 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise & pattern: identity-anchored Tikhonov regularization for robust structural anomaly detection
Nov 10, 2025Anomaly detection plays a pivotal role in automated industrial inspection, aiming to identify subtle or rare defects in otherwise uniform visual patterns. As collecting representative examples of all possible anomalies is infeasible, we tackle structural anomaly detection using a self-supervised autoencoder that learns to repair corrupted inputs. To this end, we introduce a corruption model that injects artificial disruptions into training images to mimic structural defects. While reminiscent of denoising autoencoders, our approach differs in two key aspects. First, instead of unstructured i.i.d.\ noise, we apply structured, spatially coherent perturbations that make the task a hybrid of segmentation and inpainting. Second, and counterintuitively, we add and preserve Gaussian noise on top of the occlusions, which acts as a Tikhonov regularizer anchoring the Jacobian of the reconstruction function toward identity. This identity-anchored regularization stabilizes reconstruction and further improves both detection and segmentation accuracy. On the MVTec AD benchmark, our method achieves state-of-the-art results (I/P-AUROC: 99.9/99.4), supporting our theoretical framework and demonstrating its practical relevance for automatic inspection.
ConStellaration: A dataset of QI-like stellarator plasma boundaries and optimization benchmarks
Jun 24, 2025Stellarators are magnetic confinement devices under active development to deliver steady-state carbon-free fusion energy. Their design involves a high-dimensional, constrained optimization problem that requires expensive physics simulations and significant domain expertise. Recent advances in plasma physics and open-source tools have made stellarator optimization more accessible. However, broader community progress is currently bottlenecked by the lack of standardized optimization problems with strong baselines and datasets that enable data-driven approaches, particularly for quasi-isodynamic (QI) stellarator configurations, considered as a promising path to commercial fusion due to their inherent resilience to current-driven disruptions. Here, we release an open dataset of diverse QI-like stellarator plasma boundary shapes, paired with their ideal magnetohydrodynamic (MHD) equilibria and performance metrics. We generated this dataset by sampling a variety of QI fields and optimizing corresponding stellarator plasma boundaries. We introduce three optimization benchmarks of increasing complexity: (1) a single-objective geometric optimization problem, (2) a "simple-to-build" QI stellarator, and (3) a multi-objective ideal-MHD stable QI stellarator that investigates trade-offs between compactness and coil simplicity. For every benchmark, we provide reference code, evaluation scripts, and strong baselines based on classical optimization techniques. Finally, we show how learned models trained on our dataset can efficiently generate novel, feasible configurations without querying expensive physics oracles. By openly releasing the dataset along with benchmark problems and baselines, we aim to lower the entry barrier for optimization and machine learning researchers to engage in stellarator design and to accelerate cross-disciplinary progress toward bringing fusion energy to the grid.
Self-Supervised Training with Autoencoders for Visual Anomaly Detection
Jun 28, 2022


Deep convolutional autoencoders provide an effective tool for learning non-linear dimensionality reduction in an unsupervised way. Recently, they have been used for the task of anomaly detection in the visual domain. By optimising for the reconstruction error using anomaly-free examples, the common belief is that a trained network will have difficulties to reconstruct anomalous parts during the test phase. This is usually done by controlling the capacity of the network by either reducing the size of the bottleneck layer or enforcing sparsity constraints on its activations. However, neither of these techniques does explicitly penalise reconstruction of anomalous signals often resulting in a poor detection. We tackle this problem by adapting a self-supervised learning regime which allows to use discriminative information during training while regularising the model to focus on the data manifold by means of a modified reconstruction error resulting in an accurate detection. Unlike related approaches, the inference of the proposed method during training and prediction is very efficient processing the whole input image in one single step. Our experiments on the MVTec Anomaly Detection dataset demonstrate high recognition and localisation performance of the proposed method. On the texture-subset, in particular, our approach consistently outperforms a bunch of recent anomaly detection methods by a big margin.
Worst-Case Polynomial-Time Exact MAP Inference on Discrete Models with Global Dependencies
Dec 27, 2019



Considering the worst-case scenario, junction tree algorithm remains the most efficient and general solution for exact MAP inference on discrete graphical models. Unfortunately, its main tractability assumption requires the treewidth of a corresponding MRF to be bounded strongly limiting the range of admissible applications. In fact, many practical problems in the area of structured prediction require modelling of global dependencies by either directly introducing global factors or enforcing global constraints on the prediction variables. This, however, always results in a fully-connected graph making exact inference by means of this algorithm intractable. Nevertheless, depending on the structure of the global factors, we can further relax the conditions for an efficient inference. In this paper we reformulate the work in [1] and present a better way to establish the theory also extending the set of handleable problem instances for free - since it requires only a simple modification of the originally presented algorithm. To demonstrate that this extension is not of a purely theoretical interest we identify one further use case in the context of generalisation bounds for structured learning which cannot be handled by the previous formulation. Finally, we accordingly adjust the theoretical guarantees that the modified algorithm always finds an optimal solution in polynomial time.
Towards best practice in explaining neural network decisions with LRP
Oct 22, 2019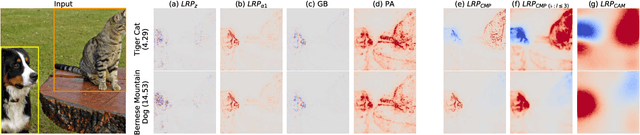
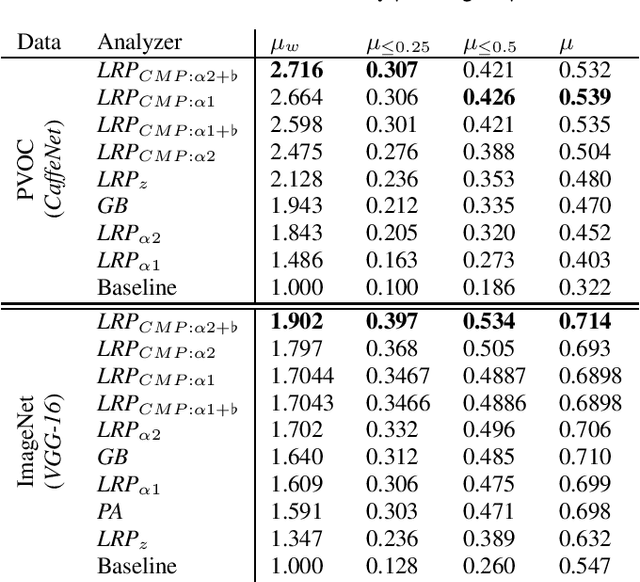
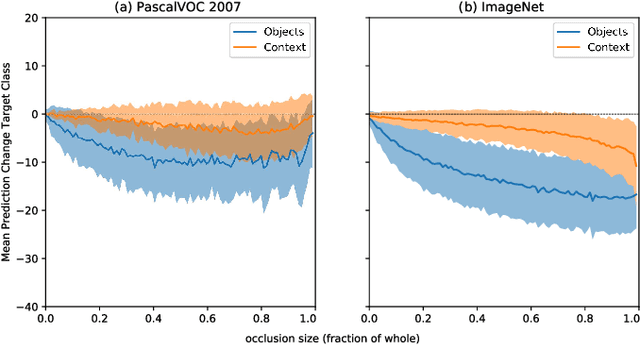
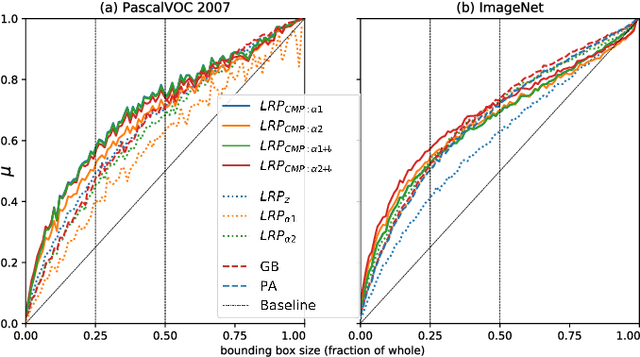
Within the last decade, neural network based predictors have demonstrated impressive - and at times super-human - capabilities. This performance is often paid for with an intransparent prediction process and thus has sparked numerous contributions in the novel field of explainable artificial intelligence (XAI). In this paper, we focus on a popular and widely used method of XAI, the Layer-wise Relevance Propagation (LRP). Since its initial proposition LRP has evolved as a method, and a best practice for applying the method has tacitly emerged, based on humanly observed evidence. We investigate - and for the first time quantify - the effect of this current best practice on feedforward neural networks in a visual object detection setting. The results verify that the current, layer-dependent approach to LRP applied in recent literature better represents the model's reasoning, and at the same time increases the object localization and class discriminativity of LRP.
Optimizing for Measure of Performance in Max-Margin Parsing
Sep 08, 2017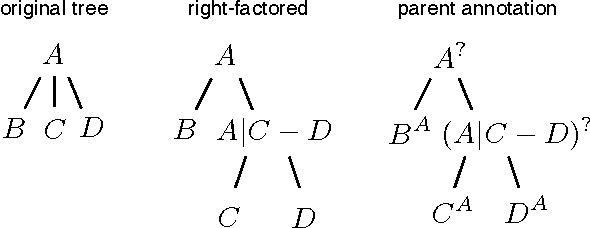
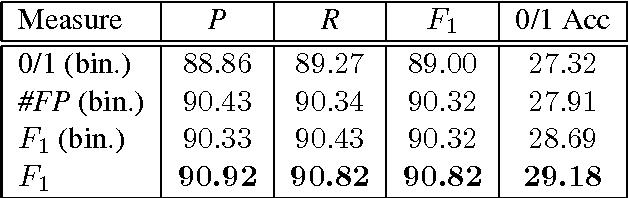
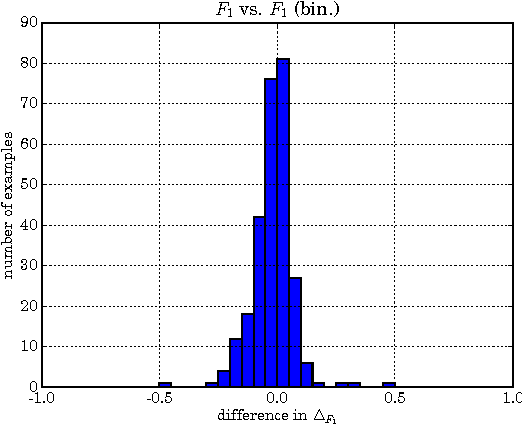
Many statistical learning problems in the area of natural language processing including sequence tagging, sequence segmentation and syntactic parsing has been successfully approached by means of structured prediction methods. An appealing property of the corresponding discriminative learning algorithms is their ability to integrate the loss function of interest directly into the optimization process, which potentially can increase the resulting performance accuracy. Here, we demonstrate on the example of constituency parsing how to optimize for F1-score in the max-margin framework of structural SVM. In particular, the optimization is with respect to the original (not binarized) trees.