 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Listener: Continuous Generation of Listener's Head Motion Response in Dyadic Interactions
Sep 30, 2024



A key component of dyadic spoken interactions is the contextually relevant non-verbal gestures, such as head movements that reflect a listener's response to the interlocutor's speech. Although significant progress has been made in the context of generating co-speech gestures, generating listener's response has remained a challenge. We introduce the task of generating continuous head motion response of a listener in response to the speaker's speech in real time. To this end, we propose a graph-based end-to-end crossmodal model that takes interlocutor's speech audio as input and directly generates head pose angles (roll, pitch, yaw) of the listener in real time. Different from previous work, our approach is completely data-driven, does not require manual annotations or oversimplify head motion to merely nods and shakes. Extensive evaluation on the dyadic interaction sessions on the IEMOCAP dataset shows that our model produces a low overall error (4.5 degrees) and a high frame rate, thereby indicating its deployability in real-world human-robot interaction systems. Our code is available at - https://github.com/bigzen/Active-Listener
Speech-Gesture Mapping and Engagement Evaluation in Human Robot Interaction
Dec 09, 2018
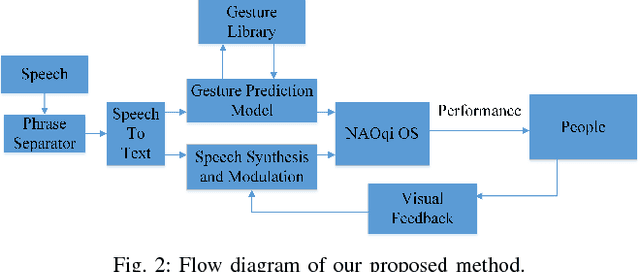
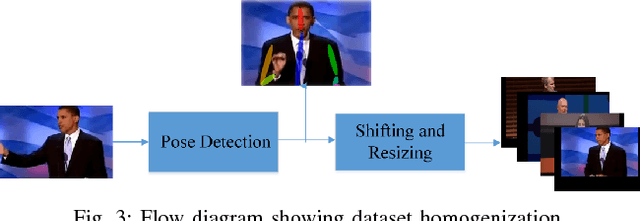

A robot needs contextual awareness, effective speech production and complementing non-verbal gestures for successful communication in society. In this paper, we present our end-to-end system that tries to enhance the effectiveness of non-verbal gestures. For achieving this, we identified prominently used gestures in performances by TED speakers and mapped them to their corresponding speech context and modulated speech based upon the attention of the listener. The proposed method utilized Convolutional Pose Machine [4] to detect the human gesture. Dominant gestures of TED speakers were used for learning the gesture-to-speech mapping. The speeches by them were used for training the model. We also evaluated the engagement of the robot with people by conducting a social survey. The effectiveness of the performance was monitored by the robot and it self-improvised its speech pattern on the basis of the attention level of the audience, which was calculated using visual feedback from the camera. The effectiveness of interaction as well as the decisions made during improvisation was further evaluated based on the head-pose detection and interaction survey.