 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Real-time Cross-modal Cybersickness Prediction in Virtual Reality
Jan 02, 2025Cybersickness remains a significant barrier to the widespread adoption of immersive virtual reality (VR) experiences, as it can greatly disrupt user engagement and comfort. Research has shown that cybersickness can significantly be reflected in head and eye tracking data, along with other physiological data (e.g., TMP, EDA, and BMP). Despite the application of deep learning techniques such as CNNs and LSTMs, these models often struggle to capture the complex interactions between multiple data modalities and lack the capacity for real-time inference, limiting their practical application. Addressing this gap, we propose a lightweight model that leverages a transformer-based encoder with sparse self-attention to process bio-signal features and a PP-TSN network for video feature extraction. These features are then integrated via a cross-modal fusion module, creating a video-aware bio-signal representation that supports cybersickness prediction based on both visual and bio-signal inputs. Our model, trained with a lightweight framework, was validated on a public dataset containing eye and head tracking data, physiological data, and VR video, and demonstrated state-of-the-art performance in cybersickness prediction, achieving a high accuracy of 93.13\% using only VR video inputs. These findings suggest that our approach not only enables effective, real-time cybersickness prediction but also addresses the longstanding issue of modality interaction in VR environments. This advancement provides a foundation for future research on multimodal data integration in VR, potentially leading to more personalized, comfortable and widely accessible VR experiences.
DiffusionTalker: Personalization and Acceleration for Speech-Driven 3D Face Diffuser
Dec 02, 2023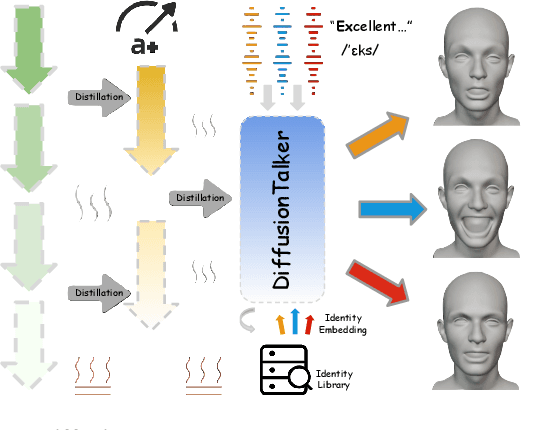
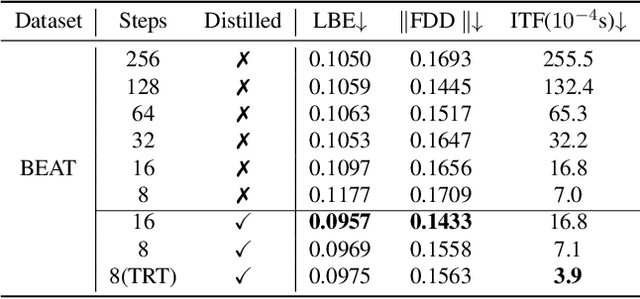
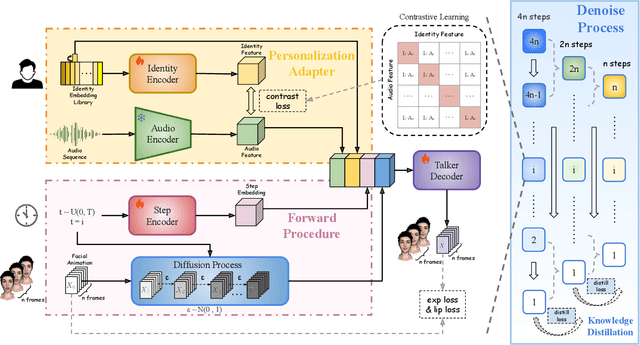
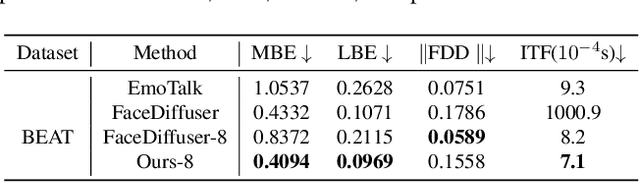
Speech-driven 3D facial animation has been an attractive task in both academia and industry. Traditional methods mostly focus on learning a deterministic mapping from speech to animation. Recent approaches start to consider the non-deterministic fact of speech-driven 3D face animation and employ the diffusion model for the task. However, personalizing facial animation and accelerating animation generation are still two major limitations of existing diffusion-based methods. To address the above limitations, we propose DiffusionTalker, a diffusion-based method that utilizes contrastive learning to personalize 3D facial animation and knowledge distillation to accelerate 3D animation generation. Specifically, to enable personalization, we introduce a learnable talking identity to aggregate knowledge in audio sequences. The proposed identity embeddings extract customized facial cues across different people in a contrastive learning manner. During inference, users can obtain personalized facial animation based on input audio, reflecting a specific talking style. With a trained diffusion model with hundreds of steps, we distill it into a lightweight model with 8 steps for acceleration. Extensive experiments are conducted to demonstrate that our method outperforms state-of-the-art methods. The code will be released.