 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Training with Autoencoders for Visual Anomaly Detection
Paper and Code
Jun 28, 2022
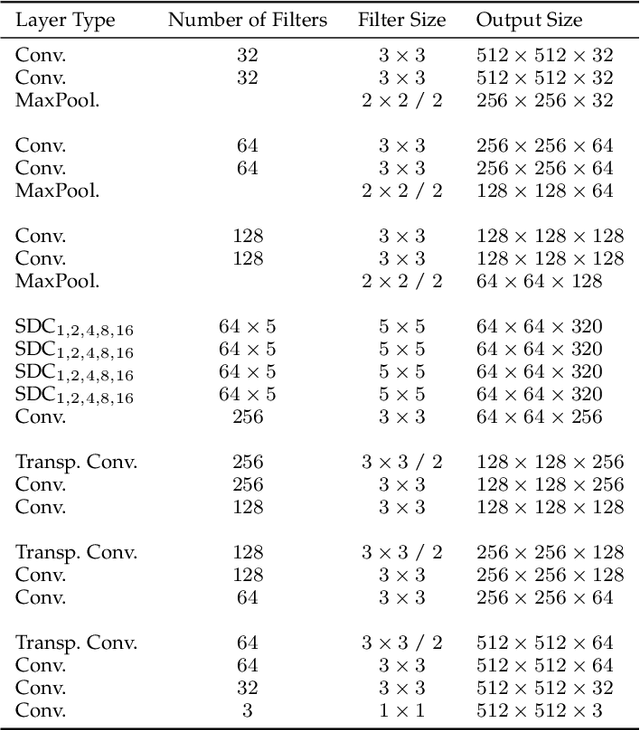


Deep convolutional autoencoders provide an effective tool for learning non-linear dimensionality reduction in an unsupervised way. Recently, they have been used for the task of anomaly detection in the visual domain. By optimising for the reconstruction error using anomaly-free examples, the common belief is that a trained network will have difficulties to reconstruct anomalous parts during the test phase. This is usually done by controlling the capacity of the network by either reducing the size of the bottleneck layer or enforcing sparsity constraints on its activations. However, neither of these techniques does explicitly penalise reconstruction of anomalous signals often resulting in a poor detection. We tackle this problem by adapting a self-supervised learning regime which allows to use discriminative information during training while regularising the model to focus on the data manifold by means of a modified reconstruction error resulting in an accurate detection. Unlike related approaches, the inference of the proposed method during training and prediction is very efficient processing the whole input image in one single step. Our experiments on the MVTec Anomaly Detection dataset demonstrate high recognition and localisation performance of the proposed method. On the texture-subset, in particular, our approach consistently outperforms a bunch of recent anomaly detection methods by a big margin.