 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Imagination from a Single Image with Transformation Generation
Paper and Code
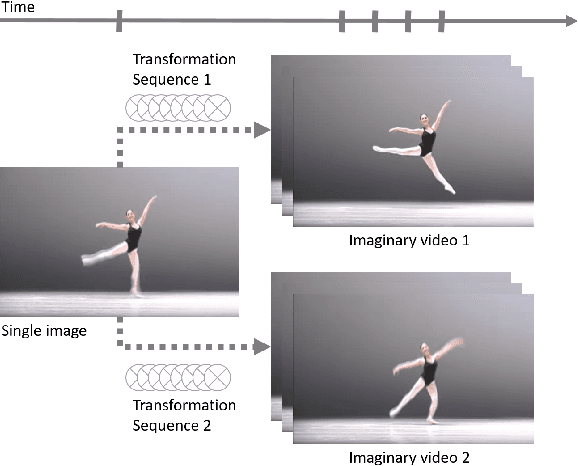

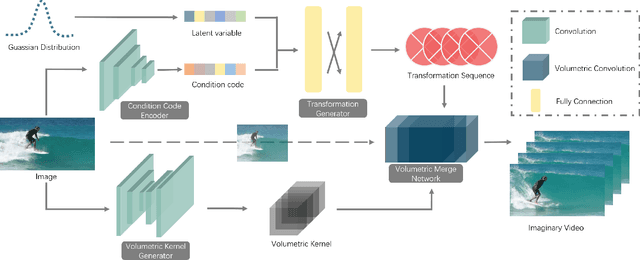
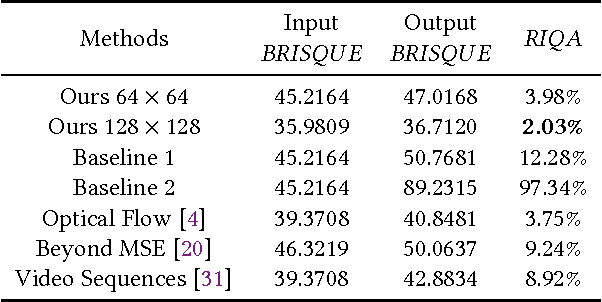
In this work, we focus on a challenging task: synthesizing multiple imaginary videos given a single image. Major problems come from high dimensionality of pixel space and the ambiguity of potential motions. To overcome those problems, we propose a new framework that produce imaginary videos by transformation generation. The generated transformations are applied to the original image in a novel volumetric merge network to reconstruct frames in imaginary video. Through sampling different latent variables, our method can output different imaginary video samples. The framework is trained in an adversarial way with unsupervised learning. For evaluation, we propose a new assessment metric $RIQA$. In experiments, we test on 3 datasets varying from synthetic data to natural scene. Our framework achieves promising performance in image quality assessment. The visual inspection indicates that it can successfully generate diverse five-frame videos in acceptable perceptual quality.