 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Imagination from a Single Image with Transformation Generation
Jun 15, 2017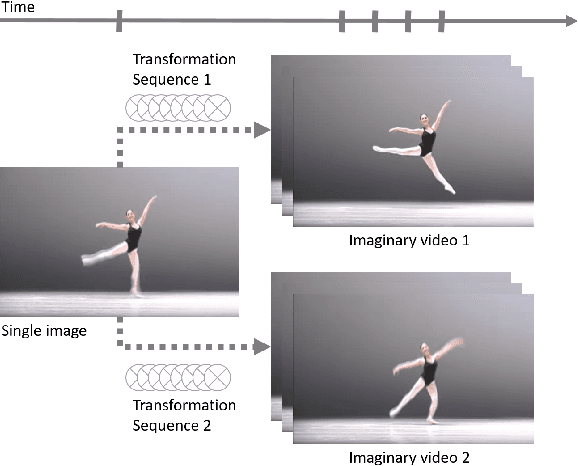

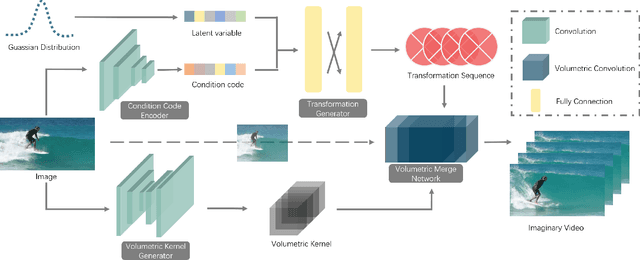
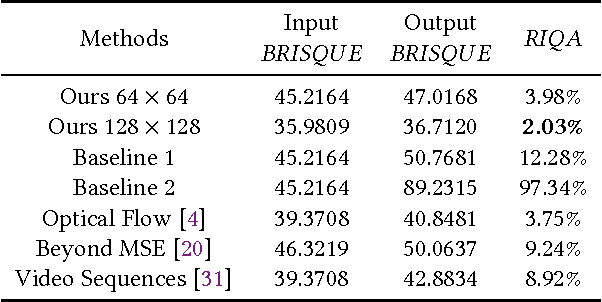
In this work, we focus on a challenging task: synthesizing multiple imaginary videos given a single image. Major problems come from high dimensionality of pixel space and the ambiguity of potential motions. To overcome those problems, we propose a new framework that produce imaginary videos by transformation generation. The generated transformations are applied to the original image in a novel volumetric merge network to reconstruct frames in imaginary video. Through sampling different latent variables, our method can output different imaginary video samples. The framework is trained in an adversarial way with unsupervised learning. For evaluation, we propose a new assessment metric $RIQA$. In experiments, we test on 3 datasets varying from synthetic data to natural scene. Our framework achieves promising performance in image quality assessment. The visual inspection indicates that it can successfully generate diverse five-frame videos in acceptable perceptual quality.
Long-Term Video Interpolation with Bidirectional Predictive Network
Jun 13, 2017
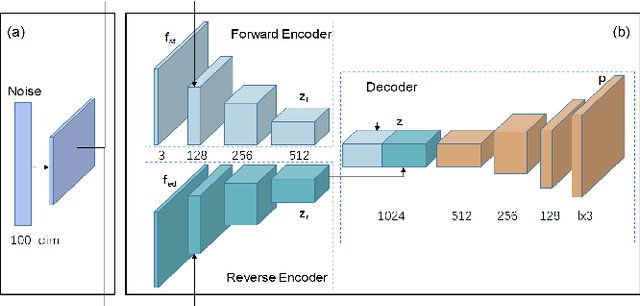
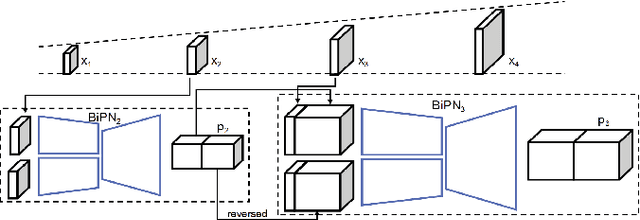

This paper considers the challenging task of long-term video interpolation. Unlike most existing methods that only generate few intermediate frames between existing adjacent ones, we attempt to speculate or imagine the procedure of an episode and further generate multiple frames between two non-consecutive frames in videos. In this paper, we present a novel deep architecture called bidirectional predictive network (BiPN) that predicts intermediate frames from two opposite directions. The bidirectional architecture allows the model to learn scene transformation with time as well as generate longer video sequences. Besides, our model can be extended to predict multiple possible procedures by sampling different noise vectors. A joint loss composed of clues in image and feature spaces and adversarial loss is designed to train our model. We demonstrate the advantages of BiPN on two benchmarks Moving 2D Shapes and UCF101 and report competitive results to recent approaches.