Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing for Measure of Performance in Max-Margin Parsing
Paper and Code
Sep 08, 2017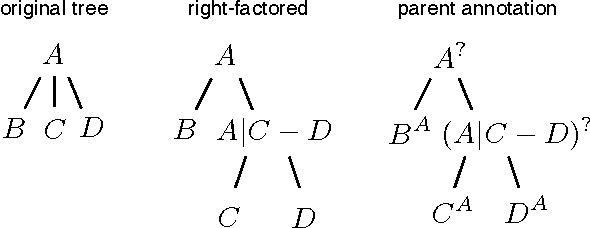
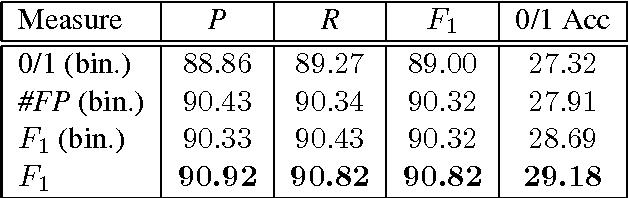
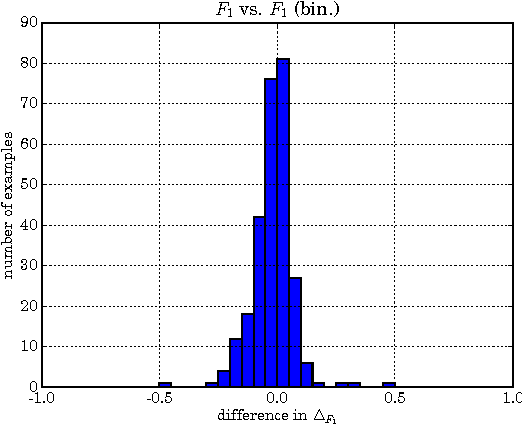
Many statistical learning problems in the area of natural language processing including sequence tagging, sequence segmentation and syntactic parsing has been successfully approached by means of structured prediction methods. An appealing property of the corresponding discriminative learning algorithms is their ability to integrate the loss function of interest directly into the optimization process, which potentially can increase the resulting performance accuracy. Here, we demonstrate on the example of constituency parsing how to optimize for F1-score in the max-margin framework of structural SVM. In particular, the optimization is with respect to the original (not binarized) trees.
View paper on