 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptable GAN Encoders for Image Reconstruction via Multi-type Latent Vectors with Two-scale Attentions
Aug 23, 2021

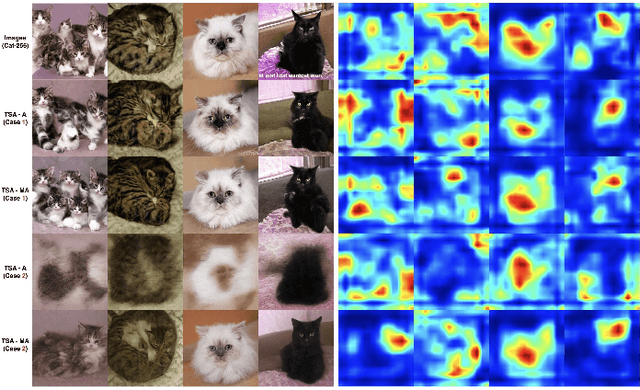

Although current deep generative adversarial networks (GANs) could synthesize high-quality (HQ) images, discovering novel GAN encoders for image reconstruction is still favorable. When embedding images to latent space, existing GAN encoders work well for aligned images (such as the human face), but they do not adapt to more generalized GANs. To our knowledge, current state-of-the-art GAN encoders do not have a proper encoder to reconstruct high-fidelity images from most misaligned HQ synthesized images on different GANs. Their performances are limited, especially on non-aligned and real images. We propose a novel method (named MTV-TSA) to handle such problems. Creating multi-type latent vectors (MTV) from latent space and two-scale attentions (TSA) from images allows designing a set of encoders that can be adaptable to a variety of pre-trained GANs. We generalize two sets of loss functions to optimize the encoders. The designed encoders could make GANs reconstruct higher fidelity images from most synthesized HQ images. In addition, the proposed method can reconstruct real images well and process them based on learned attribute directions. The designed encoders have unified convolutional blocks and could match well in current GAN architectures (such as PGGAN, StyleGANs, and BigGAN) by fine-tuning the corresponding normalization layers and the last block. Such well-designed encoders can also be trained to converge more quickly.
Brain-Inspired Inference on Missing Video Sequence
Dec 15, 2019
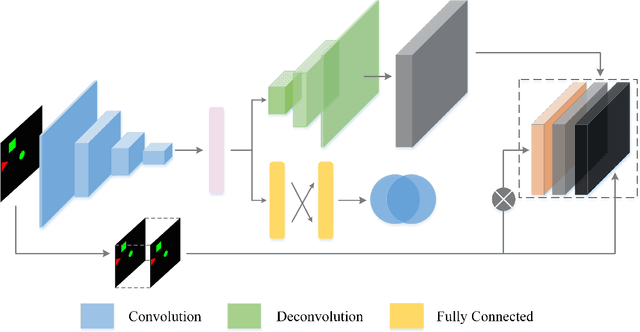
In this paper, we propose a novel end-to-end architecture that could generate a variety of plausible video sequences correlating two given discontinuous frames. Our work is inspired by the human ability of inference. Specifically, given two static images, human are capable of inferring what might happen in between as well as present diverse versions of their inference. We firstly train our model to learn the transformation to understand the movement trends within given frames. For the sake of imitating the inference of human, we introduce a latent variable sampled from Gaussian distribution. By means of integrating different latent variables with learned transformation features, the model could learn more various possible motion modes. Then applying these motion modes on the original frame, we could acquire various corresponding intermediate video sequence. Moreover, the framework is trained in adversarial fashion with unsupervised learning. Evaluating on the moving Mnist dataset and the 2D Shapes dataset, we show that our model is capable of imitating the human inference to some extent.
Adaptively Aligned Image Captioning via Adaptive Attention Time
Nov 01, 2019



Recent neural models for image captioning usually employ an encoder-decoder framework with an attention mechanism. However, the attention mechanism in such a framework aligns one single (attended) image feature vector to one caption word, assuming one-to-one mapping from source image regions and target caption words, which is never possible. In this paper, we propose a novel attention model, namely Adaptive Attention Time (AAT), to align the source and the target adaptively for image captioning. AAT allows the framework to learn how many attention steps to take to output a caption word at each decoding step. With AAT, an image region can be mapped to an arbitrary number of caption words while a caption word can also attend to an arbitrary number of image regions. AAT is deterministic and differentiable, and doesn't introduce any noise to the parameter gradients. In this paper, we empirically show that AAT improves over state-of-the-art methods on the task of image captioning. Code is available at https://github.com/husthuaan/AAT.
Attention on Attention for Image Captioning
Aug 21, 2019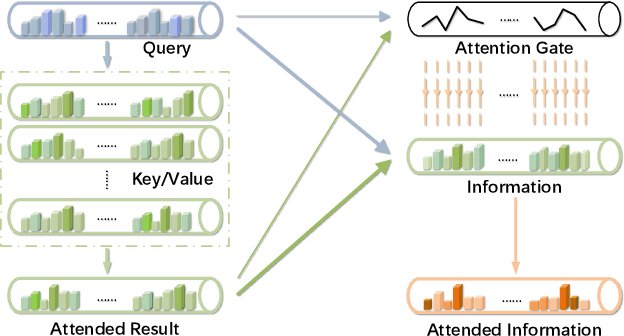
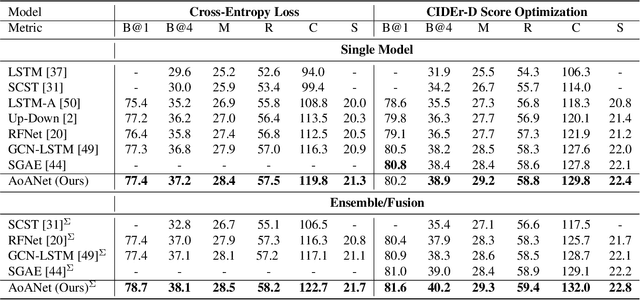
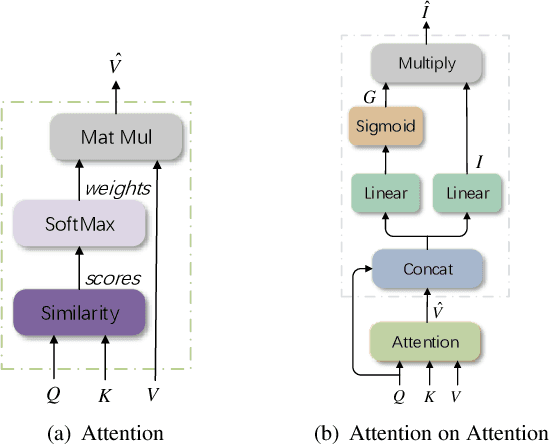
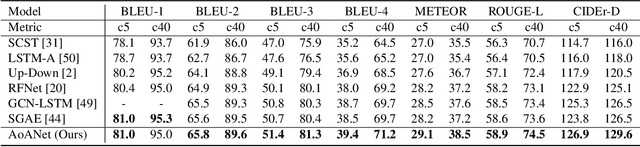
Attention mechanisms are widely used in current encoder/decoder frameworks of image captioning, where a weighted average on encoded vectors is generated at each time step to guide the caption decoding process. However, the decoder has little idea of whether or how well the attended vector and the given attention query are related, which could make the decoder give misled results. In this paper, we propose an Attention on Attention (AoA) module, which extends the conventional attention mechanisms to determine the relevance between attention results and queries. AoA first generates an information vector and an attention gate using the attention result and the current context, then adds another attention by applying element-wise multiplication to them and finally obtains the attended information, the expected useful knowledge. We apply AoA to both the encoder and the decoder of our image captioning model, which we name as AoA Network (AoANet). Experiments show that AoANet outperforms all previously published methods and achieves a new state-of-the-art performance of 129.8 CIDEr-D score on MS COCO Karpathy offline test split and 129.6 CIDEr-D (C40) score on the official online testing server. Code is available at https://github.com/husthuaan/AoANet.
ParNet: Position-aware Aggregated Relation Network for Image-Text matching
Jun 17, 2019



Exploring fine-grained relationship between entities(e.g. objects in image or words in sentence) has great contribution to understand multimedia content precisely. Previous attention mechanism employed in image-text matching either takes multiple self attention steps to gather correspondences or uses image objects (or words) as context to infer image-text similarity. However, they only take advantage of semantic information without considering that objects' relative position also contributes to image understanding. To this end, we introduce a novel position-aware relation module to model both the semantic and spatial relationship simultaneously for image-text matching in this paper. Given an image, our method utilizes the location of different objects to capture spatial relationship innovatively. With the combination of semantic and spatial relationship, it's easier to understand the content of different modalities (images and sentences) and capture fine-grained latent correspondences of image-text pairs. Besides, we employ a two-step aggregated relation module to capture interpretable alignment of image-text pairs. The first step, we call it intra-modal relation mechanism, in which we computes responses between different objects in an image or different words in a sentence separately; The second step, we call it inter-modal relation mechanism, in which the query plays a role of textual context to refine the relationship among object proposals in an image. In this way, our position-aware aggregated relation network (ParNet) not only knows which entities are relevant by attending on different objects (words) adaptively, but also adjust the inter-modal correspondence according to the latent alignments according to query's content. Our approach achieves the state-of-the-art results on MS-COCO dataset.
Local Patch Encoding-Based Method for Single Image Super-Resolution
Jul 04, 2018



Recent learning-based super-resolution (SR) methods often focus on dictionary learning or network training. In this paper, we discuss in detail a new SR method based on local patch encoding (LPE) instead of traditional dictionary learning. The proposed method consists of a learning stage and a reconstructing stage. In the learning stage, image patches are classified into different classes by means of the proposed LPE, and then a projection matrix is computed for each class by utilizing a simple constraint. In the reconstructing stage, an input LR patch can be simply reconstructed by computing its LPE code and then multiplying the corresponding projection matrix. Furthermore, we discuss the relationship between the proposed method and the anchored neighborhood regression methods; we also analyze the extendibility of the proposed method. The experimental results on several image sets demonstrate the effectiveness of the LPE-based methods.
* 20 pages, 8 figures
Video Imagination from a Single Image with Transformation Generation
Jun 15, 2017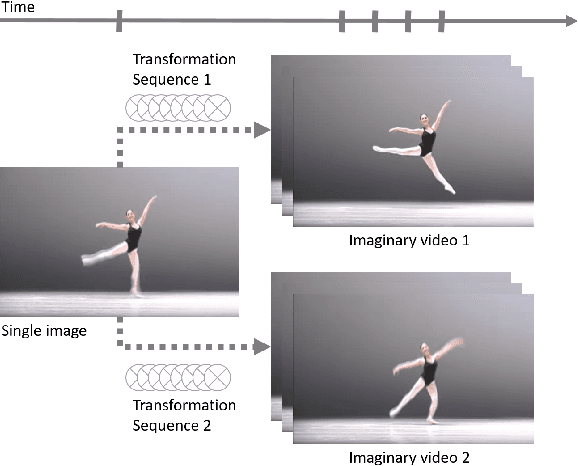

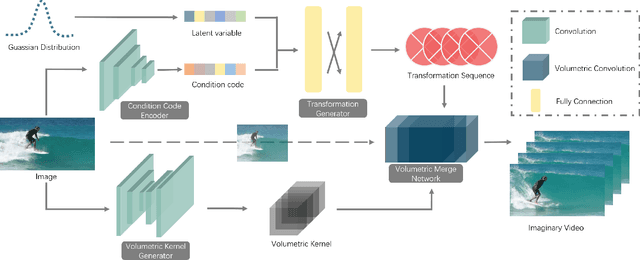
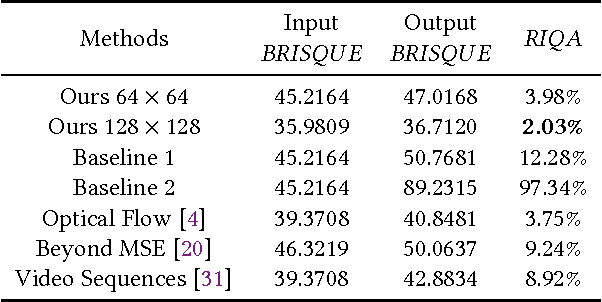
In this work, we focus on a challenging task: synthesizing multiple imaginary videos given a single image. Major problems come from high dimensionality of pixel space and the ambiguity of potential motions. To overcome those problems, we propose a new framework that produce imaginary videos by transformation generation. The generated transformations are applied to the original image in a novel volumetric merge network to reconstruct frames in imaginary video. Through sampling different latent variables, our method can output different imaginary video samples. The framework is trained in an adversarial way with unsupervised learning. For evaluation, we propose a new assessment metric $RIQA$. In experiments, we test on 3 datasets varying from synthetic data to natural scene. Our framework achieves promising performance in image quality assessment. The visual inspection indicates that it can successfully generate diverse five-frame videos in acceptable perceptual quality.
Beyond Monte Carlo Tree Search: Playing Go with Deep Alternative Neural Network and Long-Term Evaluation
Jun 13, 2017
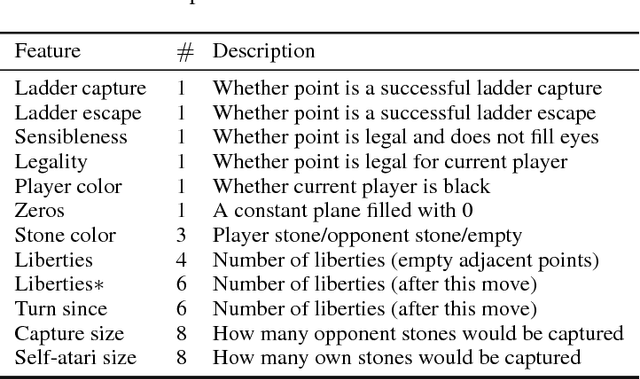


Monte Carlo tree search (MCTS) is extremely popular in computer Go which determines each action by enormous simulations in a broad and deep search tree. However, human experts select most actions by pattern analysis and careful evaluation rather than brute search of millions of future nteractions. In this paper, we propose a computer Go system that follows experts way of thinking and playing. Our system consists of two parts. The first part is a novel deep alternative neural network (DANN) used to generate candidates of next move. Compared with existing deep convolutional neural network (DCNN), DANN inserts recurrent layer after each convolutional layer and stacks them in an alternative manner. We show such setting can preserve more contexts of local features and its evolutions which are beneficial for move prediction. The second part is a long-term evaluation (LTE) module used to provide a reliable evaluation of candidates rather than a single probability from move predictor. This is consistent with human experts nature of playing since they can foresee tens of steps to give an accurate estimation of candidates. In our system, for each candidate, LTE calculates a cumulative reward after several future interactions when local variations are settled. Combining criteria from the two parts, our system determines the optimal choice of next move. For more comprehensive experiments, we introduce a new professional Go dataset (PGD), consisting of 253233 professional records. Experiments on GoGoD and PGD datasets show the DANN can substantially improve performance of move prediction over pure DCNN. When combining LTE, our system outperforms most relevant approaches and open engines based on MCTS.
Long-Term Video Interpolation with Bidirectional Predictive Network
Jun 13, 2017
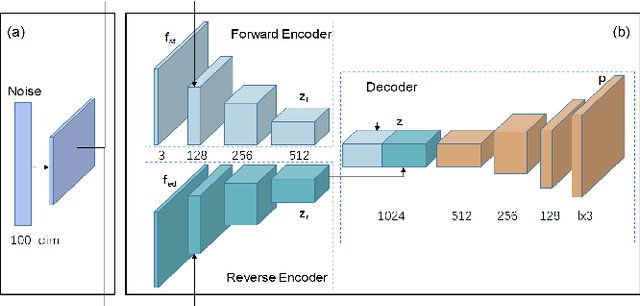
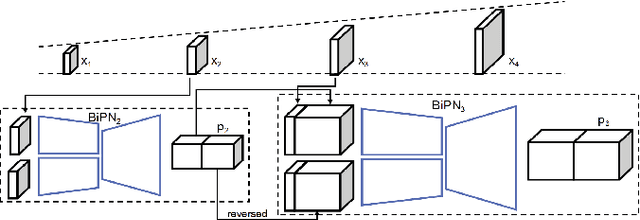

This paper considers the challenging task of long-term video interpolation. Unlike most existing methods that only generate few intermediate frames between existing adjacent ones, we attempt to speculate or imagine the procedure of an episode and further generate multiple frames between two non-consecutive frames in videos. In this paper, we present a novel deep architecture called bidirectional predictive network (BiPN) that predicts intermediate frames from two opposite directions. The bidirectional architecture allows the model to learn scene transformation with time as well as generate longer video sequences. Besides, our model can be extended to predict multiple possible procedures by sampling different noise vectors. A joint loss composed of clues in image and feature spaces and adversarial loss is designed to train our model. We demonstrate the advantages of BiPN on two benchmarks Moving 2D Shapes and UCF101 and report competitive results to recent approaches.