 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSATalker: Realistic Socially-Aware Talking Head Generation for Multi-Turn Conversation
Jan 15, 2026Talking head generation is increasingly important in virtual reality (VR), especially for social scenarios involving multi-turn conversation. Existing approaches face notable limitations: mesh-based 3D methods can model dual-person dialogue but lack realistic textures, while large-model-based 2D methods produce natural appearances but incur prohibitive computational costs. Recently, 3D Gaussian Splatting (3DGS) based methods achieve efficient and realistic rendering but remain speaker-only and ignore social relationships. We introduce RSATalker, the first framework that leverages 3DGS for realistic and socially-aware talking head generation with support for multi-turn conversation. Our method first drives mesh-based 3D facial motion from speech, then binds 3D Gaussians to mesh facets to render high-fidelity 2D avatar videos. To capture interpersonal dynamics, we propose a socially-aware module that encodes social relationships, including blood and non-blood as well as equal and unequal, into high-level embeddings through a learnable query mechanism. We design a three-stage training paradigm and construct the RSATalker dataset with speech-mesh-image triplets annotated with social relationships. Extensive experiments demonstrate that RSATalker achieves state-of-the-art performance in both realism and social awareness. The code and dataset will be released.
DiffusionTalker: Personalization and Acceleration for Speech-Driven 3D Face Diffuser
Dec 02, 2023
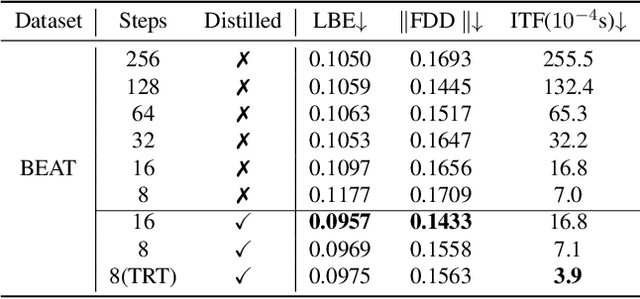
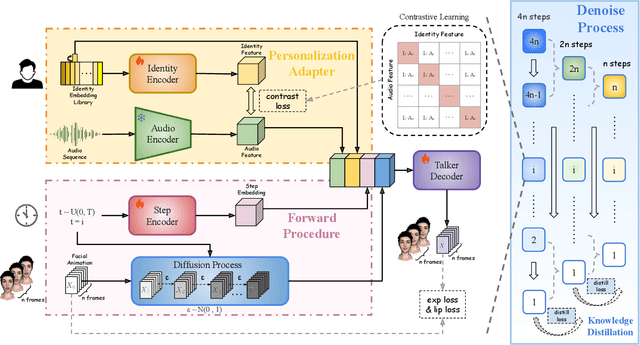
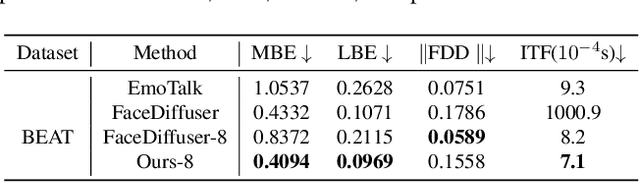
Speech-driven 3D facial animation has been an attractive task in both academia and industry. Traditional methods mostly focus on learning a deterministic mapping from speech to animation. Recent approaches start to consider the non-deterministic fact of speech-driven 3D face animation and employ the diffusion model for the task. However, personalizing facial animation and accelerating animation generation are still two major limitations of existing diffusion-based methods. To address the above limitations, we propose DiffusionTalker, a diffusion-based method that utilizes contrastive learning to personalize 3D facial animation and knowledge distillation to accelerate 3D animation generation. Specifically, to enable personalization, we introduce a learnable talking identity to aggregate knowledge in audio sequences. The proposed identity embeddings extract customized facial cues across different people in a contrastive learning manner. During inference, users can obtain personalized facial animation based on input audio, reflecting a specific talking style. With a trained diffusion model with hundreds of steps, we distill it into a lightweight model with 8 steps for acceleration. Extensive experiments are conducted to demonstrate that our method outperforms state-of-the-art methods. The code will be released.
Geometry-Contrastive GAN for Facial Expression Transfer
Oct 22, 2018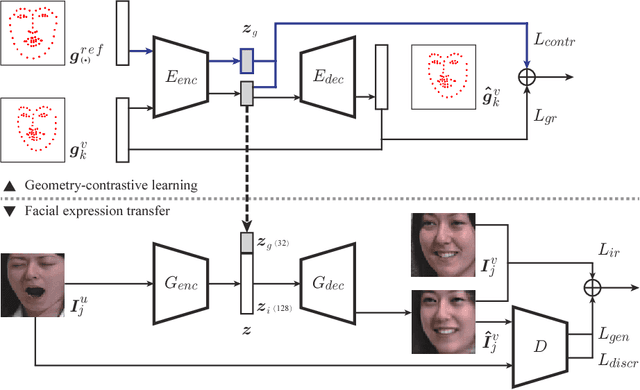
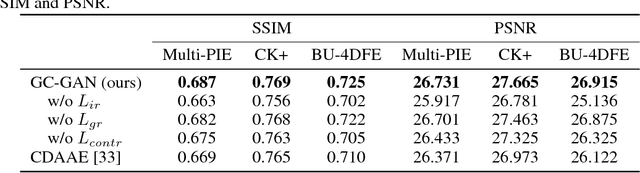


In this paper, we propose a Geometry-Contrastive Generative Adversarial Network (GC-GAN) for transferring continuous emotions across different subjects. Given an input face with certain emotion and a target facial expression from another subject, GC-GAN can generate an identity-preserving face with the target expression. Geometry information is introduced into cGANs as continuous conditions to guide the generation of facial expressions. In order to handle the misalignment across different subjects or emotions, contrastive learning is used to transform geometry manifold into an embedded semantic manifold of facial expressions. Therefore, the embedded geometry is injected into the latent space of GANs and control the emotion generation effectively. Experimental results demonstrate that our proposed method can be applied in facial expression transfer even there exist big differences in facial shapes and expressions between different subjects.