 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Kernels for Protein Property Prediction
Jun 09, 2026Despite its importance to applications in protein design, predicting protein properties like binding affinity and thermostability from sparse experimental data remains a significant challenge. Accordingly, we introduce a class of sequence kernels that exploit evolutionary substitution matrices as well as local linearity and demonstrate that the resulting Gaussian processes provide data-efficient models of protein property landscapes, frequently outperforming alternatives that rely on foundation model embeddings. Furthermore--by learning what are in effect structure-aware substitution matrices--we show that our kernels can readily incorporate structural information from foundation models. We demonstrate that these structure-conditioned kernels are well suited to multi-task learning across multiple protein property landscapes and can decisively outperform local supervised learning methods.
Towards Reliable Zero Shot Classification in Self-Supervised Models with Conformal Prediction
Oct 27, 2022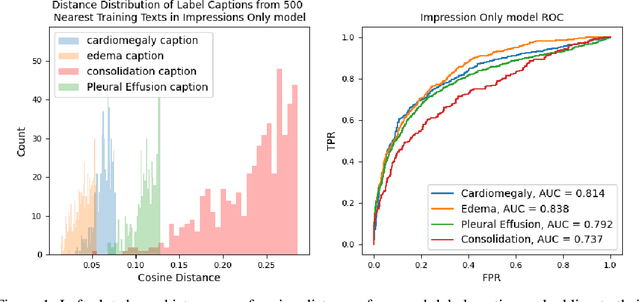
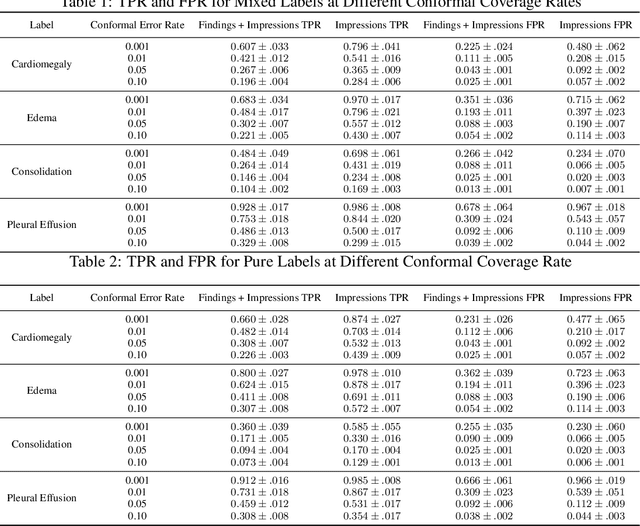
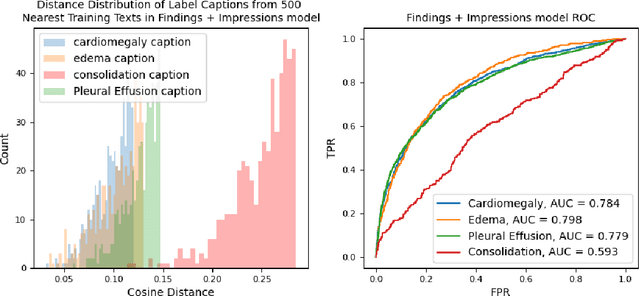

Self-supervised models trained with a contrastive loss such as CLIP have shown to be very powerful in zero-shot classification settings. However, to be used as a zero-shot classifier these models require the user to provide new captions over a fixed set of labels at test time. In many settings, it is hard or impossible to know if a new query caption is compatible with the source captions used to train the model. We address these limitations by framing the zero-shot classification task as an outlier detection problem and develop a conformal prediction procedure to assess when a given test caption may be reliably used. On a real-world medical example, we show that our proposed conformal procedure improves the reliability of CLIP-style models in the zero-shot classification setting, and we provide an empirical analysis of the factors that may affect its performance.
Adversarial Attacks Against Deep Learning Systems for ICD-9 Code Assignment
Sep 29, 2020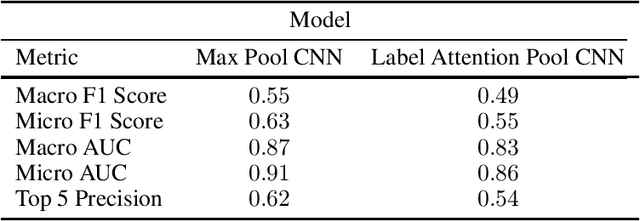
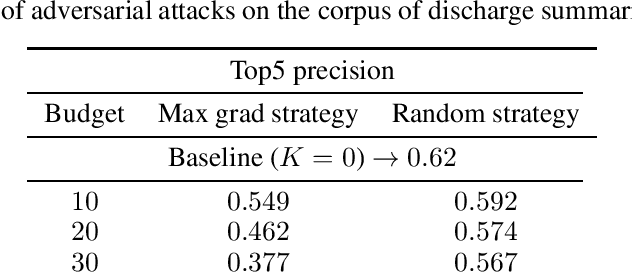

Manual annotation of ICD-9 codes is a time consuming and error-prone process. Deep learning based systems tackling the problem of automated ICD-9 coding have achieved competitive performance. Given the increased proliferation of electronic medical records, such automated systems are expected to eventually replace human coders. In this work, we investigate how a simple typo-based adversarial attack strategy can impact the performance of state-of-the-art models for the task of predicting the top 50 most frequent ICD-9 codes from discharge summaries. Preliminary results indicate that a malicious adversary, using gradient information, can craft specific perturbations, that appear as regular human typos, for less than 3% of words in the discharge summary to significantly affect the performance of the baseline model.