 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-based metrics: Sample-efficient estimates of predictive model subpopulation performance
Paper and Code
Apr 25, 2021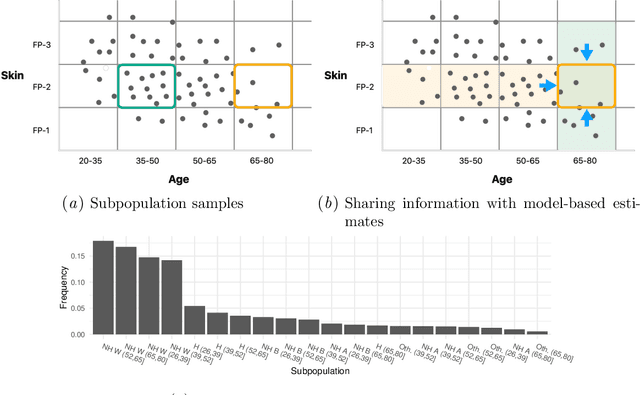
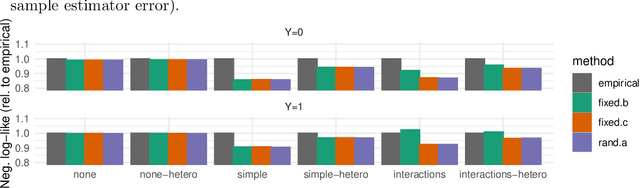
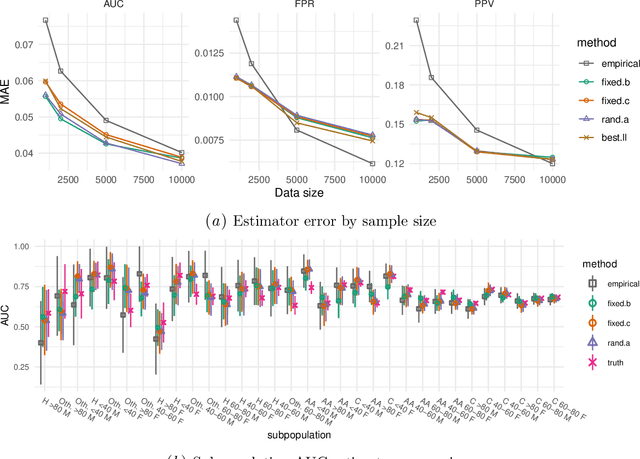
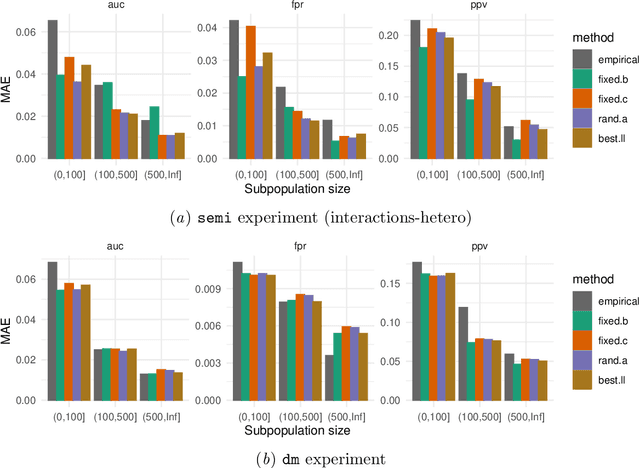
Machine learning models $-$ now commonly developed to screen, diagnose, or predict health conditions $-$ are evaluated with a variety of performance metrics. An important first step in assessing the practical utility of a model is to evaluate its average performance over an entire population of interest. In many settings, it is also critical that the model makes good predictions within predefined subpopulations. For instance, showing that a model is fair or equitable requires evaluating the model's performance in different demographic subgroups. However, subpopulation performance metrics are typically computed using only data from that subgroup, resulting in higher variance estimates for smaller groups. We devise a procedure to measure subpopulation performance that can be more sample-efficient than the typical subsample estimates. We propose using an evaluation model $-$ a model that describes the conditional distribution of the predictive model score $-$ to form model-based metric (MBM) estimates. Our procedure incorporates model checking and validation, and we propose a computationally efficient approximation of the traditional nonparametric bootstrap to form confidence intervals. We evaluate MBMs on two main tasks: a semi-synthetic setting where ground truth metrics are available and a real-world hospital readmission prediction task. We find that MBMs consistently produce more accurate and lower variance estimates of model performance for small subpopulations.