 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity-Distance-Magnitude Language Models
Oct 30, 2025We introduce Similarity-Distance-Magnitude (SDM) language models (LMs), which are sequence prediction models fine-tuned to maximize the proportion of generations in the well-calibrated, high-probability region partitioned by a final-layer SDM activation layer used for binary classification of instruction-following. We demonstrate that existing pre-trained decoder-only Transformer LMs can be readily converted into SDM LMs via supervised fine-tuning, using the final-layer SDM activation layer during training to estimate a change-of-base for a supervised next-token loss over a contrastive input encoding scheme, with additional hard negative examples generated online during training. This results in reduced abstentions (i.e., improved statistical efficiency) compared to strong supervised baselines.
Similarity-Distance-Magnitude Activations
Sep 16, 2025We introduce a more robust and interpretable formulation of the standard softmax activation function commonly used with neural networks by adding Similarity (i.e., correctly predicted depth-matches into training) awareness and Distance-to-training-distribution awareness to the existing output Magnitude (i.e., decision-boundary) awareness. When used as the final-layer activation with language models, the resulting Similarity-Distance-Magnitude (SDM) activation function is more robust than the softmax function to co-variate shifts and out-of-distribution inputs in high-probability regions, and provides interpretability-by-exemplar via dense matching. Complementing the prediction-conditional estimates, the SDM activation enables a partitioning of the class-wise empirical CDFs to guard against low class-wise recall among selective classifications. These properties make it preferable for selective classification, even when considering post-hoc calibration methods over the softmax.
Similarity-Distance-Magnitude Universal Verification
Feb 27, 2025We solve the neural network robustness problem by adding Similarity (i.e., correctly predicted depth-matches into training)-awareness and Distance-to-training-distribution-awareness to the existing output Magnitude (i.e., decision-boundary)-awareness of the softmax function. The resulting sdm activation function provides strong signals of the relative epistemic (reducible) predictive uncertainty. We use this novel behavior to further address the complementary HCI problem of mapping the output to human-interpretable summary statistics over relevant partitions of a held-out calibration set. Estimates of prediction-conditional uncertainty are obtained via a parsimonious learned transform over the class-conditional empirical CDFs of the output of a final-layer sdm activation function. For decision-making and as an intrinsic model check, estimates of class-conditional accuracy are obtained by further partitioning the high-probability regions of this calibrated output into class-conditional, region-specific CDFs. The uncertainty estimates from sdm calibration are remarkably robust to test-time distribution shifts and out-of-distribution inputs; incorporate awareness of the effective sample size; provide estimates of uncertainty from the learning and data splitting processes; and are well-suited for selective classification and conditional branching for additional test-time compute based on the predictive uncertainty, as for selective LLM generation, routing, and composition over multiple models and retrieval. Finally, we construct sdm networks, LLMs with uncertainty-aware verification and interpretability-by-exemplar as intrinsic properties. We provide open-source software implementing these results.
Approximate Conditional Coverage via Neural Model Approximations
May 28, 2022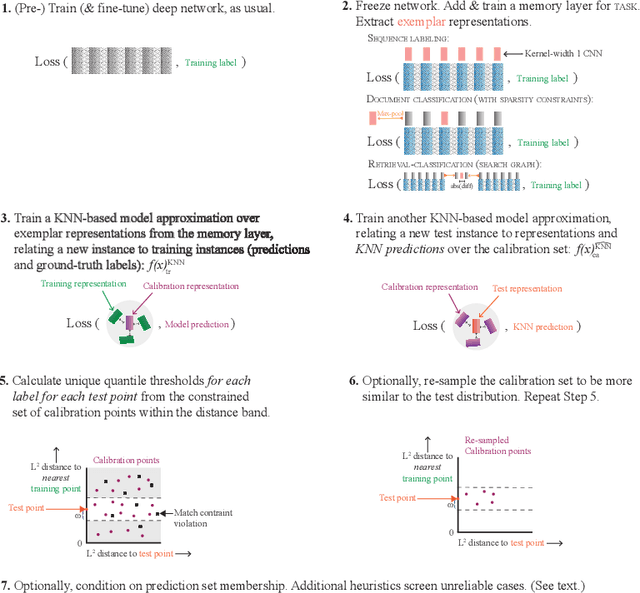


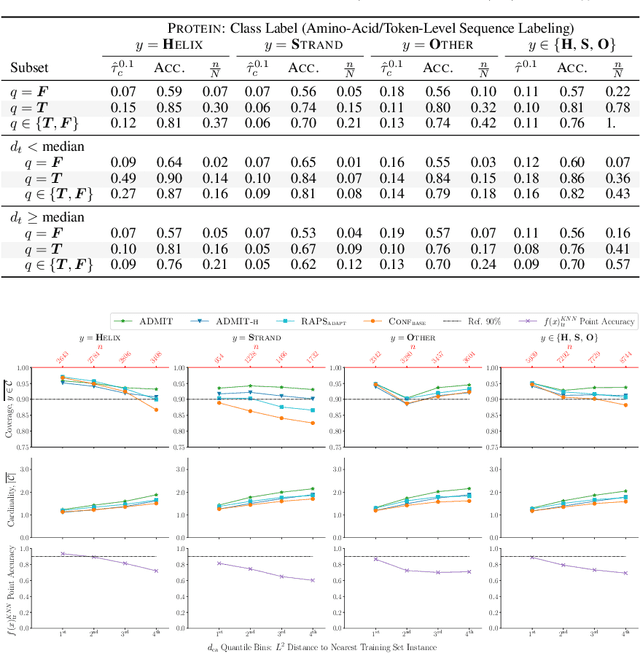
Constructing reliable prediction sets is an obstacle for applications of neural models: Distribution-free conditional coverage is theoretically impossible, and the exchangeability assumption underpinning the coverage guarantees of standard split-conformal approaches is violated on domain shifts. Given these challenges, we propose and analyze a data-driven procedure for obtaining empirically reliable approximate conditional coverage, calculating unique quantile thresholds for each label for each test point. We achieve this via the strong signals for prediction reliability from KNN-based model approximations over the training set and approximations over constrained samples from the held-out calibration set. We demonstrate the potential for substantial (and otherwise unknowable) under-coverage with split-conformal alternatives with marginal coverage guarantees when not taking these distances and constraints into account with protein secondary structure prediction, grammatical error detection, sentiment classification, and fact verification, covering supervised sequence labeling, zero-shot sequence labeling (i.e., feature detection), document classification (with sparsity/interpretability constraints), and retrieval-classification, including class-imbalanced and domain-shifted settings.
Coarse-to-Fine Memory Matching for Joint Retrieval and Classification
Nov 29, 2020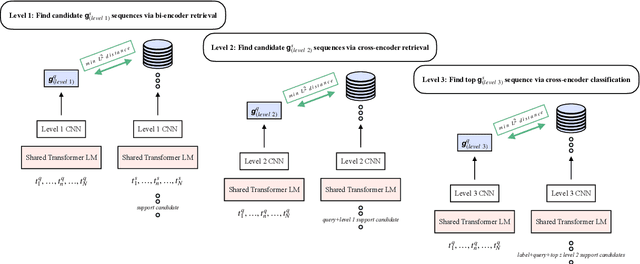
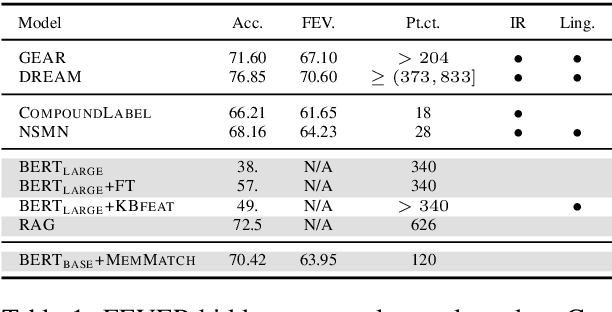
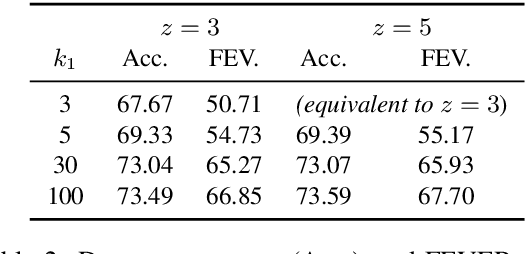
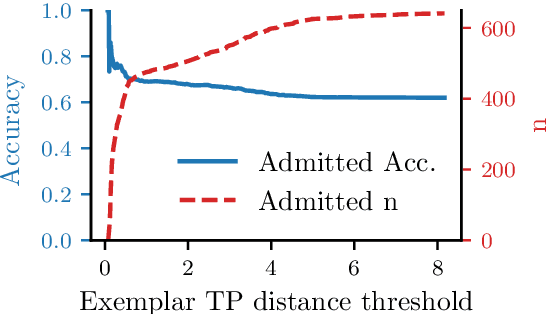
We present a novel end-to-end language model for joint retrieval and classification, unifying the strengths of bi- and cross- encoders into a single language model via a coarse-to-fine memory matching search procedure for learning and inference. Evaluated on the standard blind test set of the FEVER fact verification dataset, classification accuracy is significantly higher than approaches that only rely on the language model parameters as a knowledge base, and approaches some recent multi-model pipeline systems, using only a single BERT base model augmented with memory layers. We further demonstrate how coupled retrieval and classification can be leveraged to identify low confidence instances, and we extend exemplar auditing to this setting for analyzing and constraining the model. As a result, our approach yields a means of updating language model behavior through two distinct mechanisms: The retrieved information can be updated explicitly, and the model behavior can be modified via the exemplar database.
Exemplar Auditing for Multi-Label Biomedical Text Classification
Apr 07, 2020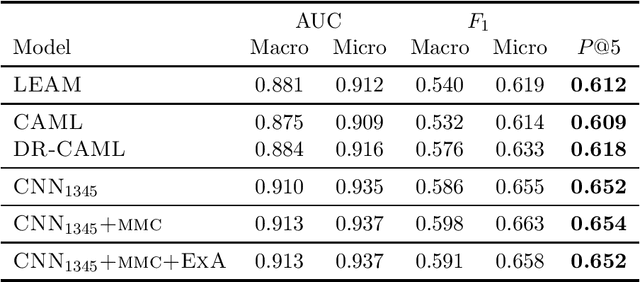
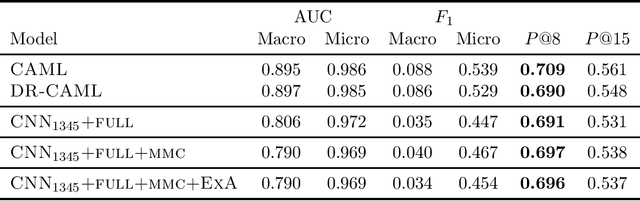
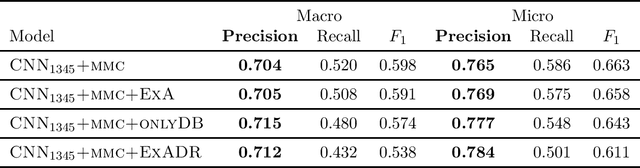
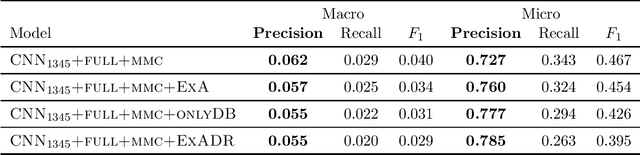
Many practical applications of AI in medicine consist of semi-supervised discovery: The investigator aims to identify features of interest at a resolution more fine-grained than that of the available human labels. This is often the scenario faced in healthcare applications as coarse, high-level labels (e.g., billing codes) are often the only sources that are readily available. These challenges are compounded for modalities such as text, where the feature space is very high-dimensional, and often contains considerable amounts of noise. In this work, we generalize a recently proposed zero-shot sequence labeling method, "binary labeling via a convolutional decomposition", to the case where the available document-level human labels are themselves relatively high-dimensional. The approach yields classification with "introspection", relating the fine-grained features of an inference-time prediction to their nearest neighbors from the training set, under the model. The approach is effective, yet parsimonious, as demonstrated on a well-studied MIMIC-III multi-label classification task of electronic health record data, and is useful as a tool for organizing the analysis of neural model predictions and high-dimensional datasets. Our proposed approach yields both a competitively effective classification model and an interrogation mechanism to aid healthcare workers in understanding the salient features that drive the model's predictions.
Toward Grammatical Error Detection from Sentence Labels: Zero-shot Sequence Labeling with CNNs and Contextualized Embeddings
Jun 04, 2019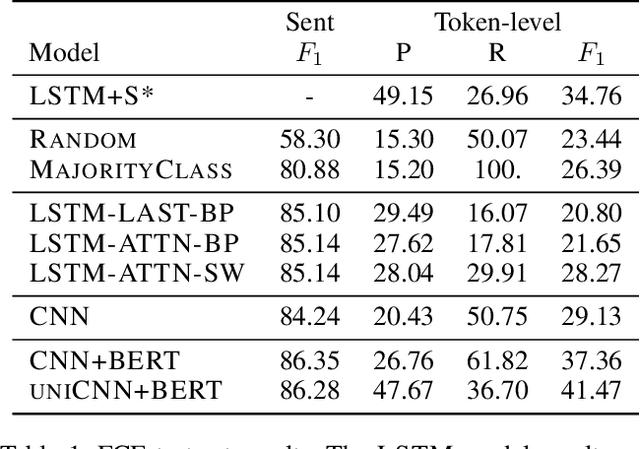
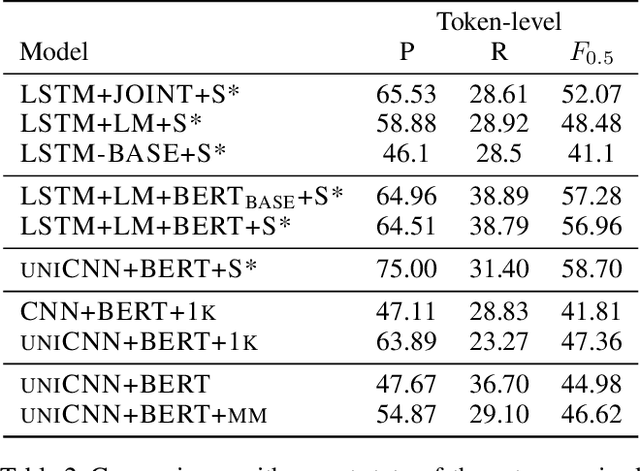
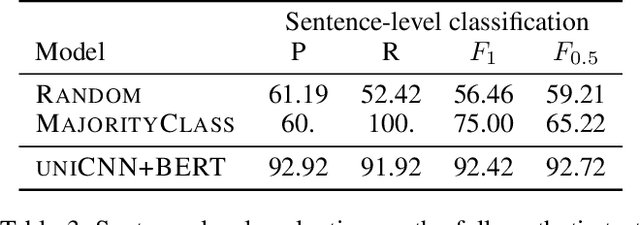
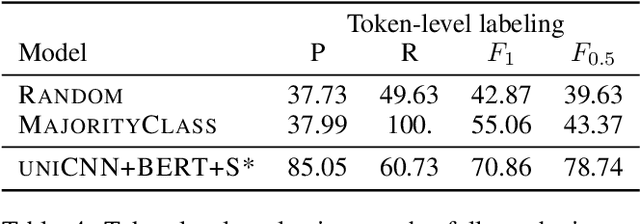
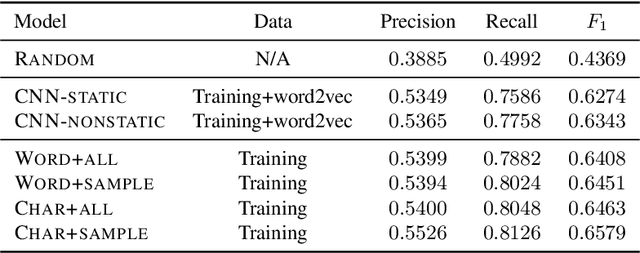
Zero-shot grammatical error detection is the task of tagging token-level errors in a sentence when only given access to labels at the sentence-level for training. Recent work has explored attention- and gradient-based approaches for the task. We extend this line of research to CNNs by analyzing a straightforward decomposition of the sentence-level classifier. Without modification to the underlying architecture, a single-layer CNN can be used to achieve similar F1 scores to a bi-LSTM attention-based approach specifically modified for the task of zero-shot labeling on the standard dataset, as a result of relatively strong recall, but weaker precision. Interestingly, with the advantage of pre-trained contextualized embeddings, this approach yields competitive F1 scores (and with a limited amount of token-labeled data for tuning, F0.5 scores) with baseline (but no longer state-of-the-art) fully supervised bi-LSTM models (using standard pre-trained word embeddings), despite only having access to sentence-level labels for training.
Adapting Sequence Models for Sentence Correction
Jul 27, 2017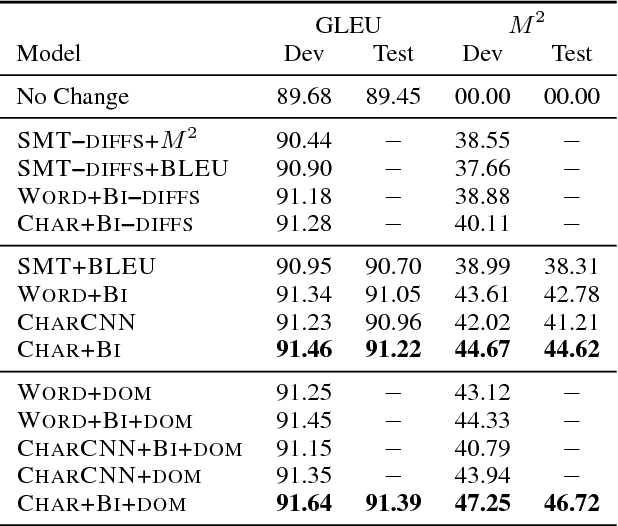
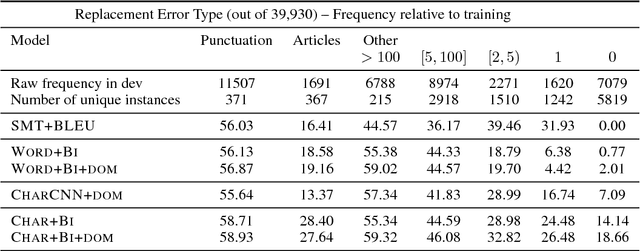
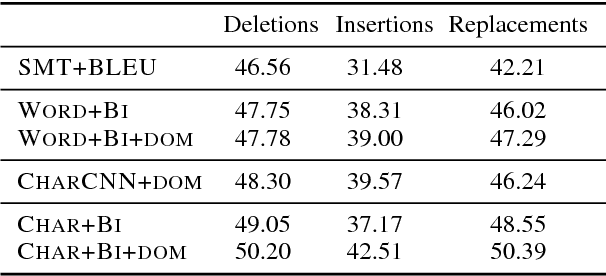
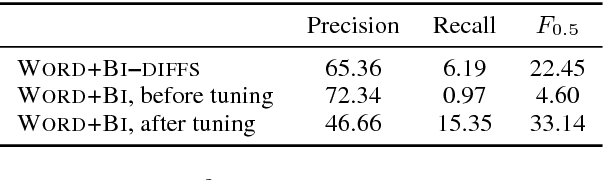
In a controlled experiment of sequence-to-sequence approaches for the task of sentence correction, we find that character-based models are generally more effective than word-based models and models that encode subword information via convolutions, and that modeling the output data as a series of diffs improves effectiveness over standard approaches. Our strongest sequence-to-sequence model improves over our strongest phrase-based statistical machine translation model, with access to the same data, by 6 M2 (0.5 GLEU) points. Additionally, in the data environment of the standard CoNLL-2014 setup, we demonstrate that modeling (and tuning against) diffs yields similar or better M2 scores with simpler models and/or significantly less data than previous sequence-to-sequence approaches.
Word Ordering Without Syntax
Sep 24, 2016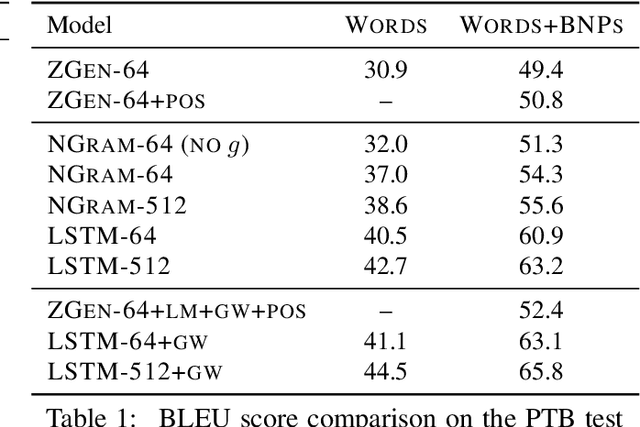
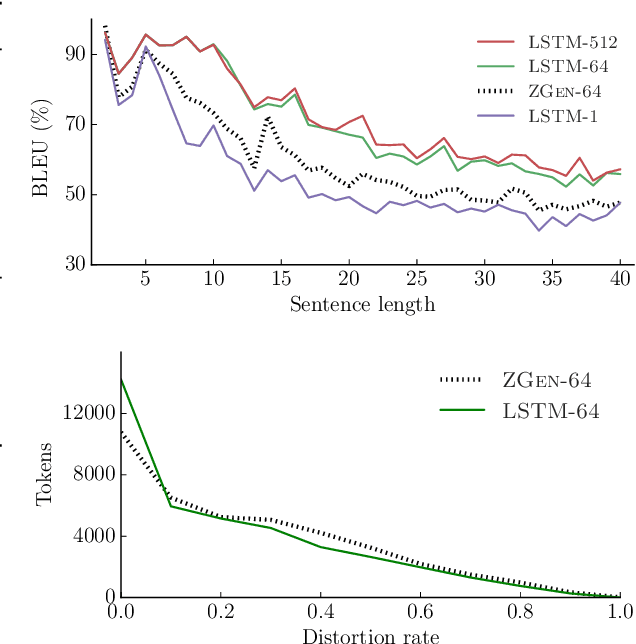
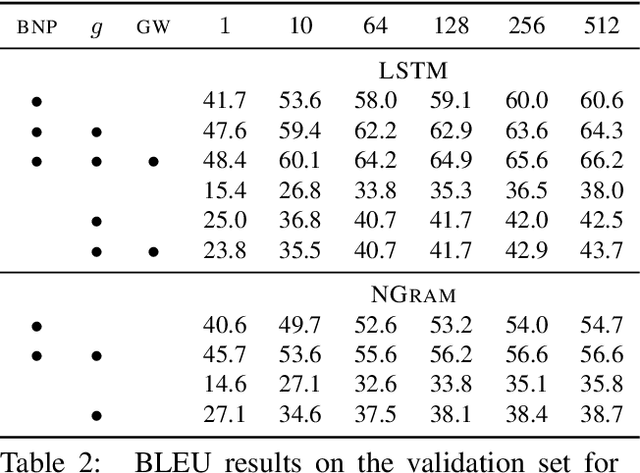
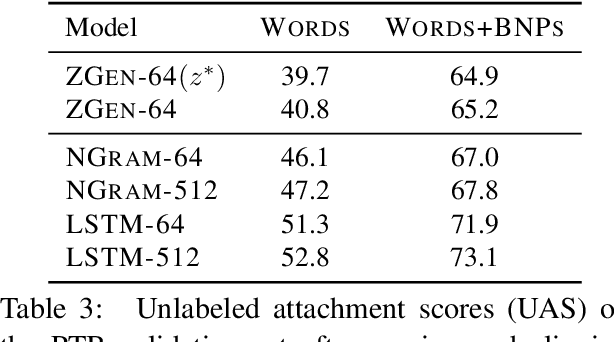
Recent work on word ordering has argued that syntactic structure is important, or even required, for effectively recovering the order of a sentence. We find that, in fact, an n-gram language model with a simple heuristic gives strong results on this task. Furthermore, we show that a long short-term memory (LSTM) language model is even more effective at recovering order, with our basic model outperforming a state-of-the-art syntactic model by 11.5 BLEU points. Additional data and larger beams yield further gains, at the expense of training and search time.
Sentence-Level Grammatical Error Identification as Sequence-to-Sequence Correction
Apr 16, 2016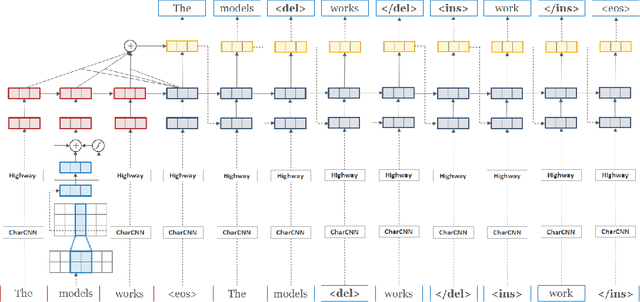
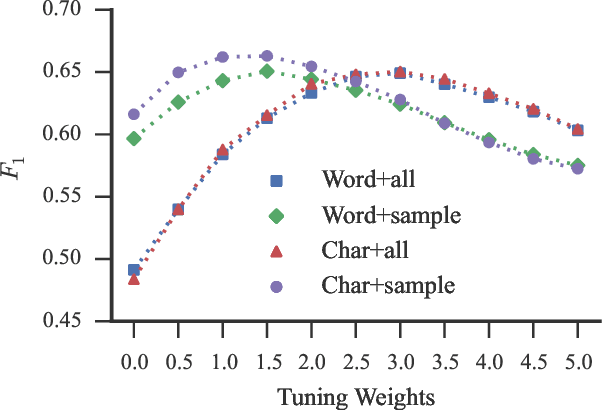
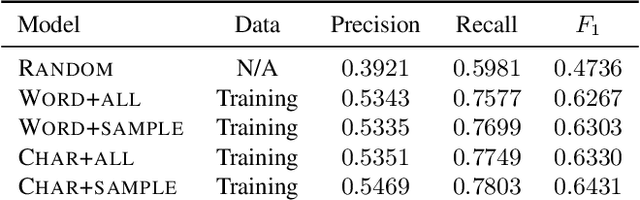
We demonstrate that an attention-based encoder-decoder model can be used for sentence-level grammatical error identification for the Automated Evaluation of Scientific Writing (AESW) Shared Task 2016. The attention-based encoder-decoder models can be used for the generation of corrections, in addition to error identification, which is of interest for certain end-user applications. We show that a character-based encoder-decoder model is particularly effective, outperforming other results on the AESW Shared Task on its own, and showing gains over a word-based counterpart. Our final model--a combination of three character-based encoder-decoder models, one word-based encoder-decoder model, and a sentence-level CNN--is the highest performing system on the AESW 2016 binary prediction Shared Task.