 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Learning Based Framework for Light Field Reconstruction from Coded Projections
Paper and Code
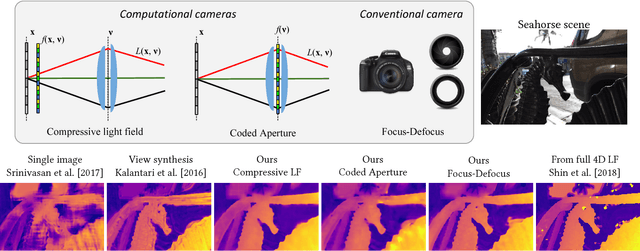
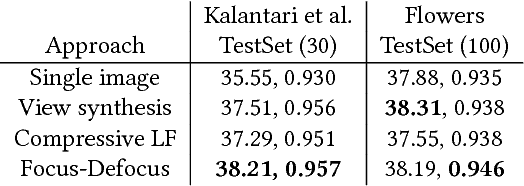
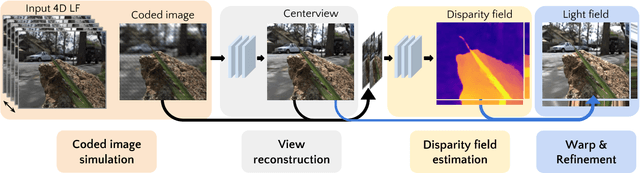
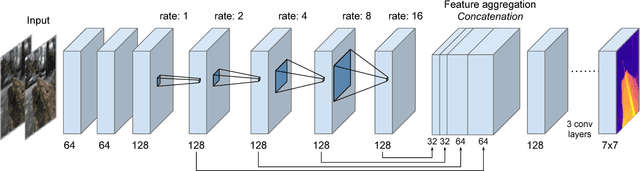
Light field presents a rich way to represent the 3D world by capturing the spatio-angular dimensions of the visual signal. However, the popular way of capturing light field (LF) via a plenoptic camera presents spatio-angular resolution trade-off. Computational imaging techniques such as compressive light field and programmable coded aperture reconstruct full sensor resolution LF from coded projections obtained by multiplexing the incoming spatio-angular light field. Here, we present a unified learning framework that can reconstruct LF from a variety of multiplexing schemes with minimal number of coded images as input. We consider three light field capture schemes: heterodyne capture scheme with code placed near the sensor, coded aperture scheme with code at the camera aperture and finally the dual exposure scheme of capturing a focus-defocus pair where there is no explicit coding. Our algorithm consists of three stages 1) we recover the all-in-focus image from the coded image 2) we estimate the disparity maps for all the LF views from the coded image and the all-in-focus image, 3) we then render the LF by warping the all-in-focus image using disparity maps and refine it. For these three stages we propose three deep neural networks - ViewNet, DispairtyNet and RefineNet. Our reconstructions show that our learning algorithm achieves state-of-the-art results for all the three multiplexing schemes. Especially, our LF reconstructions from focus-defocus pair is comparable to other learning-based view synthesis approaches from multiple images. Thus, our work paves the way for capturing high-resolution LF (~ a megapixel) using conventional cameras such as DSLRs. Please check our supplementary materials $\href{https://docs.google.com/presentation/d/1Vr-F8ZskrSd63tvnLfJ2xmEXY6OBc1Rll3XeOAtc11I/}{online}$ to better appreciate the reconstructed light fields.