 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeafloorAI: A Large-scale Vision-Language Dataset for Seafloor Geological Survey
Oct 31, 2024



A major obstacle to the advancements of machine learning models in marine science, particularly in sonar imagery analysis, is the scarcity of AI-ready datasets. While there have been efforts to make AI-ready sonar image dataset publicly available, they suffer from limitations in terms of environment setting and scale. To bridge this gap, we introduce SeafloorAI, the first extensive AI-ready datasets for seafloor mapping across 5 geological layers that is curated in collaboration with marine scientists. We further extend the dataset to SeafloorGenAI by incorporating the language component in order to facilitate the development of both vision- and language-capable machine learning models for sonar imagery. The dataset consists of 62 geo-distributed data surveys spanning 17,300 square kilometers, with 696K sonar images, 827K annotated segmentation masks, 696K detailed language descriptions and approximately 7M question-answer pairs. By making our data processing source code publicly available, we aim to engage the marine science community to enrich the data pool and inspire the machine learning community to develop more robust models. This collaborative approach will enhance the capabilities and applications of our datasets within both fields.
Adaptive Cascading Network for Continual Test-Time Adaptation
Jul 17, 2024We study the problem of continual test-time adaption where the goal is to adapt a source pre-trained model to a sequence of unlabelled target domains at test time. Existing methods on test-time training suffer from several limitations: (1) Mismatch between the feature extractor and classifier; (2) Interference between the main and self-supervised tasks; (3) Lack of the ability to quickly adapt to the current distribution. In light of these challenges, we propose a cascading paradigm that simultaneously updates the feature extractor and classifier at test time, mitigating the mismatch between them and enabling long-term model adaptation. The pre-training of our model is structured within a meta-learning framework, thereby minimizing the interference between the main and self-supervised tasks and encouraging fast adaptation in the presence of limited unlabelled data. Additionally, we introduce innovative evaluation metrics, average accuracy and forward transfer, to effectively measure the model's adaptation capabilities in dynamic, real-world scenarios. Extensive experiments and ablation studies demonstrate the superiority of our approach in a range of tasks including image classification, text classification, and speech recognition.
Topology-aware Robust Optimization for Out-of-distribution Generalization
Jul 26, 2023Out-of-distribution (OOD) generalization is a challenging machine learning problem yet highly desirable in many high-stake applications. Existing methods suffer from overly pessimistic modeling with low generalization confidence. As generalizing to arbitrary test distributions is impossible, we hypothesize that further structure on the topology of distributions is crucial in developing strong OOD resilience. To this end, we propose topology-aware robust optimization (TRO) that seamlessly integrates distributional topology in a principled optimization framework. More specifically, TRO solves two optimization objectives: (1) Topology Learning which explores data manifold to uncover the distributional topology; (2) Learning on Topology which exploits the topology to constrain robust optimization for tightly-bounded generalization risks. We theoretically demonstrate the effectiveness of our approach and empirically show that it significantly outperforms the state of the arts in a wide range of tasks including classification, regression, and semantic segmentation. Moreover, we empirically find the data-driven distributional topology is consistent with domain knowledge, enhancing the explainability of our approach.
Are Data-driven Explanations Robust against Out-of-distribution Data?
Mar 29, 2023As black-box models increasingly power high-stakes applications, a variety of data-driven explanation methods have been introduced. Meanwhile, machine learning models are constantly challenged by distributional shifts. A question naturally arises: Are data-driven explanations robust against out-of-distribution data? Our empirical results show that even though predict correctly, the model might still yield unreliable explanations under distributional shifts. How to develop robust explanations against out-of-distribution data? To address this problem, we propose an end-to-end model-agnostic learning framework Distributionally Robust Explanations (DRE). The key idea is, inspired by self-supervised learning, to fully utilizes the inter-distribution information to provide supervisory signals for the learning of explanations without human annotation. Can robust explanations benefit the model's generalization capability? We conduct extensive experiments on a wide range of tasks and data types, including classification and regression on image and scientific tabular data. Our results demonstrate that the proposed method significantly improves the model's performance in terms of explanation and prediction robustness against distributional shifts.
Out-of-domain Generalization from a Single Source: A Uncertainty Quantification Approach
Aug 05, 2021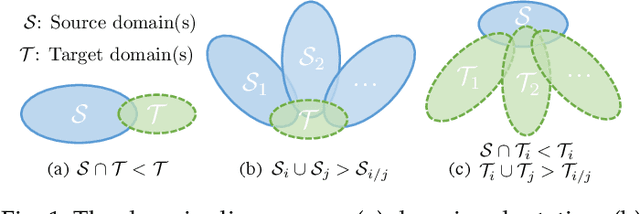


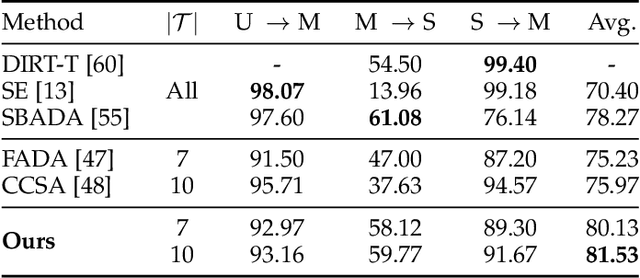
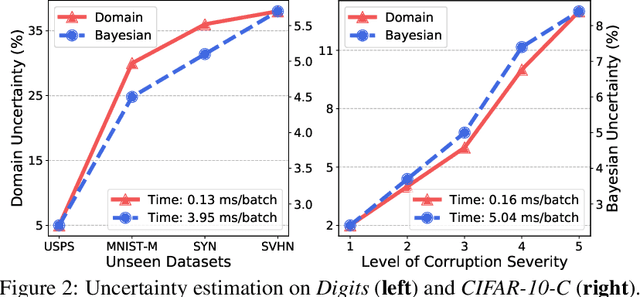
We study a worst-case scenario in generalization: Out-of-domain generalization from a single source. The goal is to learn a robust model from a single source and expect it to generalize over many unknown distributions. This challenging problem has been seldom investigated while existing solutions suffer from various limitations such as the ignorance of uncertainty assessment and label augmentation. In this paper, we propose uncertainty-guided domain generalization to tackle the aforementioned limitations. The key idea is to augment the source capacity in both feature and label spaces, while the augmentation is guided by uncertainty assessment. To the best of our knowledge, this is the first work to (1) quantify the generalization uncertainty from a single source and (2) leverage it to guide both feature and label augmentation for robust generalization. The model training and deployment are effectively organized in a Bayesian meta-learning framework. We conduct extensive comparisons and ablation study to validate our approach. The results prove our superior performance in a wide scope of tasks including image classification, semantic segmentation, text classification, and speech recognition.
Uncertainty-guided Model Generalization to Unseen Domains
Mar 12, 2021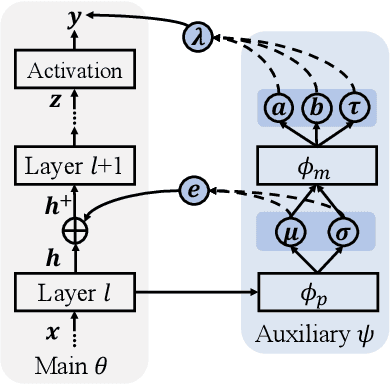
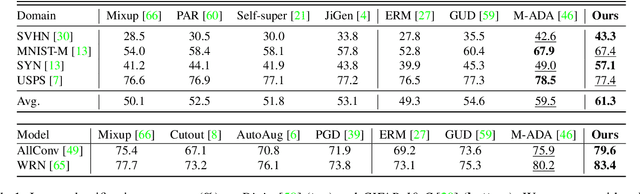

We study a worst-case scenario in generalization: Out-of-domain generalization from a single source. The goal is to learn a robust model from a single source and expect it to generalize over many unknown distributions. This challenging problem has been seldom investigated while existing solutions suffer from various limitations. In this paper, we propose a new solution. The key idea is to augment the source capacity in both input and label spaces, while the augmentation is guided by uncertainty assessment. To the best of our knowledge, this is the first work to (1) access the generalization uncertainty from a single source and (2) leverage it to guide both input and label augmentation for robust generalization. The model training and deployment are effectively organized in a Bayesian meta-learning framework. We conduct extensive comparisons and ablation study to validate our approach. The results prove our superior performance in a wide scope of tasks including image classification, semantic segmentation, text classification, and speech recognition.
Learning to Learn Single Domain Generalization
Mar 30, 2020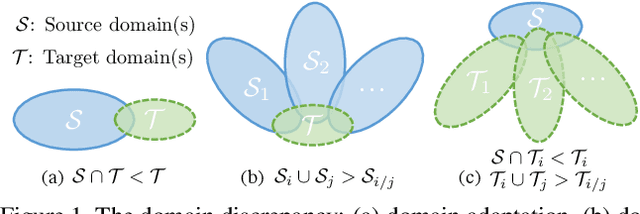



We are concerned with a worst-case scenario in model generalization, in the sense that a model aims to perform well on many unseen domains while there is only one single domain available for training. We propose a new method named adversarial domain augmentation to solve this Out-of-Distribution (OOD) generalization problem. The key idea is to leverage adversarial training to create "fictitious" yet "challenging" populations, from which a model can learn to generalize with theoretical guarantees. To facilitate fast and desirable domain augmentation, we cast the model training in a meta-learning scheme and use a Wasserstein Auto-Encoder (WAE) to relax the widely used worst-case constraint. Detailed theoretical analysis is provided to testify our formulation, while extensive experiments on multiple benchmark datasets indicate its superior performance in tackling single domain generalization.
Geometry-Contrastive GAN for Facial Expression Transfer
Oct 22, 2018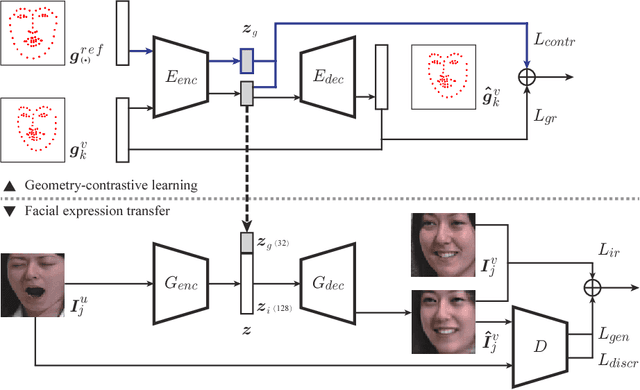
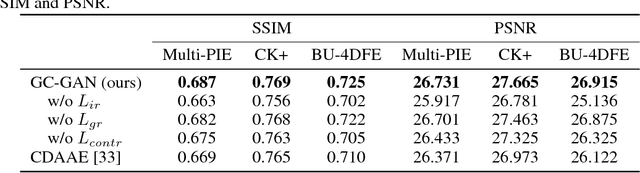


In this paper, we propose a Geometry-Contrastive Generative Adversarial Network (GC-GAN) for transferring continuous emotions across different subjects. Given an input face with certain emotion and a target facial expression from another subject, GC-GAN can generate an identity-preserving face with the target expression. Geometry information is introduced into cGANs as continuous conditions to guide the generation of facial expressions. In order to handle the misalignment across different subjects or emotions, contrastive learning is used to transform geometry manifold into an embedded semantic manifold of facial expressions. Therefore, the embedded geometry is injected into the latent space of GANs and control the emotion generation effectively. Experimental results demonstrate that our proposed method can be applied in facial expression transfer even there exist big differences in facial shapes and expressions between different subjects.