 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Methods for the Noniterative Conditional Expectation G-Formula for Causal Inference from Complex Observational Data
Oct 28, 2024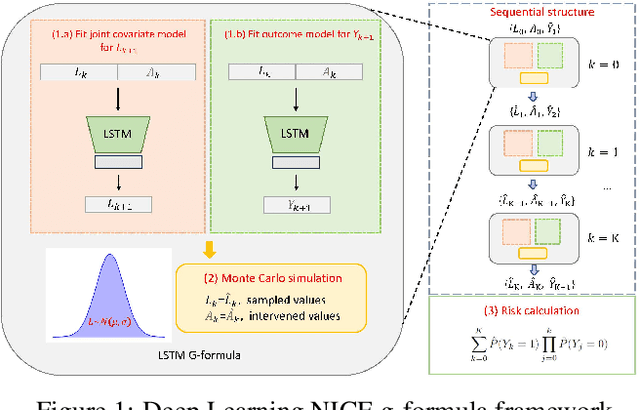

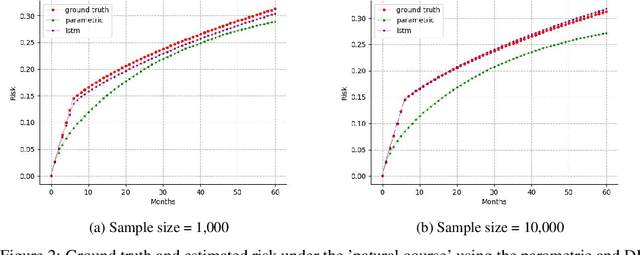

The g-formula can be used to estimate causal effects of sustained treatment strategies using observational data under the identifying assumptions of consistency, positivity, and exchangeability. The non-iterative conditional expectation (NICE) estimator of the g-formula also requires correct estimation of the conditional distribution of the time-varying treatment, confounders, and outcome. Parametric models, which have been traditionally used for this purpose, are subject to model misspecification, which may result in biased causal estimates. Here, we propose a unified deep learning framework for the NICE g-formula estimator that uses multitask recurrent neural networks for estimation of the joint conditional distributions. Using simulated data, we evaluated our model's bias and compared it with that of the parametric g-formula estimator. We found lower bias in the estimates of the causal effect of sustained treatment strategies on a survival outcome when using the deep learning estimator compared with the parametric NICE estimator in settings with simple and complex temporal dependencies between covariates. These findings suggest that our Deep Learning g-formula estimator may be less sensitive to model misspecification than the classical parametric NICE estimator when estimating the causal effect of sustained treatment strategies from complex observational data.
Large Language Models in Mental Health Care: a Scoping Review
Jan 01, 2024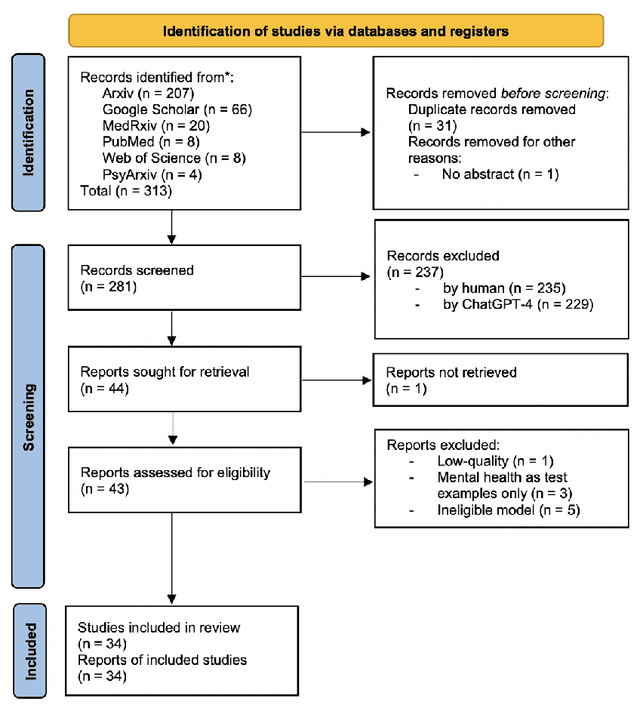
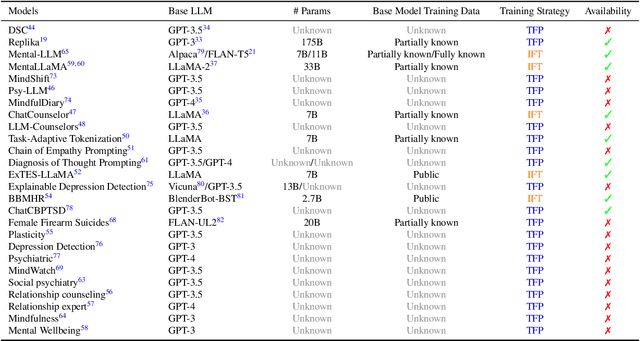
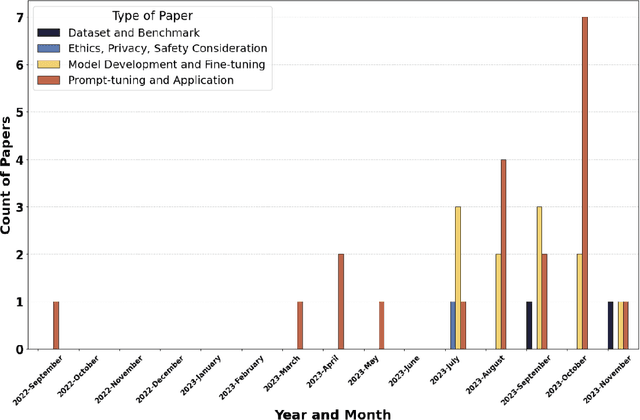
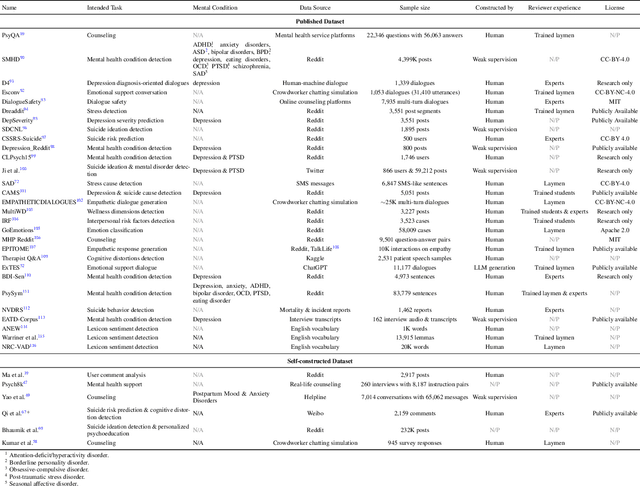
Objective: The growing use of large language models (LLMs) stimulates a need for a comprehensive review of their applications and outcomes in mental health care contexts. This scoping review aims to critically analyze the existing development and applications of LLMs in mental health care, highlighting their successes and identifying their challenges and limitations in these specialized fields. Materials and Methods: A broad literature search was conducted in November 2023 using six databases (PubMed, Web of Science, Google Scholar, arXiv, medRxiv, and PsyArXiv) following the 2020 version of the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. A total of 313 publications were initially identified, and after applying the study inclusion criteria, 34 publications were selected for the final review. Results: We identified diverse applications of LLMs in mental health care, including diagnosis, therapy, patient engagement enhancement, etc. Key challenges include data availability and reliability, nuanced handling of mental states, and effective evaluation methods. Despite successes in accuracy and accessibility improvement, gaps in clinical applicability and ethical considerations were evident, pointing to the need for robust data, standardized evaluations, and interdisciplinary collaboration. Conclusion: LLMs show promising potential in advancing mental health care, with applications in diagnostics, and patient support. Continued advancements depend on collaborative, multidisciplinary efforts focused on framework enhancement, rigorous dataset development, technological refinement, and ethical integration to ensure the effective and safe application of LLMs in mental health care.
Labrador: Exploring the Limits of Masked Language Modeling for Laboratory Data
Dec 09, 2023
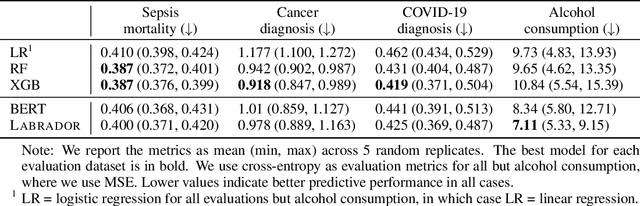


In this work we introduce Labrador, a pre-trained Transformer model for laboratory data. Labrador and BERT were pre-trained on a corpus of 100 million lab test results from electronic health records (EHRs) and evaluated on various downstream outcome prediction tasks. Both models demonstrate mastery of the pre-training task but neither consistently outperform XGBoost on downstream supervised tasks. Our ablation studies reveal that transfer learning shows limited effectiveness for BERT and achieves marginal success with Labrador. We explore the reasons for the failure of transfer learning and suggest that the data generating process underlying each patient cannot be characterized sufficiently using labs alone, among other factors. We encourage future work to focus on joint modeling of multiple EHR data categories and to include tree-based baselines in their evaluations.
Conformal Prediction with Large Language Models for Multi-Choice Question Answering
Jun 01, 2023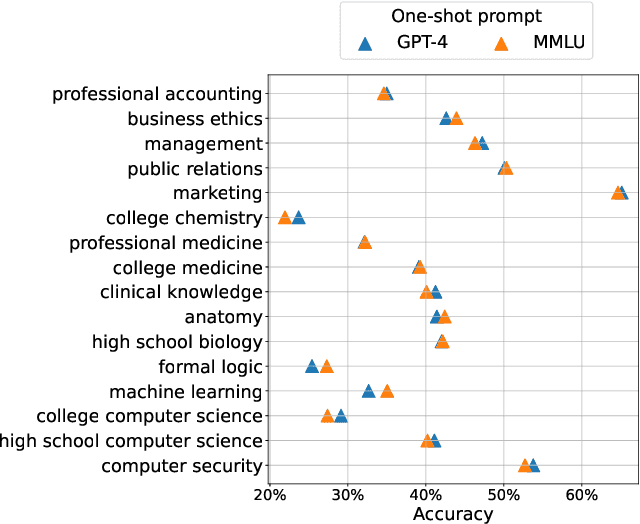
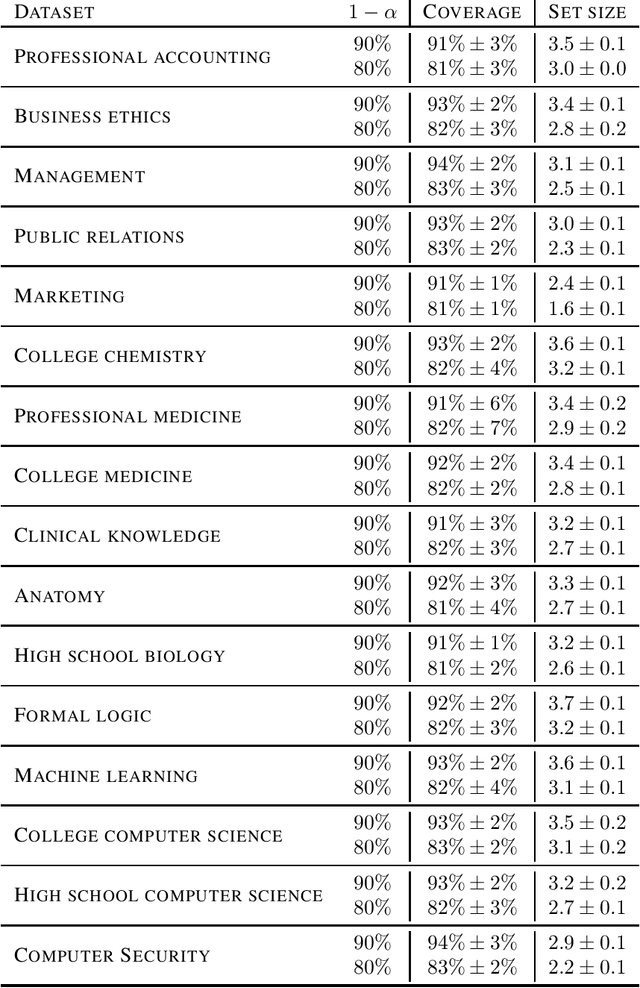
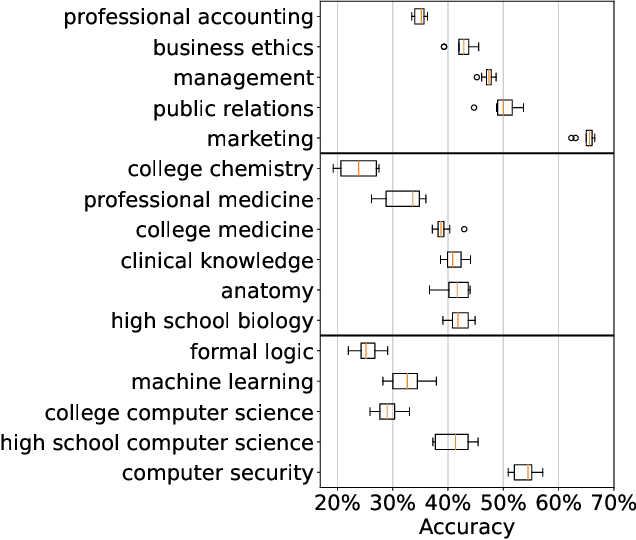
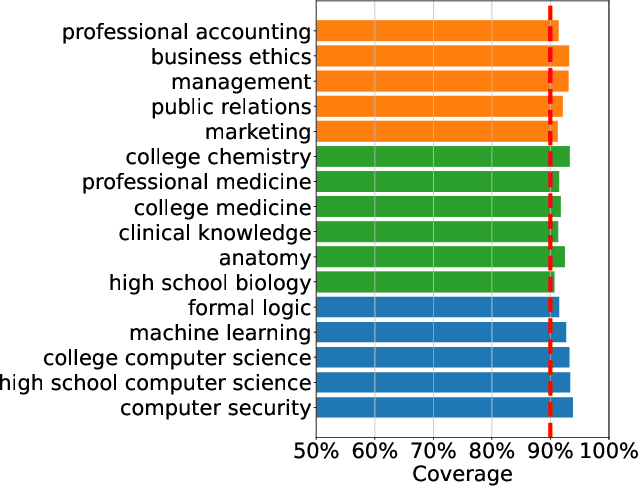
As large language models continue to be widely developed, robust uncertainty quantification techniques will become crucial for their safe deployment in high-stakes scenarios. In this work, we explore how conformal prediction can be used to provide uncertainty quantification in language models for the specific task of multiple-choice question-answering. We find that the uncertainty estimates from conformal prediction are tightly correlated with prediction accuracy. This observation can be useful for downstream applications such as selective classification and filtering out low-quality predictions. We also investigate the exchangeability assumption required by conformal prediction to out-of-subject questions, which may be a more realistic scenario for many practical applications. Our work contributes towards more trustworthy and reliable usage of large language models in safety-critical situations, where robust guarantees of error rate are required.
Towards Reliable Zero Shot Classification in Self-Supervised Models with Conformal Prediction
Oct 27, 2022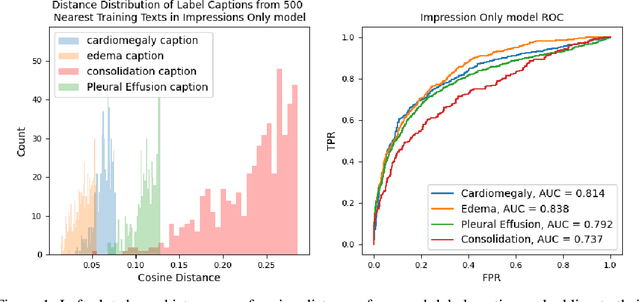
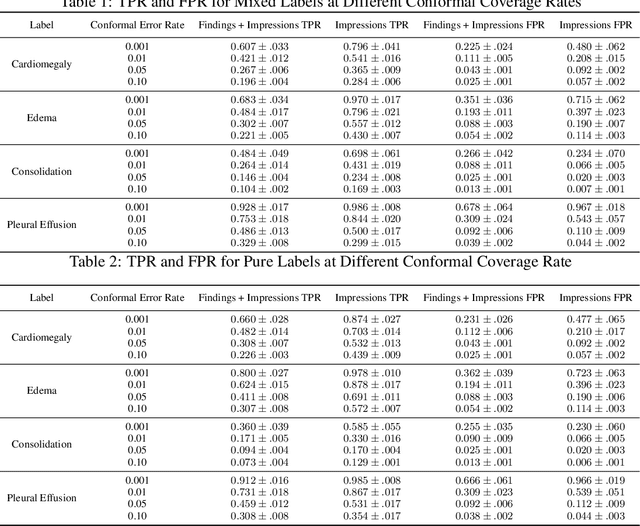
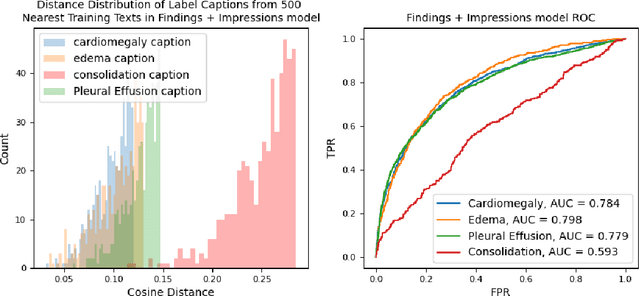

Self-supervised models trained with a contrastive loss such as CLIP have shown to be very powerful in zero-shot classification settings. However, to be used as a zero-shot classifier these models require the user to provide new captions over a fixed set of labels at test time. In many settings, it is hard or impossible to know if a new query caption is compatible with the source captions used to train the model. We address these limitations by framing the zero-shot classification task as an outlier detection problem and develop a conformal prediction procedure to assess when a given test caption may be reliably used. On a real-world medical example, we show that our proposed conformal procedure improves the reliability of CLIP-style models in the zero-shot classification setting, and we provide an empirical analysis of the factors that may affect its performance.
Coarse-to-Fine Memory Matching for Joint Retrieval and Classification
Nov 29, 2020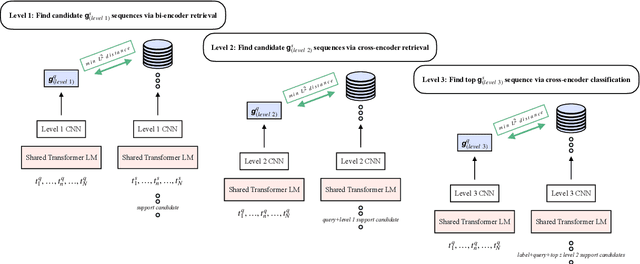
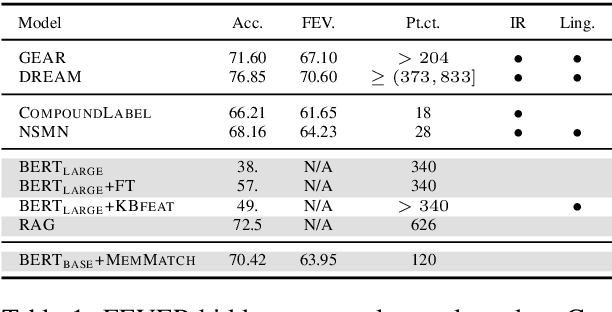
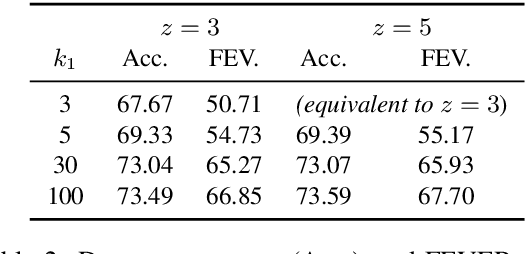
We present a novel end-to-end language model for joint retrieval and classification, unifying the strengths of bi- and cross- encoders into a single language model via a coarse-to-fine memory matching search procedure for learning and inference. Evaluated on the standard blind test set of the FEVER fact verification dataset, classification accuracy is significantly higher than approaches that only rely on the language model parameters as a knowledge base, and approaches some recent multi-model pipeline systems, using only a single BERT base model augmented with memory layers. We further demonstrate how coupled retrieval and classification can be leveraged to identify low confidence instances, and we extend exemplar auditing to this setting for analyzing and constraining the model. As a result, our approach yields a means of updating language model behavior through two distinct mechanisms: The retrieved information can be updated explicitly, and the model behavior can be modified via the exemplar database.
Empirical Frequentist Coverage of Deep Learning Uncertainty Quantification Procedures
Oct 06, 2020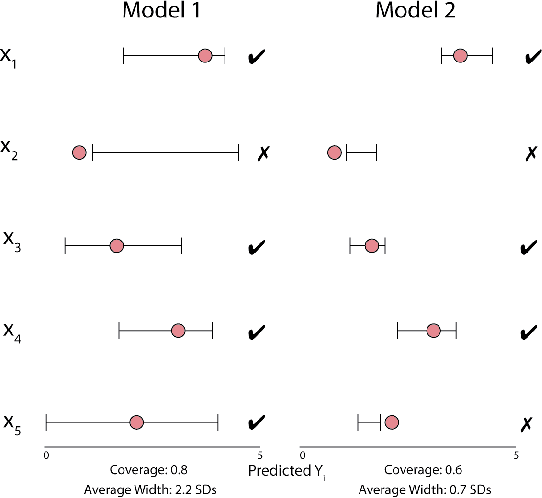
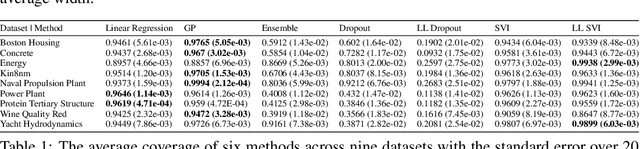

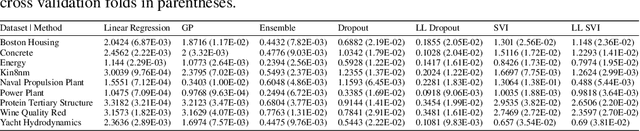
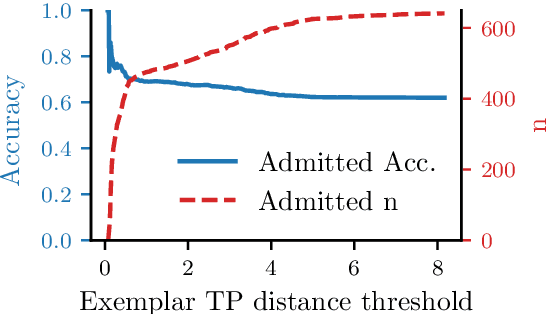
Uncertainty quantification for complex deep learning models is increasingly important as these techniques see growing use in high-stakes, real-world settings. Currently, the quality of a model's uncertainty is evaluated using point-prediction metrics such as negative log-likelihood or the Brier score on heldout data. In this study, we provide the first large scale evaluation of the empirical frequentist coverage properties of well known uncertainty quantification techniques on a suite of regression and classification tasks. We find that, in general, some methods do achieve desirable coverage properties on in distribution samples, but that coverage is not maintained on out-of-distribution data. Our results demonstrate the failings of current uncertainty quantification techniques as dataset shift increases and establish coverage as an important metric in developing models for real-world applications.
Exemplar Auditing for Multi-Label Biomedical Text Classification
Apr 07, 2020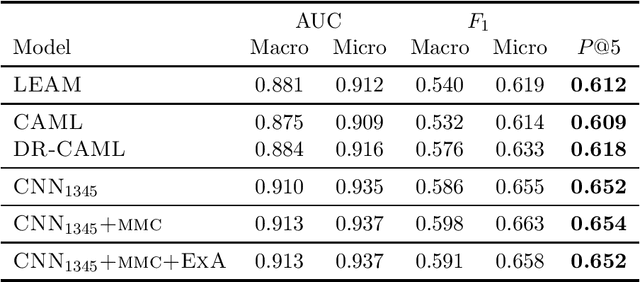
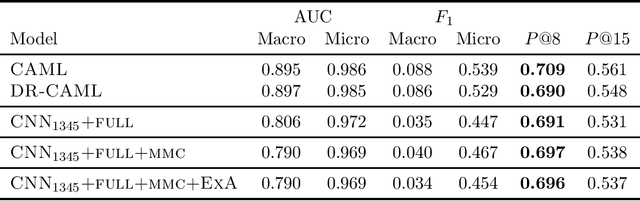
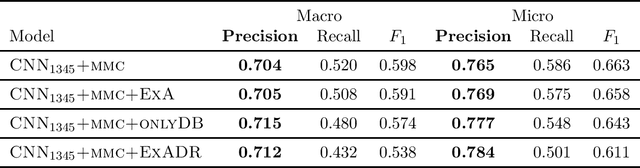
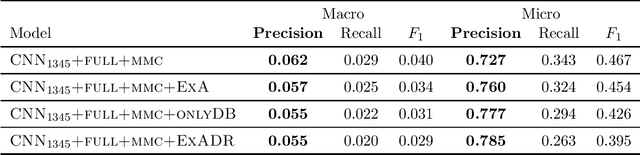
Many practical applications of AI in medicine consist of semi-supervised discovery: The investigator aims to identify features of interest at a resolution more fine-grained than that of the available human labels. This is often the scenario faced in healthcare applications as coarse, high-level labels (e.g., billing codes) are often the only sources that are readily available. These challenges are compounded for modalities such as text, where the feature space is very high-dimensional, and often contains considerable amounts of noise. In this work, we generalize a recently proposed zero-shot sequence labeling method, "binary labeling via a convolutional decomposition", to the case where the available document-level human labels are themselves relatively high-dimensional. The approach yields classification with "introspection", relating the fine-grained features of an inference-time prediction to their nearest neighbors from the training set, under the model. The approach is effective, yet parsimonious, as demonstrated on a well-studied MIMIC-III multi-label classification task of electronic health record data, and is useful as a tool for organizing the analysis of neural model predictions and high-dimensional datasets. Our proposed approach yields both a competitively effective classification model and an interrogation mechanism to aid healthcare workers in understanding the salient features that drive the model's predictions.