 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Methods for Proximal Inference via Maximum Moment Restriction
May 19, 2022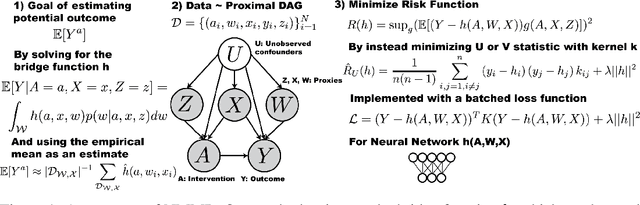

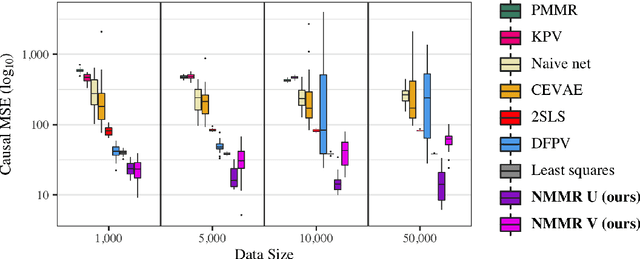
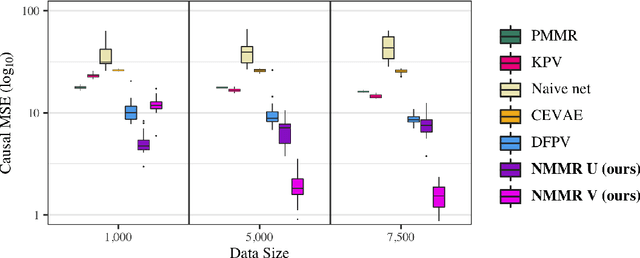
The No Unmeasured Confounding Assumption is widely used to identify causal effects in observational studies. Recent work on proximal inference has provided alternative identification results that succeed even in the presence of unobserved confounders, provided that one has measured a sufficiently rich set of proxy variables, satisfying specific structural conditions. However, proximal inference requires solving an ill-posed integral equation. Previous approaches have used a variety of machine learning techniques to estimate a solution to this integral equation, commonly referred to as the bridge function. However, prior work has often been limited by relying on pre-specified kernel functions, which are not data adaptive and struggle to scale to large datasets. In this work, we introduce a flexible and scalable method based on a deep neural network to estimate causal effects in the presence of unmeasured confounding using proximal inference. Our method achieves state of the art performance on two well-established proximal inference benchmarks. Finally, we provide theoretical consistency guarantees for our method.
Empirical Frequentist Coverage of Deep Learning Uncertainty Quantification Procedures
Oct 06, 2020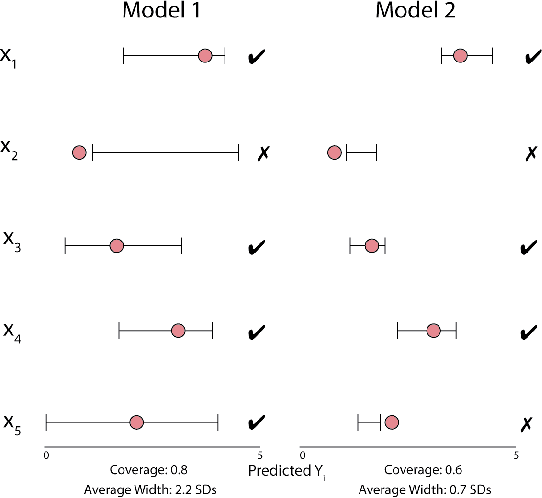
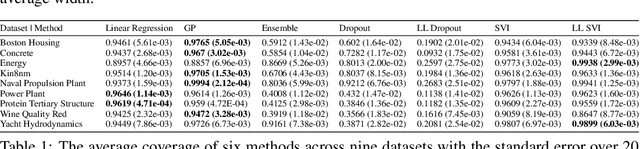

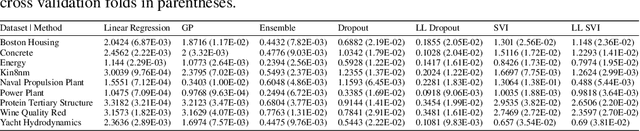
Uncertainty quantification for complex deep learning models is increasingly important as these techniques see growing use in high-stakes, real-world settings. Currently, the quality of a model's uncertainty is evaluated using point-prediction metrics such as negative log-likelihood or the Brier score on heldout data. In this study, we provide the first large scale evaluation of the empirical frequentist coverage properties of well known uncertainty quantification techniques on a suite of regression and classification tasks. We find that, in general, some methods do achieve desirable coverage properties on in distribution samples, but that coverage is not maintained on out-of-distribution data. Our results demonstrate the failings of current uncertainty quantification techniques as dataset shift increases and establish coverage as an important metric in developing models for real-world applications.
Learning a Generative Model of Cancer Metastasis
Jan 17, 2019
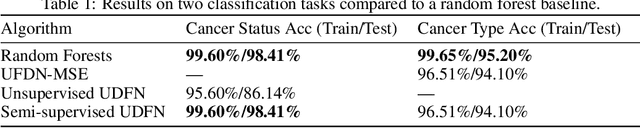
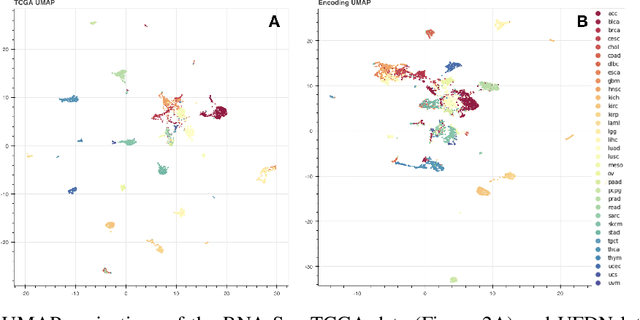

We introduce a Unified Disentanglement Network (UFDN) trained on The Cancer Genome Atlas (TCGA). We demonstrate that the UFDN learns a biologically relevant latent space of gene expression data by applying our network to two classification tasks of cancer status and cancer type. Our UFDN specific algorithms perform comparably to random forest methods. The UFDN allows for continuous, partial interpolation between distinct cancer types. Furthermore, we perform an analysis of differentially expressed genes between skin cutaneous melanoma(SKCM) samples and the same samples interpolated into glioblastoma (GBM). We demonstrate that our interpolations learn relevant metagenes that recapitulate known glioblastoma mechanisms and suggest possible starting points for investigations into the metastasis of SKCM into GBM.
Clinical Concept Embeddings Learned from Massive Sources of Multimodal Medical Data
May 18, 2018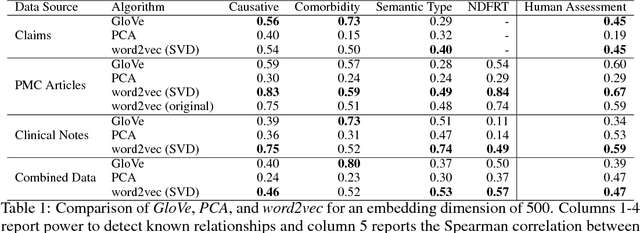
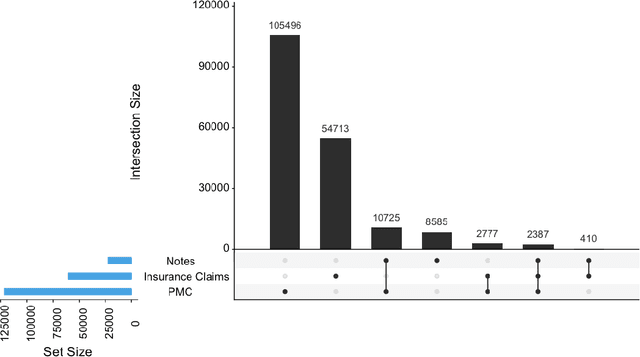

Word embeddings are a popular approach to unsupervised learning of word relationships that are widely used in natural language processing. In this article, we present a new set of embeddings for medical concepts learned using an extremely large collection of multimodal medical data. Leaning on recent theoretical insights, we demonstrate how an insurance claims database of 60 million members, a collection of 20 million clinical notes, and 1.7 million full text biomedical journal articles can be combined to embed concepts into a common space, resulting in the largest ever set of embeddings for 108,477 medical concepts. To evaluate our approach, we present a new benchmark methodology based on statistical power specifically designed to test embeddings of medical concepts. Our approach, called cui2vec, attains state of the art performance relative to previous methods in most instances. Finally, we provide a downloadable set of pre-trained embeddings for other researchers to use, as well as an online tool for interactive exploration of the cui2vec embeddings.