 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSMF: Shifting Seasonal Matrix Factorization
Oct 25, 2021
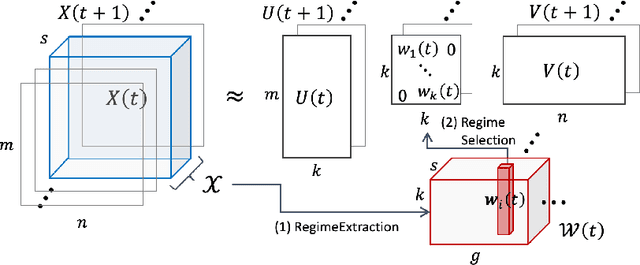

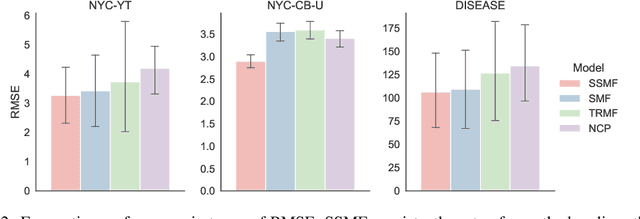
Given taxi-ride counts information between departure and destination locations, how can we forecast their future demands? In general, given a data stream of events with seasonal patterns that innovate over time, how can we effectively and efficiently forecast future events? In this paper, we propose Shifting Seasonal Matrix Factorization approach, namely SSMF, that can adaptively learn multiple seasonal patterns (called regimes), as well as switching between them. Our proposed method has the following properties: (a) it accurately forecasts future events by detecting regime shifts in seasonal patterns as the data stream evolves; (b) it works in an online setting, i.e., processes each observation in constant time and memory; (c) it effectively realizes regime shifts without human intervention by using a lossless data compression scheme. We demonstrate that our algorithm outperforms state-of-the-art baseline methods by accurately forecasting upcoming events on three real-world data streams.
Sketch-Based Streaming Anomaly Detection in Dynamic Graphs
Jun 08, 2021
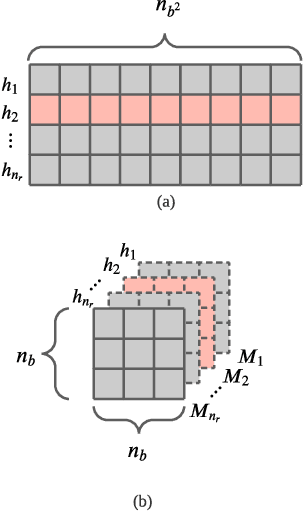
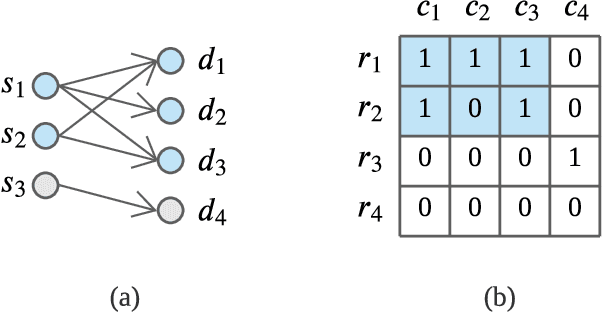

Given a stream of graph edges from a dynamic graph, how can we assign anomaly scores to edges and subgraphs in an online manner, for the purpose of detecting unusual behavior, using constant time and memory? For example, in intrusion detection, existing work seeks to detect either anomalous edges or anomalous subgraphs, but not both. In this paper, we first extend the count-min sketch data structure to a higher-order sketch. This higher-order sketch has the useful property of preserving the dense subgraph structure (dense subgraphs in the input turn into dense submatrices in the data structure). We then propose four online algorithms that utilize this enhanced data structure, which (a) detect both edge and graph anomalies; (b) process each edge and graph in constant memory and constant update time per newly arriving edge, and; (c) outperform state-of-the-art baselines on four real-world datasets. Our method is the first streaming approach that incorporates dense subgraph search to detect graph anomalies in constant memory and time.
Directed Graph Representation through Vector Cross Product
Oct 21, 2020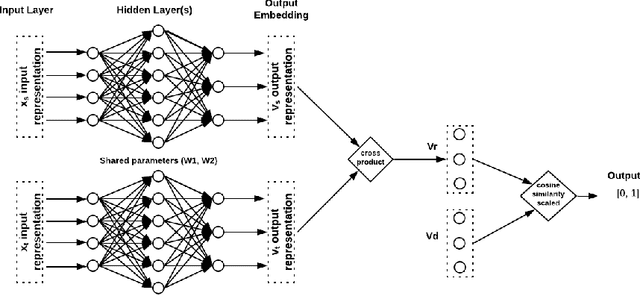
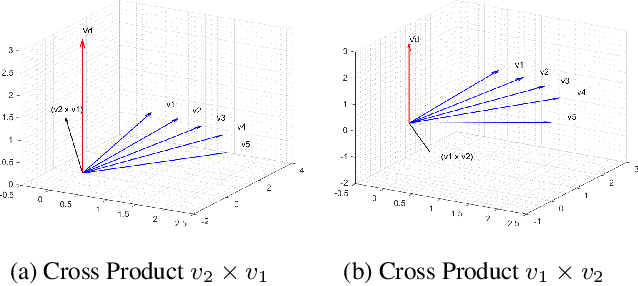
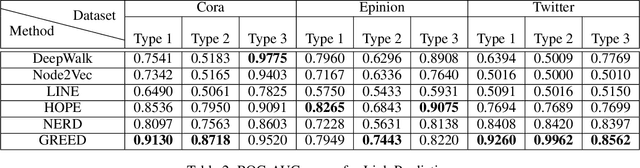
Graph embedding methods embed the nodes in a graph in low dimensional vector space while preserving graph topology to carry out the downstream tasks such as link prediction, node recommendation and clustering. These tasks depend on a similarity measure such as cosine similarity and Euclidean distance between a pair of embeddings that are symmetric in nature and hence do not hold good for directed graphs. Recent work on directed graphs, HOPE, APP, and NERD, proposed to preserve the direction of edges among nodes by learning two embeddings, source and target, for every node. However, these methods do not take into account the properties of directed edges explicitly. To understand the directional relation among nodes, we propose a novel approach that takes advantage of the non commutative property of vector cross product to learn embeddings that inherently preserve the direction of edges among nodes. We learn the node embeddings through a Siamese neural network where the cross-product operation is incorporated into the network architecture. Although cross product between a pair of vectors is defined in three dimensional, the approach is extended to learn N dimensional embeddings while maintaining the non-commutative property. In our empirical experiments on three real-world datasets, we observed that even very low dimensional embeddings could effectively preserve the directional property while outperforming some of the state-of-the-art methods on link prediction and node recommendation tasks
Fairness-Aware Learning with Prejudice Free Representations
Feb 26, 2020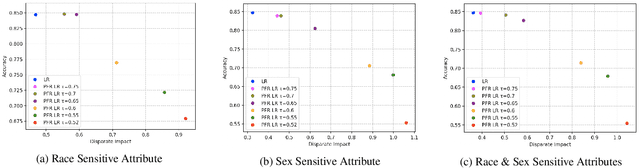
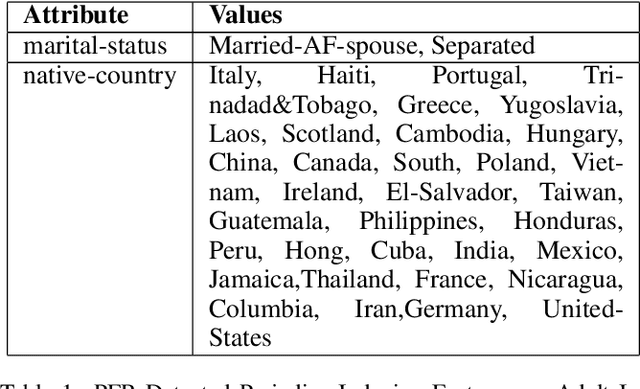
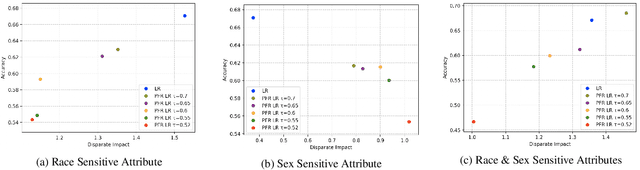
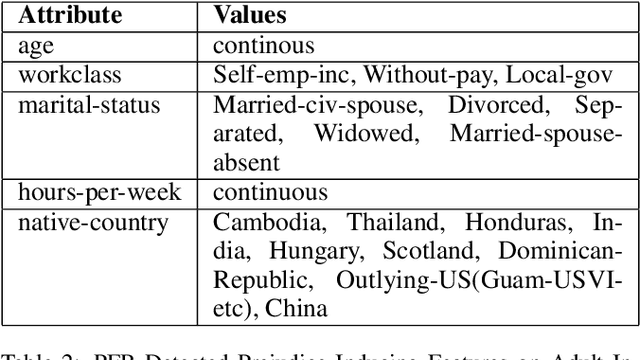
Machine learning models are extensively being used to make decisions that have a significant impact on human life. These models are trained over historical data that may contain information about sensitive attributes such as race, sex, religion, etc. The presence of such sensitive attributes can impact certain population subgroups unfairly. It is straightforward to remove sensitive features from the data; however, a model could pick up prejudice from latent sensitive attributes that may exist in the training data. This has led to the growing apprehension about the fairness of the employed models. In this paper, we propose a novel algorithm that can effectively identify and treat latent discriminating features. The approach is agnostic of the learning algorithm and generalizes well for classification as well as regression tasks. It can also be used as a key aid in proving that the model is free of discrimination towards regulatory compliance if the need arises. The approach helps to collect discrimination-free features that would improve the model performance while ensuring the fairness of the model. The experimental results from our evaluations on publicly available real-world datasets show a near-ideal fairness measurement in comparison to other methods.