 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Prediction with Large Language Models for Multi-Choice Question Answering
Jun 01, 2023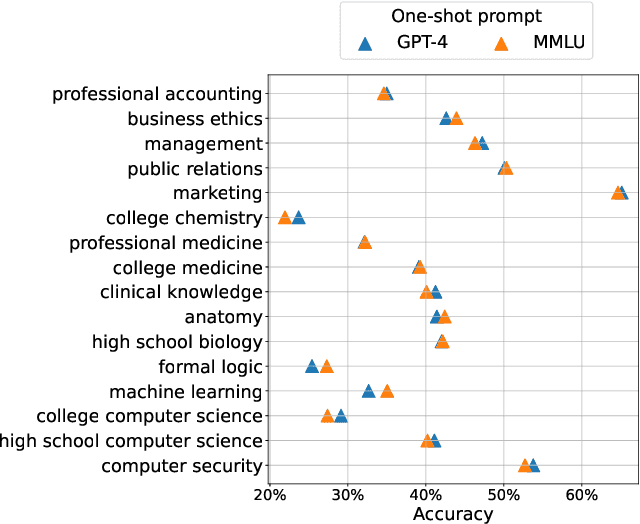
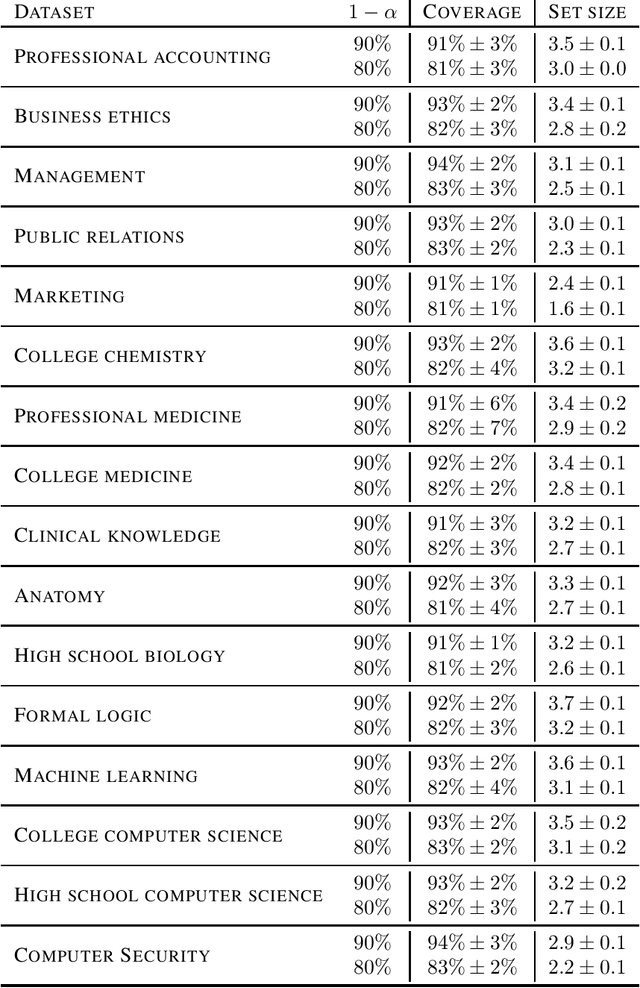
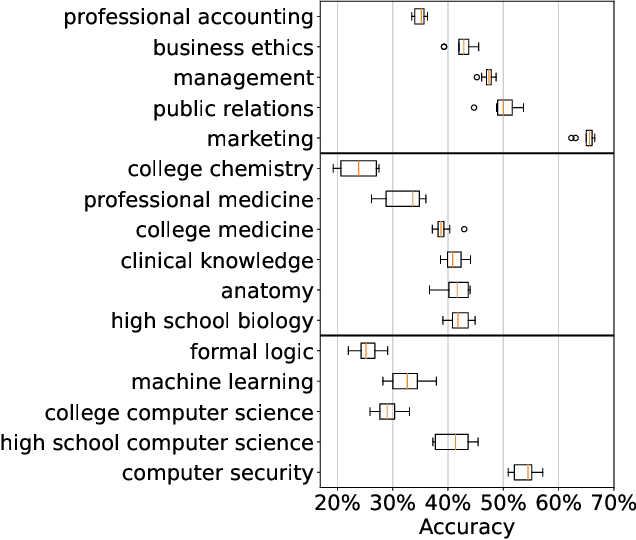
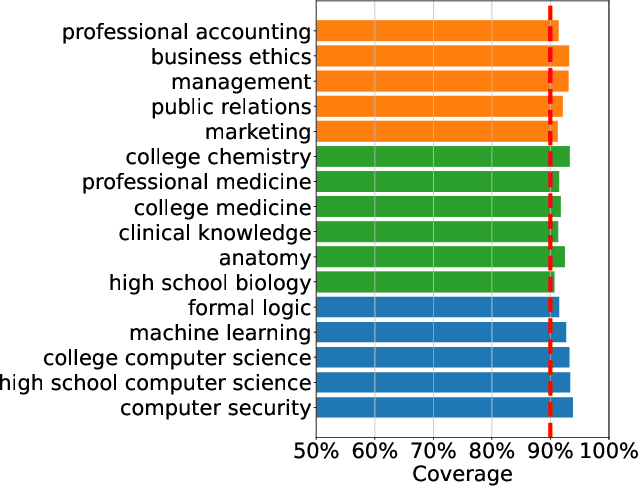
As large language models continue to be widely developed, robust uncertainty quantification techniques will become crucial for their safe deployment in high-stakes scenarios. In this work, we explore how conformal prediction can be used to provide uncertainty quantification in language models for the specific task of multiple-choice question-answering. We find that the uncertainty estimates from conformal prediction are tightly correlated with prediction accuracy. This observation can be useful for downstream applications such as selective classification and filtering out low-quality predictions. We also investigate the exchangeability assumption required by conformal prediction to out-of-subject questions, which may be a more realistic scenario for many practical applications. Our work contributes towards more trustworthy and reliable usage of large language models in safety-critical situations, where robust guarantees of error rate are required.
Evaluating Progress on Machine Learning for Longitudinal Electronic Healthcare Data
Oct 02, 2020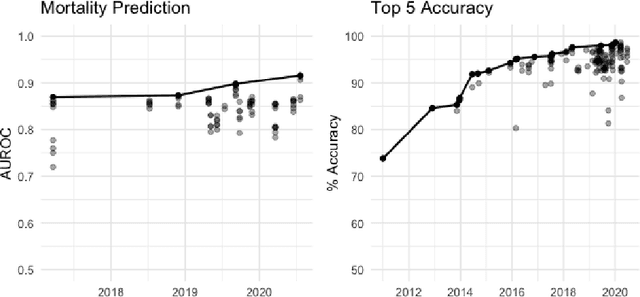
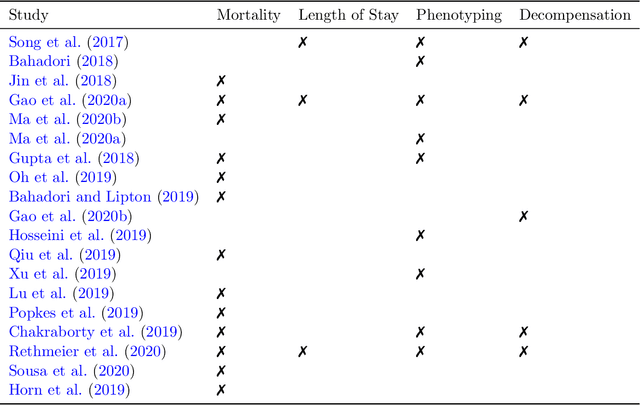
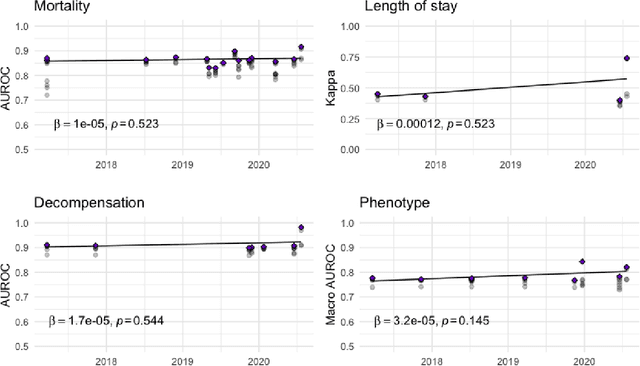

The Large Scale Visual Recognition Challenge based on the well-known Imagenet dataset catalyzed an intense flurry of progress in computer vision. Benchmark tasks have propelled other sub-fields of machine learning forward at an equally impressive pace, but in healthcare it has primarily been image processing tasks, such as in dermatology and radiology, that have experienced similar benchmark-driven progress. In the present study, we performed a comprehensive review of benchmarks in medical machine learning for structured data, identifying one based on the Medical Information Mart for Intensive Care (MIMIC-III) that allows the first direct comparison of predictive performance and thus the evaluation of progress on four clinical prediction tasks: mortality, length of stay, phenotyping, and patient decompensation. We find that little meaningful progress has been made over a 3 year period on these tasks, despite significant community engagement. Through our meta-analysis, we find that the performance of deep recurrent models is only superior to logistic regression on certain tasks. We conclude with a synthesis of these results, possible explanations, and a list of desirable qualities for future benchmarks in medical machine learning.