 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well do Feature Visualizations Support Causal Understanding of CNN Activations?
Paper and Code
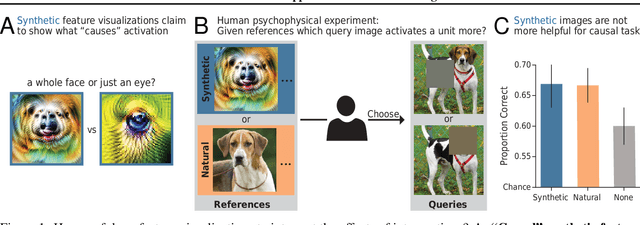

One widely used approach towards understanding the inner workings of deep convolutional neural networks is to visualize unit responses via activation maximization. Feature visualizations via activation maximization are thought to provide humans with precise information about the image features that cause a unit to be activated. If this is indeed true, these synthetic images should enable humans to predict the effect of an intervention, such as whether occluding a certain patch of the image (say, a dog's head) changes a unit's activation. Here, we test this hypothesis by asking humans to predict which of two square occlusions causes a larger change to a unit's activation. Both a large-scale crowdsourced experiment and measurements with experts show that on average, the extremely activating feature visualizations by Olah et al. (2017) indeed help humans on this task ($67 \pm 4\%$ accuracy; baseline performance without any visualizations is $60 \pm 3\%$). However, they do not provide any significant advantage over other visualizations (such as e.g. dataset samples), which yield similar performance ($66 \pm 3\%$ to $67 \pm 3\%$ accuracy). Taken together, we propose an objective psychophysical task to quantify the benefit of unit-level interpretability methods for humans, and find no evidence that feature visualizations provide humans with better "causal understanding" than simple alternative visualizations.