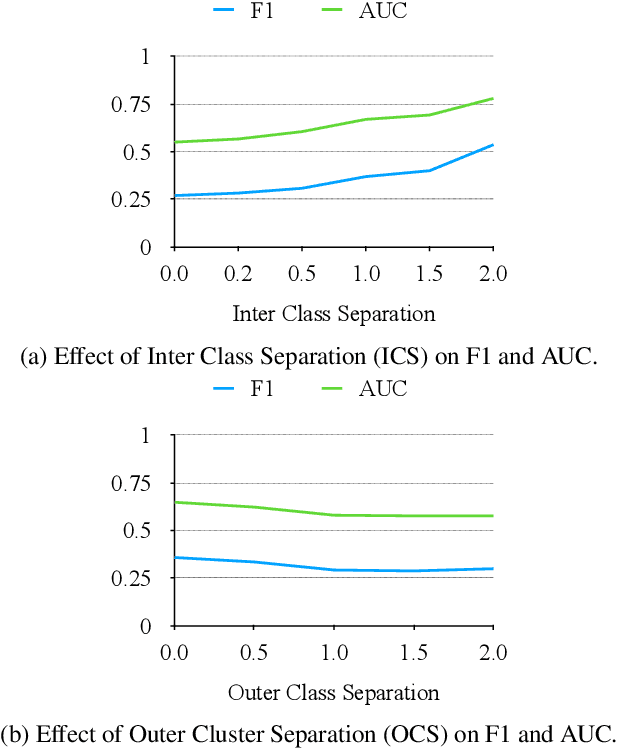
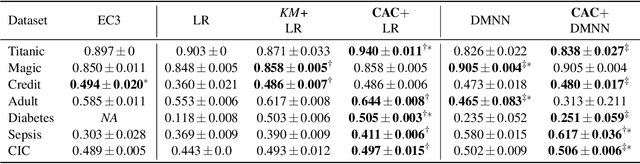
In data containing heterogeneous subpopulations, classification performance benefits from incorporating the knowledge of cluster structure in the classifier. Previous methods for such combined clustering and classification either are classifier-specific and not generic or independently perform clustering and classifier training, which may not form clusters that can potentially benefit classifier performance. The question of how to perform clustering to improve the performance of classifiers trained on the clusters has received scant attention in previous literature despite its importance in several real-world applications. In this paper, we theoretically analyze when and how clustering may help in obtaining accurate classifiers. We design a simple, efficient, and generic framework called Classification Aware Clustering (CAC), to find clusters that are well suited for being used as training datasets by classifiers for each underlying subpopulation. Our experiments on synthetic and real benchmark datasets demonstrate the efficacy of CAC over previous methods for combined clustering and classification.